Embed Size (px)
Citation preview

MPH F 2009
© Judith L. Jacobsen 1
Deskriptiv Statitik
Judith L. Jacobsen, PhD.http://staff.pubhealth.ku.dk/~lts/basal09_1/
F 2009
Kursus formål
• Planlægning af studier – selve indsamlingen af data, – opstilling af statistiske hypoteser
– valg af tests og udførsel enkle analyser
• Faglig fortolkning af statistiske resultater• Normalfordelingen & binomial fordelingen
• Frekvens og antals tabeller
F 2009
Deskriptiv Statistik
• Typer af data
• Tabeller
• Grafik
• Summary statistik
• Forstå variation i observerede værdier
• Forskellige datatyper, skala og deres fordeling

MPH F 2009
© Judith L. Jacobsen 2
F 2009
Undersøg ALTID Data
�Plot ALLE observationerne
�STUDER dine plots
�Analyser dine data
F 2009
Handler om
Ud fra tal – data: • at kunne udtale sig om aspekter af virkeligheden• (lægevidenskabelige/biologiske problemstillinger)• (Ikke “officiel” statistik, statistikproduktion)
Ud fra stikprøve:1. Deskriptiv statistik:beskrive variation i population2. Statistisk inferens (cf. infer )drage konklusioner om ukendte størrelser, parametre, knyttet til populationen.
F 2009
Hvad er Statistik
Generalisere (gøre inferens) omkring en population ved at studere et udsnit fra denne
Population
UdsnitInferens

MPH F 2009
© Judith L. Jacobsen 3
F 2009
Eksempel
PopulationAlle voksne med mistanke om CHD ud fra nogle observationer
ForsøgUdsnit af 60 voksne med mistanke om CHD Afprøvning af en intervention
Statistik går ud på at sige noget om, hvor tæt vores observationer er på de resultater vi ville have, hvis vi havde observeret alle voksne med CHD
F 2009
Emner
Nøgleord
• Datareduktion
• Datapræsentation
• Statistiske modeller
Værktøj
• Matematik
• Sandsynlighedsregning
• Grafik
og sund fornuft!
F 2009
Data typer I
• Kvalitativ♀ ♂
• Kvantitativ
• Binære
�Kategorisk Subjektiv
�Numerisk, målbar
Objektiv�Enten – Eller
Død – levende
0–1
1 2 3
Præcision

MPH F 2009
© Judith L. Jacobsen 4
F 2009
Data typer II
Kvalitative
• Beskrivelse– Subjektivt– Objektivt ♀ ♂
• Nominal– Benævnte kategorier
• Ordinal– Ordnede kategorier
Kvantitative
• Målinger– Kontinuerte– Diskrete
• Interval– Specifik afstand
• Ratio– Samme reference
F 2009
Interval & Ratio
• Interval skala Specifik distanceTemperaturArbitrær reference, Celcius og Farenheit, man kan ikke sige at 20° er dobbelt såvarmt som 10°
• Ratio skala Samme referenceAlderRatio har samme reference – 50 år er dobbelt så gammel som 25 år
F 2009
Kategoriske Data
To kategorier (dikotom/binær):
• Mand/kvinde• Gravid/ikke gravid
• Gift/ugift
• Ryger/ikke ryger
Flere end to:
• Nominal: Gift / ugift / fraskilt / enke(mand)
• Ordinal:
minimal / moderat / alvorlig / uudholdelig
smerte

