Embed Size (px)
Citation preview

Data Mining - Open Source vs. Oracle ein Erfahrungsbericht
Prof. Dr. Reinhold von Schwerin
Projektgruppe Data Mining1 des Masterstudiengangs Informationssysteme Hochschule Ulm
Schlüsselworte: Open Source, Oracle Data Miner, KNIME, Data Mining Cup 2009. Zusammenfassung Der vorliegende Bericht untersucht anhand einer praktischen Aufgabenstellung die Stärken und Schwächen der Data Mining Tools KNIME und Oracle Data Miner. Hierfür werden Kri-terien auf Basis des CRISP-DM Prozesses abgeleitet und gewichtet. Im Ergebnis zeigt sich, dass beide Tools unterschiedliche Schwerpunkte haben und in einigen Kategorien besondere Stärken aufweisen, während in anderen Kategorien noch Verbesserungspotenzial steckt. Einleitung Der vorliegende Bericht stellt Erfahrungen mit dem Oracle Data Miner 11g und dem Open Source Tool KNIME gegenüber. Dabei wird untersucht, wie sich beide Tools in Hinsicht auf verschieden definierte Kriterien bei der Umsetzung typischer Data Mining Aufgaben verhal-ten. Die Untersuchungen waren Teil einer Projektarbeit im Rahmen des Masterstudiengangs Informationssysteme der Hochschule Ulm. Um die Vergleichbarkeit und die Umsetzbarkeit zu gewährleisten wurde die diesjährige Auf-gabe des Data Mining Cup2 als geeignetes Testszenario ausgewählt. Die daraus gewonnenen Erkenntnisse sollen auch bei der Auswahl geeigneter Werkzeuge für zukünftige Projekte aus dem Bereich Data Mining dienen. Aufgabenstellung Data Mining Cup 2009 Der Data Mining Cup ist ein internationaler studentischer Wettbewerb der seit dem Jahr 2000 von der prudsys AG, einem Hersteller von Analysesoftware, angeboten wird. Der Inhalt der Aufgaben bezieht sich dabei auf Fragestellungen betriebswirtschaftlicher Optimierungsmög-lichkeiten. Für die Bereitstellung realitätsnaher Datensätze werden regelmäßig Aufgaben aus der Praxis durch Kooperationspartner bereitgestellt. Die Aufgabe beim diesjährigen Data Mi-ning Cup (DMC 2009) kam aus dem Bereich des Buchgroßhandels. Die Daten wurden von der Libri GmbH zur Verfügung gestellt. Ziel ist mit Hilfe von Trainingsdaten eine möglichst
1 Mitglieder: D. Adam, K. Böll, S. Funk, F. Knittel, F. Langenbruch, S. Nagel, H. Weissbach 2 http://www.data-mining-cup.com
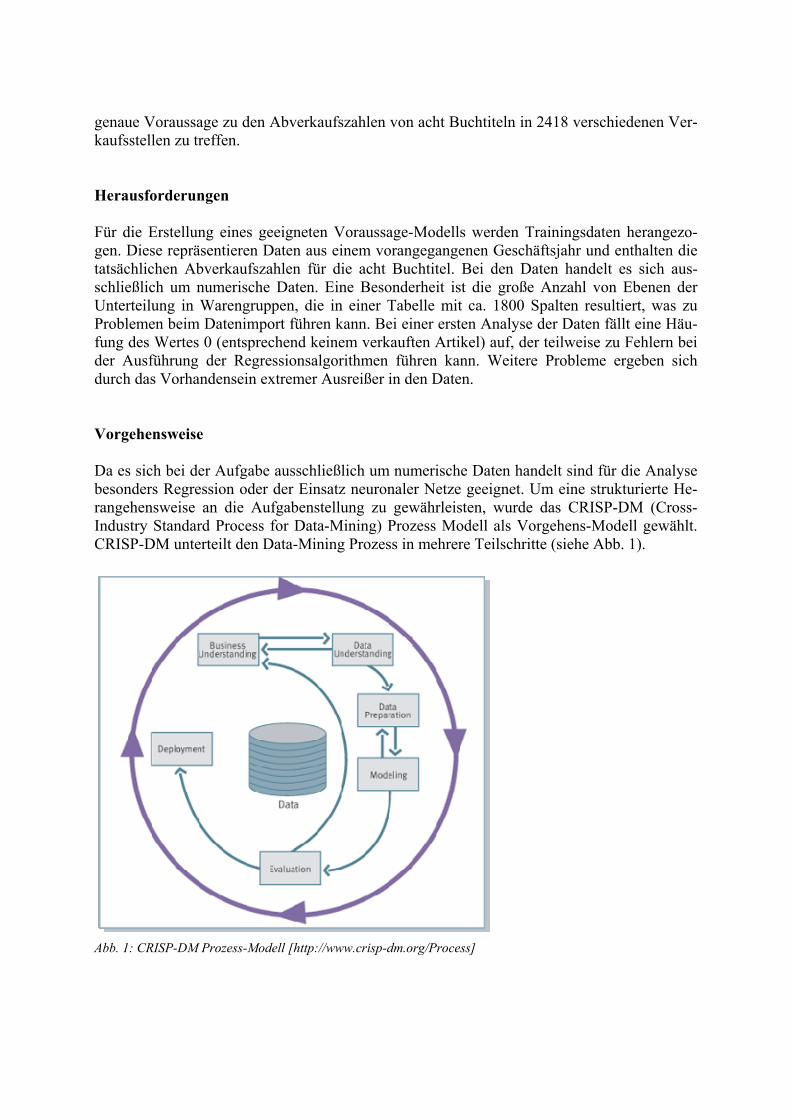
genaue Voraussage zu den Abverkaufszahlen von acht Buchtiteln in 2418 verschiedenen Ver-kaufsstellen zu treffen. Herausforderungen Für die Erstellung eines geeigneten Voraussage-Modells werden Trainingsdaten herangezo-gen. Diese repräsentieren Daten aus einem vorangegangenen Geschäftsjahr und enthalten die tatsächlichen Abverkaufszahlen für die acht Buchtitel. Bei den Daten handelt es sich aus-schließlich um numerische Daten. Eine Besonderheit ist die große Anzahl von Ebenen der Unterteilung in Warengruppen, die in einer Tabelle mit ca. 1800 Spalten resultiert, was zu Problemen beim Datenimport führen kann. Bei einer ersten Analyse der Daten fällt eine Häu-fung des Wertes 0 (entsprechend keinem verkauften Artikel) auf, der teilweise zu Fehlern bei der Ausführung der Regressionsalgorithmen führen kann. Weitere Probleme ergeben sich durch das Vorhandensein extremer Ausreißer in den Daten. Vorgehensweise Da es sich bei der Aufgabe ausschließlich um numerische Daten handelt sind für die Analyse besonders Regression oder der Einsatz neuronaler Netze geeignet. Um eine strukturierte He-rangehensweise an die Aufgabenstellung zu gewährleisten, wurde das CRISP-DM (Cross-Industry Standard Process for Data-Mining) Prozess Modell als Vorgehens-Modell gewählt. CRISP-DM unterteilt den Data-Mining Prozess in mehrere Teilschritte (siehe Abb. 1).
Abb. 1: CRISP-DM Prozess-Modell [http://www.crisp-dm.org/Process]

Der erste Schritt des CRISP-DM ist das Business Understanding. Es umfasst die Analyse der Problemstellung, damit diese richtig erfasst und gedeutet wird. Das Data Understanding soll die relevanten Daten identifizieren, um diese im nächsten Schritt aufzubereiten. Dabei sind besonders die Fragen nach der Behandlung von Ausreißern und die Verringerung der Spalten-anzahl für die Problemstellung des DMC 2009 von Bedeutung. Es ist dabei durchaus sinnvoll die Daten weiter zu aggregieren, im konkreten Fall also die Warengruppen weiter zusammen-zufassen. Die daraus resultierende Datenreduktion erleichtert den Umgang mit den Daten er-heblich. Evaluation Für die Bewertung wurden der Oracle 11gR1 Data Miner und KNIME Version 2.0.3 unter-sucht. Beide Werkzeuge wurden während der Umsetzung der gestellten Aufgabe anhand einer gewichteten Kriterienliste bewertet. Die Ergebnisse werden abschließend in Punktwerte um-gesetzt und miteinander verglichen. Evaluationskriterien Die Kategorien für die Evaluation wurden in Anlehnung an CRISP-DM ausgewählt. Zusätz-lich werden Kriterien der Kategorie Usability beurteilt. Insgesamt wurden 18 Kriterien defi-niert und entsprechend ihrer Relevanz auf einer Skala von eins (weniger wichtig) bis fünf (sehr wichtig) gewichtet. Jedes Kriterium wird für jede zu evaluierende Software mit einem Wert zwischen eins und zehn bewertet. Dabei repräsentiert die eins die schlechteste, die Ziffer zehn die bestmögliche Bewertung. Nachfolgend wird näher auf die Kategorien eingegangen, in Klammern steht jeweils die Gewichtung. Damit ist es dem Leser möglich, bei ggf. anderer eigener Priorisierung der Kriterien u.U. zu einem anderen Ergebnis in der Bewertung zu ge-langen. Die Kategorie Data Understanding enthält dabei die Kriterien Visualisierung, Datenanalyse und Aufbereitung. Für die Visualisierung (5) ist es wichtig, dass ausreichend Möglichkeiten für die graphische Darstellung der Daten vorhanden sind. Für die Datenanalyse (4) sollten ausreichend Funktionen und Methoden bereitgestellt werden. Die Aufbereitung (3) ist weniger wichtig als die ersten beiden Kriterien in dieser Kategorie. Es sollte aber möglich sein, inner-halb der Software die Daten zu bearbeiten. Die Kategorie Data Preparation enthält die Punkte Datenimport, Transformation und Daten-qualität. Der Datenimport (3) sollte gängige Dateiformate unterstützen, auch größere Daten-mengen sollten für den Datenimport kein Problem darstellen. Das Kriterium Transformation (3) legt fest wie gut sich das Tool eignet, Daten innerhalb der Software zu transformieren. Die Datenqualität (3) sollte durch die Software bewertet und fehlerhafte