MPH F 2009
© Judith L. Jacobsen 5
F 2009
Kontinuerte Data
• Måling på en sammen-hængende skala
• I praksis afrundede tal
• Variable der antager “mange værdier”
• Ofte ’noget med’normalfordelingen
Eksempler
• Højde
• Vægt
• Serum-kolesterol
• Blodtryk
F 2009
Diskrete Numeriske Data
Tælletal
• Antal børn i en familie• Antal metastaser/celler/bakteriekolonier
• Flydende grænser mellem diskrete numeriske og ordinale kategoriske data.
OBS: Ofte meningsløst at behandle ordinale data som om de var numeriske.
Gennemsnitlig socialklasse eller cancerstadium??
F 2009
Censurerede data
Typisk overlevelsesdata• For nogen data vides kun om de er større end
en vis værdi. For andre kendes værdien.• “Patienten var i live ved sidste follow-up / pr.
1.jan. 1997”
NB: der er også trunkerede data hvor man slet ikke har data hvis de er mindre/større end en vis værdi:
• Tid til diagnose blandt patienter med symptomstart i 1995, fx.

MPH F 2009
© Judith L. Jacobsen 6
F 2009
Beaufort Vindskala
Elastisk skalaOrdinalVel defineret
Ret høje, lange bølger -bølgekammen brydes til skumsprøjt
Kviste og grene brækkes af - besværligt at gå mod vinden
Hård kuling62 - 7434-4017-208
Høje bølger, hvor toppen vælter over - skumsprøjt kan påvirke sigten
Store grene knækkes -tagsten blæser ned
Stormende kuling75 - 8841-4721-249
Meget høje bølger - næsten hvid overflade - skumsprøjt påvirker udsigten
Træer rives op med rode -betydelige skader på huse
Storm89 -10248-5525-2810
Umådeligt høje bølger - havet dækket af hvide skumflager -sigten forringet
Talrige ødelæggelserStærk storm103-11756-6329-3211
Luften fyldt med skum, der forringer sigten væsentligt
Voldsomme ødelæggelserOrkan118 ->63>3212
Observationer på vandObservationer på landBetegnelsekm/tKnobm/sBeaufort
Admiral Francis Beaufort
Oversigt over Teknikker
Kategoriskeog Kontinuerte
KontinuerteKategoriskeDikotome
KovariaterRespons
Kovarians analyse
Multipel regression
Varians Analyse
En- / to-sidet
T-test
Parret / uparret
Normal
Fordeling
Modeller for gentagne målingerVarians komponentModeller
KorreleredeNormalt ford.
Cox regressionLog-rank testCensorededata
Robust multipel
regression
Kruskal - Wallis
- Friedman
Mann – Whitney
Wilcon sign rank
Kontinuerte
Vanskeligt, e.g. proportional odds modelsOrdinale
Gen. Logistisk regressionKontingens tabeller /Kategoriske
Logistisk regression2 x 2-tabellerDikotome test−2χ
test−2χ
F 2009
Overblik
• Interval & ratio data indeholder mere information end
ordinal data, som indeholder mere information end
nominal data• Man kan altid gå fra kontinuert – diskret –
ordinal – nominalMen aldrig den anden vej!

MPH F 2009
© Judith L. Jacobsen 7
F 2009
Beskrivelse af Data
Nominal
• Frekvenser• Tabellering
• Tærte diagram
Ordinal
• Frekvenser
• Stolpe diagram
Kontinuerte
• Middel, median, Sd, fraktiler
• Scatter plot
Diskret
• Median, min, max• Stolpe diagram
F 2009
Beskrivelse Kategoriske Data
• Stolpediagrammer (barplots)
F 2009
Tabeller
Absolutte hyppigheder/frekvenser (antal)
• Kejsersnit og skostørrelse:
35122 35 42 48 54 150Total
43308
5 7 6 7 8 1017 28 36 41 46 140
YesNo
Total<4 4 4½ 5 5½ 6+Section