oder unvollständige Da-ten erkannt und ausgebessert bzw. berechnet werden können. Die Kategorie Modeling enthält die Kriterien Assoziationsanalyse, Klassifikation, Regression und Segmentierung. Die Punkte Assoziationsanalyse (5), Klassifikation (5), Regression (5) und Segmentierung (5) bewerten die zur Verfügung stehenden Algorithmen zur Abhängig-keitsentdeckung, Klassifikation, Regressionsanalyse und des Clustering. Diese Kriterien sind die wichtigsten in der gesamten Evaluierung, da ohne die saubere Unterstützung der Algo-

rithmen keine Ergebnisse erzielt werden können. Insbesondere gibt es für fehlende Algorith-men Abzüge in der Punktbewertung. Die Kategorie Evaluation beinhaltet das Kriterium Modelltest. Der Modelltest (4) gibt an, mit welchen Ergebnissen und Metriken die Ergebnisse aus der Modellierung überprüft werden können. Die Kategorie Deployment enthält die Kriterien Datenexport, Reporting, Schnittstellen und Prozessintegration. Beim Datenexport (2) werden die Formatvielfalt und die Korrektheit des Exports bewertet. Das Reporting (4) stellt Möglichkeiten für den automatischen Export zur Verfügung und ist besonders wichtig, denn die Ergebnisvermittlung für die Anwender bzw. Entscheider ist unabdingbar für den Erfolg eines Data Mining Projekts. Das Kriterium Schnittstellen (3) bewertet, ob und in welcher Art und Weise Schnittstellen zu anderen Prog-rammen vorhanden sind. Der Punkt Prozessintegration (3) bewertet, ob die Software einfach in bestehende Prozesse eingebunden werden kann. Die Kategorie Usability (welche keine CRISP-DM-Phase darstellt) beinhaltet die Kriterien Installation, Bedienbarkeit sowie Hilfe und Support. Das Kriterium Installation (1) bewertet ob der Aufwand der Installation angemessen ist. Bei der Bedienbarkeit (4) geht es um die Frage einer intuitiv bedienbaren, logischen und übersichtlichen Benutzeroberfläche (GUI). Der administrative Aufwand sollte überschaubar sein. Das Kriterium Hilfe und Support (3) bewertet zum einen die Art und den Umfang der angeboten Dokumentation, zum anderen ob Tutorials oder Communities bestehen und von den Nutzern angenommen werden. Evaluation Oracle 11g Data Miner Der Oracle Data Miner ist eine graphische Benutzeroberfläche, um Data Mining auf Oracle Datenbanken durchzuführen. Data Mining ist prinzipiell seit Version 9iR2 möglich, den Data Miner gibt es seit Version 10gR1. Mit Hilfe von Wizards führt der Data Miner den Benutzer mit folgenden Schritten durch den Prozess (an CRISP-DM angelehnt): Datenaufbereitung, Data Mining, Evaluation des Modells und Modellbewertung. Unter anderem bietet der Data Miner die Lernmethoden Entscheidungsbäume, Support Vector Machine, Generalized linear model, Assoziationsregeln, K-means und Naive Bayes. Deswei-teren werden verschiedene Data Mining und Data Analysis Algorithmen zur Klassifikation, Vorhersage, Regression, Clustering, Feature Selection, Feature Extraction und der Erkennung von Anomalien bereitstellt. Zur Evaluierung wurde der Data Miner in der aktuellen Version 11.1.0.2 (Build 11659) in Verbindung mit Oracles Datenbank 11gR1 verwendet. Einen Eindruck vom Erscheinungsbild vermittelt Abbildung 2.
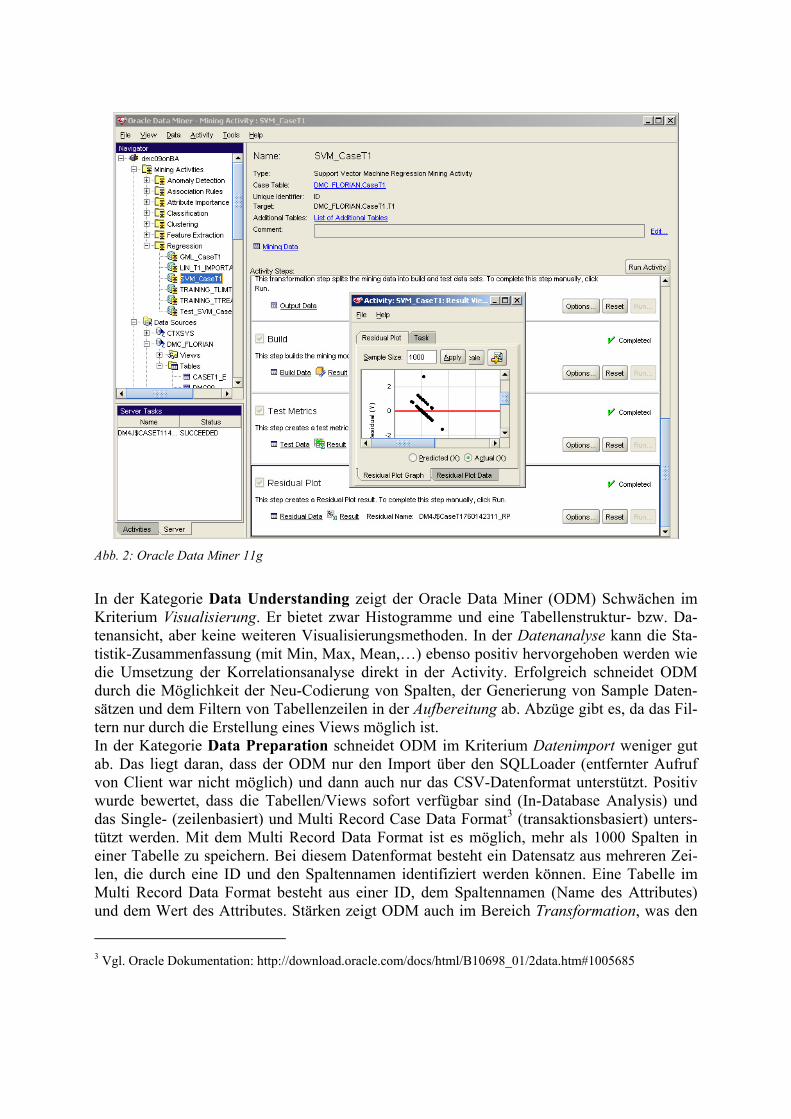
Abb. 2: Oracle Data Miner 11g
In der Kategorie Data Understanding zeigt der Oracle Data Miner (ODM) Schwächen im Kriterium Visualisierung. Er bietet zwar Histogramme und eine Tabellenstruktur- bzw. Da-tenansicht, aber keine weiteren Visualisierungsmethoden. In der Datenanalyse kann die Sta-tistik-Zusammenfassung (mit Min, Max, Mean,…) ebenso positiv hervorgehoben werden wie die Umsetzung der Korrelationsanalyse direkt in der Activity. Erfolgreich schneidet ODM durch die Möglichkeit der Neu-Codierung von Spalten, der Generierung von Sample Daten-sätzen und dem Filtern von Tabellenzeilen in der Aufbereitung ab. Abzüge gibt es, da das Fil-tern nur durch die Erstellung eines Views möglich ist. In der Kategorie Data Preparation schneidet ODM im Kriterium Datenimport weniger gut ab. Das liegt daran, dass der ODM nur den Import über den SQLLoader (entfernter Aufruf von Client war nicht möglich) und dann auch nur das CSV-Datenformat unterstützt. Positiv wurde bewertet, dass die Tabellen/Views sofort verfügbar sind (In-Database Analysis) und das Single- (zeilenbasiert) und Multi Record Case Data Format3 (transaktionsbasiert) unters-tützt werden. Mit dem Multi Record Data Format ist es möglich, mehr als 1000 Spalten in einer Tabelle zu speichern. Bei diesem Datenformat besteht ein Datensatz aus mehreren Zei-len, die durch eine ID und den Spaltennamen identifiziert werden können. Eine Tabelle im Multi Record Data Format besteht aus einer ID, dem Spaltennamen (Name des Attributes) und dem Wert des Attributes. Stärken zeigt ODM auch im Bereich Transformation, was den
3 Vgl. Oracle Dokumentation: http://download.oracle.com/docs/html/B10698_01/2data.htm#1005685

ausgereiften DB-Funktionen (Aggregation, Datentyptransformation,…) und der Möglichkeit von SQL-Abfragen (SQL-Worksheet) zuzuschreiben ist. Bei der Datenqualität kann die Be-handlung fehlender Werte über Missing Values Wizard und die explizite Ausreißerbehand-lung durch Outlier Treatment Transformation Wizard hervorgehoben werden. In der Kategorie Modeling zeigt ODM Schwächen bei der Assoziationsanalyse. Leider wird nur die Apriori-Analyse unterstützt, was zu Abzügen führt. In der Klassifikation bietet ODM dafür viele Möglichkeiten wie den Entscheidungsbaum, Support Vector Machine (SVM) und Logistic Regression (GLM), jedoch keine neuronalen Netze. Auch bei der Regression unters-tützt der Oracle Data Miner SVM/GLM (gerade die direkte Unterstützung von SVM wurde positiv bewertet) und zusätzlich noch lineare-/nicht lineare Regression. Leider war die Ver-wendung der GLM nicht möglich, da diese eine Fehlermeldung aus der Datenbank erzeugte, die sich mit dem ODM nicht lösen ließ. Bei der Segmentierung unterstützt ODM hierarchi-sche K-Means und hierarchische O-Cluster, aber z.B. keine Fuzzy-Methoden. Das Kriterium Modelltest in der Kategorie Evaluation zeigt die Vorteile des ODM. Mit dem Oracle Data Miner kann hierfür je Mining Algorithmus eine Testaktivität erstellt werden, da-bei ist es nach der Erstellung möglich, eine Testaktivität zu verändern und abgeändert zu speichern. Zudem besteht die Möglichkeit einen Residual Plot zu erstellen. Das die Testmet-riken nur auf der quadratischen Abweichung basieren schränkt eine höhere