MPH F 2009
© Judith L. Jacobsen 8
F 2009
Tabeller - i procent
Kejsersnit og skostørrelse:
• Relative frekvenser (i %)
100100 100 100 100 100 100Total
12.387.7
22.7 20.0 14.3 14.6 14.8 6.777.3 80.0 85.7 85.4 85.2 93.3
YesNo
Total<4 4 4½ 5 5½ 6+Section
• Fordel: direkte sammenlignelighed
• Ulempe: mister de faktiske antal
F 2009
Procenter – ’den anden vej’
Kejsersnit og skostørrelse:
• Relative frekvenser (i %)
1006.3 10.0 12.0 13.7 15.4 42.7Total
100100
11.6 16.3 14.0 16.3 18.6 23.35.5 9.1 11.7 13.3 14.9 45.5
YesNo
Total<4 4 4½ 5 5½ 6+Section
• Dette siger noget om fodstørrelse
– og ikke så meget om hyppighed af kejsersnit
F 2009
Mere om Frekvenser
• Trafikofre i the London Borough of Harrow 1985 (65 med ukendt alder udeladt)
Remark: Her kommer grupperne fra ’kontinuerte’observationer
• Så et ’bar chart’ af frekvenserne er mere som et histogram...
Total815
0-4 5-9 10-15 16 17 18-19 20-24 25-59 60+28 46 58 20 31 64 149 316 103
5.4 9.2 11.6 20.0 31.0 32.0 29.8 9.0 5.2
AlderFrekv.Fr./ år

MPH F 2009
© Judith L. Jacobsen 9
F 2009
Ukorrekt: (uens interval bredde)
• højden af stolper = absolutte frekvenser
F 2009
Korrekt: (uens interval bredde)
• højden af stolper = antal ofre pr år (alder)
F 2009
Grupperinger
1,0-1,5 1,5-2,0 2,0-2,5 2,5-3,0 3,0-3,5 3,5-4,0
1,0-1,5 1,5-2,0 2,0-2,5 2,5-3,0 3,0-3,5 3,5-4,01,0-1,5 1,5-2,0 2,0-2,5 2,5-3,0 3,0-3,5 3,5-4,0
A B
Histogrammer
• Overvej om databør deles op

MPH F 2009
© Judith L. Jacobsen 10
F 2009
Grupperinger II
R WGRUPPE$
100
200
300
400V
alue
AGE(1)AGE(2)AGE(3)AGE(4)
AGE(1)AGE(2)AGE(3)AGE(4)Trial
100
200
300
400
Mea
sure
RW
GRUPPE$
F 2009
Eksempel – Kvantitative Data
• PI max
F 2009
Beskrivelse – Kvantitative Variable
Graphs:
• Histogram• Probability plot
• QQ plot
• Box plot
• Graph/Histogram
pimax i Analysis

MPH F 2009
© Judith L. Jacobsen 11
F 2009
Histogram – tæthed
F 2009
Sandsynligheder – Tæthed• Hvad betyder sandsynligheder, f.eks. for PImax?• Her: hver enkelt værdi sandsynlighed = 0 for at indtræffe
(fordi der i princippet er ∞ mange mulige udfald)• Sandsynlighedstætheder ,
sandsynligheden for et interval = arealet under kurven
F 2009
Diagrammer
• Histogram
• Frekvens fordeling
• Box plot
• Scatter plot

MPH F 2009
© Judith L. Jacobsen 12
F 2009
Normalfordelingstætheder
µ middelforventet
σ standard afvigelse
F 2009
Histogram
med overlejret
Normalfordeling
• Graph/Histogram• pimax i Analysis
• klik Fit og afkrydsNormal Parameters
F 2009
Gennemsnit
Eksempel:• Indlæggelsestider: 5,5,5,7,10,16,106 dage• Gennemsnit: 154/7=22 dage
Repræsentativt for hvad??• Hvis omkostninger er proportionale med indlæggelsestiden, er
det måske gennemsnittet, der er interessant
Et mål for centrum i en fordelingKan opfattes som lige-vægtspunkt – påvirkes af yderlige observationer