Bewertung ein. In der Kategorie Deployment bietet ODM beim Datenexport die Möglichkeit des Exports in ein CSV-Datenformat. Außerdem kann ein Backup der Tabellen/Views als SQL Skript erstellt werden, was hilfreich ist, da alle Tabellen/Views (und damit alle Prozessschritte) jederzeit in der DB verfügbar sind. Positiv bewertet wurde beim Reporting die direkte Anbindung an Oracle BI (Oracle BI EE, Dashboards) und die Oracle Reports, welche in folgenden Ausgabe-formaten erstellt werden können: HTML, RTF, PDF, XML, Excel und RDF. In den Kriterien Schnittstellen und Prozessintegration spielt ODM seine Stärken aus. Durch den In-Database Ansatz sind Schnittstellen für das Data Mining an sich nicht nötig. Dafür gibt es direkte An-bindungen an weitere BI-Applikationen (OLAP, Reporting). In der Prozessintegration wird positiv bewertet, dass Activities als PL/SQL Packages gespeichert und als SQL Skript (auto-matisiert) ausgeführt werden können. Das Kriterium Installation der Kategorie Usability wurde positiv bewertet, da das Oracle Da-ta Mining bei der Enterprise Edition der Oracle Datenbank direkt eingebunden ist. Leider ist die Verwendung des Oracle Data Miners nur in Verbindung mit einer Oracle Datenbank mög-lich. Im wichtigen Kriterium Bedienbarkeit kann die Benutzerführung durch Wizards und der Navigationsbaum hervorgehoben werden. Abzüge gibt es aber durch die fehlende Visualisie-rung der Prozesse (kein intuitiver Workflow) und die wenig aussagekräftigen Fehlermeldun-gen. Bei Hilfe und Support überzeugt ODM nicht. Die Dokumentation und auch Tutorials sind zwar online und in Form von PDFs vorhanden, aber oft ist ein bestimmtes Thema (z.B. Regression) auf mehrere Dokumente verteilt. Die in ODM integrierte Hilfe ist unzureichend.

Evaluation KNIME KNIME4 (Konstanz Information Miner) wurde von der Universität Konstanz entwickelt. Es steht unter zwei verschiedenen Lizenzmodellen zur Verfügung. Eine für die kommerzielle und eine für die nicht kommerzielle Nutzung. Im Falle einer nicht kommerziellen Nutzung ist KNIME kostenlos. KNIME bietet vielfältige Möglichkeiten zum Datenimport und zur Da-tenmanipulation. Es können Daten sowohl aus verschiedenen Dateiformaten als auch aus ver-schiedenen Datenbanken importiert werden. KNIME stellt seine Funktionen dabei über Kno-ten bereit. Um den Datenfluss abzubilden können diese miteinander verknüpft werden. KNI-ME enthielt am Anfang fast ausschließlich die WEKA Algorithmen, welche nach Java por-tiert wurden. Inzwischen enthält KNIME eine große Anzahl an Algorithmen zur Datenanalyse und wird kontinuierlich erweitert. Abbildung 3 zeigt die GUI von KNIME.
Abb. 3: KNIME
In der Kategorie Data Understanding zeigt KNIME Stärken bei der Visualisierung. Mit Box Plot und Conditional Box Plot, Line und Pie Charts, Scatter Plot und Scatter Matrix, Histog-rammen und dem Interactive Table View bietet es sehr viele Möglichkeiten an. Bei der Da-tenanalyse kann es mit einem Statistik-View (mit Minimum, Maximum, Mittelwert,…) und einer Korrelationsanalyse bzw. einem Korrelationsfilter punkten. Im Kriterium Aufbereitung bietet KNIME mit einem Filter für Tabellenzeilen und -spalten, das Zusammenfügen von Ta-bellen (Concatenate, Join) und das Transponieren von Matrizen ausreichend Methoden an.
4 http://www.knime.org

Beim Datenimport in der Kategorie Data Preparation kann KNIME sein Vorteile zeigen. Neben einem File Reader, der CSV-Dateien einlesen kann, bietet die Software einen Database Reader (über JDBC) und unterstützt den ARFF-Import (Attribute-Relation File Format) und den PMML-Import (Predictive Model Markup Language), letzteres befindet sich allerdings noch in der Beta-Phase. Abzüge gibt es, da das Einlesen von Excel-Dateien (.xls) nicht un-terstützt wird. Bei der Transformation wurde das Aufsplitten/Zusammenfügen/Vergleichen von (String-) Zellen positiv bewertet. Außerdem ist es möglich Spalten zu sortieren und Rei-hen zu aggregieren (Group By). Zusätzlich gibt es noch verschiedene Funktionen für String-Spalten. Um die Datenqualität zu erhöhen ist die Behandlung fehlender Werte möglich. Her-vorzuheben ist, dass die Daten über eine Rule Engine untersucht werden können (Program-mierung). Auch in der Kategorie Modeling schneidet KNIME gut ab. Der Datenstrom kann einfach über Verbindungen zwischen Funktionsbausteinen modelliert und gespeichert werden und ist beliebig durch den Benutzer anpassbar. Meta-Knoten ermöglichen weitere Sub-Workflows im Workflow (Strukturierung) und in jedem Workflow sind verschiedene Data Mining Methoden kombinierbar. Zusätzlich bietet KNIME mit der Cross-Validation (X-Validation) die Mög-lichkeit, Trainingsdaten zur Validierung automatisch zu Splitten und statistisch auszuwerten. Bei der Assoziationsanalyse wurde vor allem der Bitvector Generator für die Inputerzeugung positiv bewertet. Außerdem bietet KNIME den Association Rule Learner und vier weitere Methoden über das WEKA-Plugin an. Bei der Klassifikation unterstützt es Neuronale Netze (MLP, PNN), Entscheidungsbäume (J48 und eigener DT), Support Vector Machine und es sind ebenfalls weitere Methoden über das WEKA-Plugin verfügbar. Positiv für das Kriterium Regression wurden die zwei Regressionsmethoden (linear und polynomial) bewertet, die im Standardpaket enthalten sind. Auch hier sind weitere Regressionsmethoden über das WEKA-Plugin verfügbar. Stärken zeigt KNIME bei der Segmentierung. Neben k-Means, hierarchi-sche Clusterung und Self Organizing Tree Algorithm (SOTA) bietet es Fuzzy c-Means und viele weitere Methoden über das WEKA-Plugin. In der Kategorie Evaluation besticht KNIME im Kriterium Modelltest mit dem Lift Plot, der Cross-Validation und verschiedenen Visualisierungsmöglichkeiten für die Mining-Algorith-men. Eine weitere Stärke spielt KNIME im Datenexport der Kategorie Deployment aus. Es bietet einen Export in das CSV-Format (CSV-Writer), in das Excel-Format (XLS Writer) und direkt in eine Datenbank (über JDBC). Zusätzlich bietet KNIME einen ARFF Writer und einen PMML Writer (Beta) an. Abstriche gibt es im Bereich Reporting, da ein Export einer Work-flow-Dokumentation nicht vorhanden ist. Vorhanden ist nur ein BIRT-Plugin, welches Er-gebnistabellen als PDF oder HTML exportieren kann. Als Positiv im Kriterium Schnittstellen wurde die Möglichkeit bewertet, per Python-Scripting Plugin Python-Code auszuführen und über Java-Snippet-Bausteine Java-Code des Benutzers auszuführen und auf Tabellen anzu-wenden. Prozessintegration ist nur über den Export/Import möglich, was