MPH F 2009
© Judith L. Jacobsen 13
F 2009
Skal vi skræmme modstanderne
Ved at give vores
middelhøjde?
Eller berolige
dem ved at give
median højden?
F 2009
Estimatorer for Beliggenhed
• Middel Den aritmetiske middelværdi for et set observationer. Misvisende når baseret på’skewed’ data.
• Median Den værdi, i et set ordnede observationer, som deler data i to ens dele. God til ’skewed’ data og relativ robust for ’outliere’.
• Modus Den oftest observerede værdi i et set observationer (‘typisk værdi‘). Bruges bla. når ovennævnte ikke slår til
F 2009
Estimatorer for Spredning
• Range Forskellen mellem max. og min. i et set observationer. Ikke anbefalet til at måle spredning pga. sensitiviteten til outliers. Dens størrelse øger med stikprøve størrelsen.
• Varians ‘Gennemsnittet’ af observation-ernes kvadrerede afvigelser fra middel-værdien. Standard afvigelse SD = kvadrat-roden af variansen.
• Standard fejl SD for stikprøve fordelingen af en statistik. SE = s / n½

MPH F 2009
© Judith L. Jacobsen 14
F 2009
Deskriptive Mål
• Udregning af basale mål
• Middel: Varians:
• Std.afv.:
Medianen (50%) er den midterste værdi når data
er sorteret efter størrelse
n
xx
∑=)1(
)( 22
−−
= ∑n
xxs
2ss =
F 2009
Hvornår bruges hvad?
Beliggenhed
• Formen på data – Skewed: Median– Symmetrisk: Middel
• Type data– Nominale data: Modus– Ordinale data: Median– Kontinuerte Data:
Middel
Skala
• Formen på dataGir ingen mening at beregne SD for skewed data
Brug kvartiler og fraktiler i stedet
F 2009
Fraktiler og kvartiler
Et mål for variabilitet
• Viser skævheder
• 50% = medianen
• 25% og 75%
Fraktiler
• Frekvens fordelingS T
METODE$
500
1000
1500
2000
ST
YR
KE

MPH F 2009
© Judith L. Jacobsen 15
F 2009
Summary Statistik i SAS
Statistics/Descriptive/Summary Statistics• pimax i Analysis i Statistics afkrydses:• Mean, Standard Deviation, Minimum, Maximum,
Median & Number of Observations
The MEANS Procedure
Analysis Variable : pimax
Mean Std Dev Minimum Maximum Median N
---------------------------------------------------------------------------------------------------92.60 24.9215436 40.00 150.00 95.00 25
---------------------------------------------------------------------------------------------------
F 2009
Normalfordeling – God?
Hvordan ses, om normalfordelingen er en god beskrivelse?
• Computersimulation af 150 observationer fra samme normalfordeling, gentages 9 gange.
• Nogle ser ’ikke ret normalfordelte’ ud!
• Ganske store afvigelser kan tolereres (i visse sammenhænge)
specielt når de ikke er for systematiske
F 2009
Tilfældigt udtrukket 150 obs fra en normalfordeling
mid
del =
115
og s
pred
ning
= 1
0

MPH F 2009
© Judith L. Jacobsen 16
⇒ Samme forskel i middelværdi, men ikke lige vigtig
Varians er vigtig
F 2009
Test af Normalitet i SAS Analyst
Statistics/
Descriptive/Distributions
→ klik: Fit/Normal
Parameters
blandt meget
andet output fås:
The UNIVARIATE Procedure
Fitted Distribution for pimax
Parameters for Normal Distribution
Parameter Symbol Estimate
Mean Mu 92.6
Std Dev Sigma 24.92154
Goodness-of-Fit Tests for Normal Distribution
Test --- Statistic --- --- p Value ---
Kolmogorov-Smirnov D 0.12002682 Pr > D >0.150
Cramer-von Mises W-Sq 0.05671455 Pr > W-Sq >0.250
Anderson-Darling A-Sq 0.35232007 Pr > A-Sq >0.250
------- Quantile ------
Percent Observed Estimated
1.0 40.0000 34.6238
5.0 45.0000 51.6077
10.0 70.0000 60.6618
25.0 75.0000 75.7907
50.0 95.0000 92.6000
75.0 110.0000 109.4093
90.0 125.0000 124.5382
95.0 130.0000 133.5923
99.0 150.0000 150.5762
Quantiles – Normal Fordeling