negativ bewertet wurde. Die Installation in der Kategorie Usability ist bei Linux- und Windows-Installationen einfach über ein Archiv (Tarball resp. zip) möglich. Vorteile hat KNIME in der Bedienbarkeit. Die intuitive Workflow-Erstellung über „Baustei-ne“ macht es dem Benutzer sehr einfach, den Einstieg in KNIME finden. Ein weiterer Plus-punkt ist die Bausteinmenü-Anordnung entsprechend der Funktionalität. Zusätzlich werden für jeden Baustein bei Auswahl direkt die entsprechenden Informationen dazu angezeigt, was
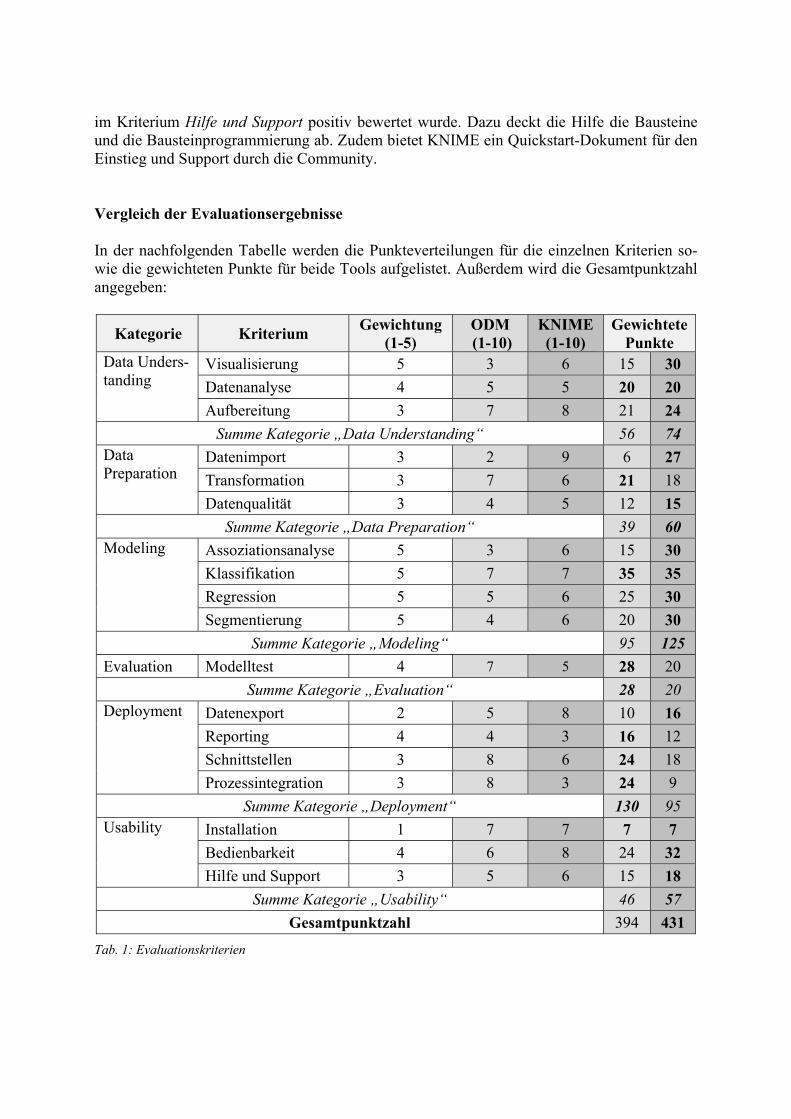
im Kriterium Hilfe und Support positiv bewertet wurde. Dazu deckt die Hilfe die Bausteine und die Bausteinprogrammierung ab. Zudem bietet KNIME ein Quickstart-Dokument für den Einstieg und Support durch die Community. Vergleich der Evaluationsergebnisse In der nachfolgenden Tabelle werden die Punkteverteilungen für die einzelnen Kriterien so-wie die gewichteten Punkte für beide Tools aufgelistet. Außerdem wird die Gesamtpunktzahl angegeben:
Kategorie Kriterium Gewichtung(1-5)
ODM (1-10)
KNIME (1-10)
Gewichtete Punkte
Data Unders-tanding
Visualisierung 5 3 6 15 30 Datenanalyse 4 5 5 20 20 Aufbereitung 3 7 8 21 24
Summe Kategorie „Data Understanding“ 56 74 Data Preparation
Datenimport 3 2 9 6 27 Transformation 3 7 6 21 18 Datenqualität 3 4 5 12 15
Summe Kategorie „Data Preparation“ 39 60 Modeling Assoziationsanalyse 5 3 6 15 30
Klassifikation 5 7 7 35 35 Regression 5 5 6 25 30 Segmentierung 5 4 6 20 30
Summe Kategorie „Modeling“ 95 125 Evaluation Modelltest 4 7 5 28 20
Summe Kategorie „Evaluation“ 28 20 Deployment Datenexport 2 5 8 10 16
Reporting 4 4 3 16 12 Schnittstellen 3 8 6 24 18 Prozessintegration 3 8 3 24 9
Summe Kategorie „Deployment“ 130 95 Usability Installation 1 7 7 7 7
Bedienbarkeit 4 6 8 24 32 Hilfe und Support 3 5 6 15 18
Summe Kategorie „Usability“ 46 57 Gesamtpunktzahl 394 431
Tab. 1: Evaluationskriterien

Da KNIME deutlich mehr Visualisierungsmöglichkeiten in der Kategorie Data Understan-ding als der Oracle Data Miner bietet, geht KNIME in dieser Kategorie als klarer Gewinner hervor. In Bereich der Datenanalyse kann man von einem Unentschieden sprechen, da beide Tools ausreichend Methoden zur Verfügung stellen (z.B. den Value Counter). In der Aufbe-reitung gewinnt wieder KNIME knapp. Beide Tools bieten unter Anderem das Normalisieren von Daten und das Aufsplitten von Tabellen an. ODM erhält Abzüge, weil das Filtern von Tabellenspalten nur durch die Erstellung eines Views möglich ist. Insgesamt hat in dieser Kategorie KNIME die Nase vorne. In der Kategorie Data Preparation gewinnt KNIME ebenfalls beim ersten Kriterium Daten-import deutlich, da es eindeutig mehr Möglichkeiten zum Import bereitstellt. ODM erhält bei Transformation aufgrund der guten DB-Funktionen knapp mehr Punkte. Im Bereich der Da-tenqualität bietet KNIME die Möglichkeit, Daten über die Rule Engine besser zu untersu-chen. Auch diese Kategorie entscheidet KNIME für sich. In der Kategorie Modeling haben beide Tools beim Kriterium Klassifikation ihre Vorzüge. Die Assoziationsanalyse gewinnt KNIME, da es mehr Methoden zur Verfügung stellt. Das-selbe gilt für die Kriterien Regression und Segmentierung, da KNIME durch das (auch in Zu-kunft noch erweiterbare) WEKA Plugin profitiert. Bei der Regression konnten beide Tools nicht überzeugen, da die Vorhersage jeweils nur für ein Target gleichzeitig möglich ist. In Summe ist KNIME auch in dieser Kategorie überzeugender. In der Kategorie Evaluation und kann ODM beim Kriterium Modelltest durch die verschie-denen Testmethoden für jede Mining-Methode und dem Modellvergleich zum „naive model“ (Vorhersage basiert auf dem Mittelwert) voll überzeugen. Auch in der Kategorie Deployment zeigen sich die Vorteile von ODM. Zwar hat KNIME im Kriterium Datenexport durch die Vielzahl von Exportmöglichkeiten die Nase vorn, aber die drei anderen Kriterien Reporting (unzureichende Reporting-Möglichkeiten in KNIME), Schnittstellen (Vorteile von ODM durch In-Database Ansatz und direkte Anbindung an weite-re BI-Applikationen) und Prozessintegration gehen an ODM. Bei der Prozessintegration ge-winnt ODM sogar deutlich, da Activities als PL/SQL Packages gespeichert werden und als SQL Skript (automatisiert) ausgeführt werden können. In der Kategorie Usability kann sich dann aber KNIME wieder behaupten. Da es bei beiden Tools während der Installation keine Probleme gab, erhalten dort beide Tools die gleiche Punktzahl. Durch die intuitive Workflow-Erstellung über "Bausteine" kann sich KNIME aber deutlich im Kriterium Bedienbarkeit durchsetzen (im Gegensatz dazu bietet ODM keine Vi-sualisierung der Prozesse). Das letzte Kriterium Hilfe und Support gewinnt KNIME aufgrund der Baustein-Informationen die direkt bei der Auswahl angezeigt werden und den Support der durch die Community vorhanden ist. Abbildung 4 visualisiert die erreichten Punkte der beiden Tools in den jeweiligen Kategorien. Dabei wird der prozentuale Anteil zu den maximal erreichbaren Punkten dargestellt.

Abb. 4: Vgl. der erreichten Punkte in den Evaluationskategorien
Fazit und Ausblick Subjektiv, nach den angegebenen Bewertungskriterien liegt das Open Source Tool KNIME hinsichtlich der Eignung zur Lösung einer Data Mining Problemstellung knapp vorne gege-nüber dem ODM. Dies ist vor allem auf die intuitive Bedienbarkeit und die konsequente Workflow-Orientierung sowie die große Auswahl an Data Mining Verfahren zurück zu füh-ren. Es bleibt beim ODM die Frage, wie stark dieses Produkt im Fokus der Weiterentwick-lung steht, gerade auch, wenn man die doch schwache Leistung bei Hilfe und Support sieht. In jedem Fall zeigt der vorliegende Erfahrungsbericht, dass in mancher Hinsicht noch deutli-ches Verbesserungspotenzial vorhanden ist. Dennoch war es sowohl mit KNIME als auch mit ODM möglich, ein Ergebnis für die Aufgabestellung des DMC 2009 zu erzielen, wobei die nicht aufzulösende Fehlermeldung im ODM bei der naheliegenden Regression besonders ne-gativ auffiel. Es wird daher interessant sein, zu beobachten, ob seitens Oracle dem immer wichtiger werdenden Thema Data Mining die gebührende Aufmerksamkeit geschenkt werden wird, um auch in diesem Bereich eine rundum zufriedenstellende Lösung bieten zu können.

Kontaktadresse: Prof. Dr. Reinhold von Schwerin Hochschule Ulm Prittwitzstr. 10 D-89075 Ulm Telefon: +49(0)731-5028259 Fax: +49(0)731-5028240 E-Mail [email protected] Internet: http://www.hs-ulm.de/r.schwerin





