MPH F 2009
© Judith L. Jacobsen 17
F 2009
Fraktiler
• (PImax-eksempel) Data i rækkefølge:
Median: Midterste observation, 50%-fraktil: 95
Kvartiler (25% og 75% fraktiler): 75, 110.
25
150
24
130
23
125
22
120
21
110
I
pimax
20
110
19
110
18
100
17
100
16
100
15
9514
95
13
95
12
95
11
85
I
pimax
1080
9
80
8
80
7
75
6
75
5
75
4
75
3
70
2
45
1
40
I
pimax
F 2009
Fraktildiagram
Graphs/Probability
Plot:
Hvis data er normalfordelt, skal
fraktildiagrammet ligne en ret linie
F 2009
Graph/Box Plot
i Display skiftes
til Schematic

MPH F 2009
© Judith L. Jacobsen 18
F 2009
Hvis Fordelingen er Skæv
eller afviger tydeligt fra N-Formalfordelingen:
• gennemsnit og spredning bør ikke angivesI stedet:
• fraktiler– median– Inter-quartile range, IQR
intervallet mellem 25% og 75% fraktil
• range
Om muligt bør fordelingen illustreres grafisk!
Alternativ: Transformer til normalitet
For små materialer angives• median• range
F 2009
Hvorfor Normalfordelingen?
Ofte en rimelig approksimation• Evt. efter transformation
med logaritme, kvadratrod, invers,...
Central grænseværdisætning:• Summen af et stort antal variable ligner
efterhånden en Normalfordeling(sum af N-fordelinger er igen en N-fordeling).
Rimelig let at arbejde med, fordi standard programmel er udviklet for Normalfordelingen
F 2009
Højder
MPH F 2009
© Judith L. Jacobsen 19
F 2009
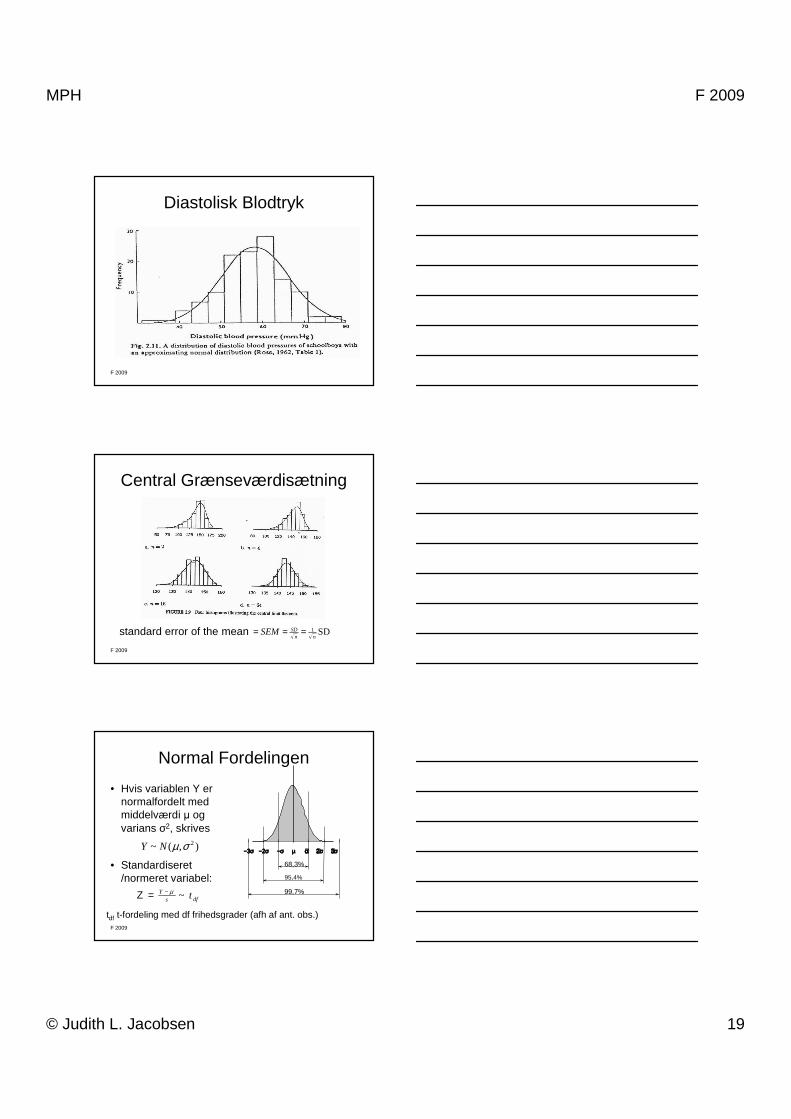
Diastolisk Blodtryk
F 2009
Central Grænseværdisætning
standard error of the mean SD1nn
SDSEM ===
F 2009
Normal Fordelingen
• Hvis variablen Y er normalfordelt med middelværdi µ og varians σ2, skrives
• Standardiseret /normeret variabel:
−−−−3σ 3σ 3σ 3σ −−−−2σ 2σ 2σ 2σ −−−−σ µ +σ +2σ +3σσ µ +σ +2σ +3σσ µ +σ +2σ +3σσ µ +σ +2σ +3σ
68,3%
95,4%
99,7%
),(~ 2σµNY
dfsY t~µ−=Ζ
tdf t-fordeling med df frihedsgrader (afh af ant. obs.)

MPH F 2009
© Judith L. Jacobsen 20
F 2009
N-Ford. – Middel & Varians
µ = 10 µ = 24
σ = 1
σ = 2
F 2009
EksempelFra et stort materiale har vi fundet gennemsnitlig Se-albumin på 34.46 (g/l) og empirisk varians på 5.842 (g/l)2
• Hvis vi antager Se-albumin er normalfordelt med middelværdi 34.46 g/l og spredning 5.84 g/l, hvad er sandsynligheden for at en tilfældigt udvalgt person har en værdi over 42.0 g/l?
Hvor mange standardafvigelser er 42.0 fra 34.46?
Tabelopslag i standardnormalfordeling –eller computer: P = 0.0985 ≈ 10%
29.184.546.3442 =−
F 2009
Normalområder
der omslutter 95% af normale observationer:• nedre grænse: 2 ½ % fraktil• øvre grænse: 97 ½ % fraktil• Hvis fordelingen kan beskrives ved en normalfordeling
N(µ,σ2) kan disse fraktiler direkte udtrykkes som2 ½ % fraktil: µ − 1.96 ≈ y − 1.96 s
97 ½ % fraktil: µ + 1.96 ≈ y + 1.96 s• og normalområdet udregnes derfor som
hvis standard N-fordeling
)2,2(2 sysysy ×+×−×± =
96.1975.0025.0 ≈=− zz

MPH F 2009
© Judith L. Jacobsen 21
F 2009
Skæve fordelinger
- 0.47g/l0.80g/l
Standard deviation
s = SD
Gennemsnit
)/74.1 ,/14.0()2 ,2( llyy ggss −=++
F 2009
Transformation
0.238- 0.158
SDmiddel
På log10 skala:
)32.0 ,63.0(238.0 2158.0 −=×±−
08.210
23.010
695.010
:Antilogs
32.0
0.63
158.0
=
=−=−
Bedre grænser: (0.23, 2.08)





























