Embed Size (px)
Citation preview

Data MiningKnowledge on rough set theory
SUSHIL KUMAR SAHU

What is Data Mining??
Extraction of knowledge from data
exploration and analysis of large quantities of data to discover meaningful pattern from data.
Discover Knowledge
Why datamining
Datamining is used in: pattern matching and restore the original
picture from a noisy one. Medical Business etc What datamining do: Finds relationship and make prediction.

Types of data mining Relational data mining: It is the data mining
technique for relational databases. Unlike traditional data mining algorithms, which look for patterns in a single table , relational data mining algorithms look for patterns among multiple tables (relational patterns).
Web mining: - is the application of data mining techniques to discover patterns from the Web.

Software Mining and Data Mining:
Instead of mining individual data sets, software mining focuses on metadata, such as database schemas. Knowledge Discovery from software systems addresses structure, behavior as well as the data processed by the software system.

OLAP
OLAP deals with tools and technique for data analysis that can give nearly instantaneous answer to queries.
OLAP use multidimensional array that allow user to analyze the data.
Datamining server must be integrated with data warehouse and OLAP server.

Data Mining : Motivation
Huge amounts of data
Important need for turning data into useful information
Fast growing amount of data, collected and stored in large and numerous databases exceeded the human ability for comprehension without powerful tools

Data Mining Techniques
Decision Trees
Neural Network
Genetic Algorithms
Fuzzy Set Theory
Rough Set Theory

DATA MINING TECHNIQUES
Artificial neural networks: Non-linear predictive models that learn through training and resemble biological neural networks in structure.
Decision trees: Tree-shaped structures that represent sets of decisions. These decisions generate rules for the classification of a dataset.

Genetic algorithms: Optimization techniques that use processes such as genetic combination, mutation, and natural selection in a design based on the concepts of evolution.

THE ROUGH SET THEORY
One of the new data mining theories is the rough set theory that can be used for
(1) Reduction of data sets
(2) Finding hidden data patterns
(3) Generation of decision rules

What is rough set
A rough set is a formal approximation of a crisp set in terms of a pair of sets which give the lower and the upper approximation of the original set.
The tuple composed of the lower and upper approximation is called a rough set.The accuracy is perfect if αP(X) = 1

Reduct and Core
Reduct is a subset of attributes which by itself can fully characterize the knowledge in the database.
The set of attributes which is common to all reducts is called the core.
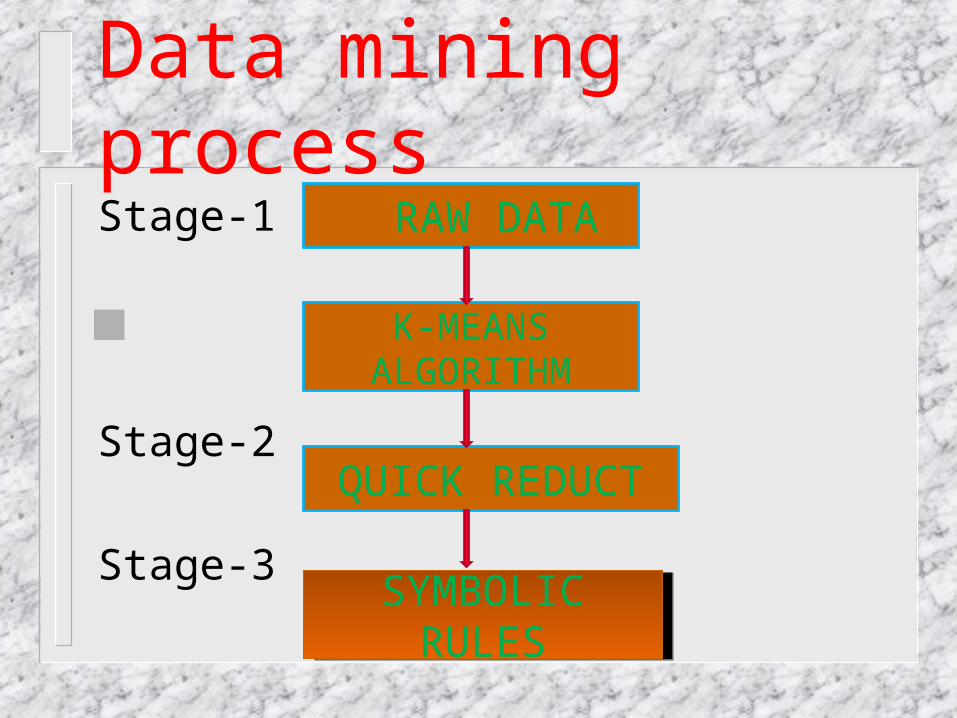
Data mining processStage-1
Stage-2
Stage-3
Stage-4
RAW DATA
K-MEANS ALGORITHM
SYMBOLIC RULES
SYMBOLIC RULES
QUICK REDUCT
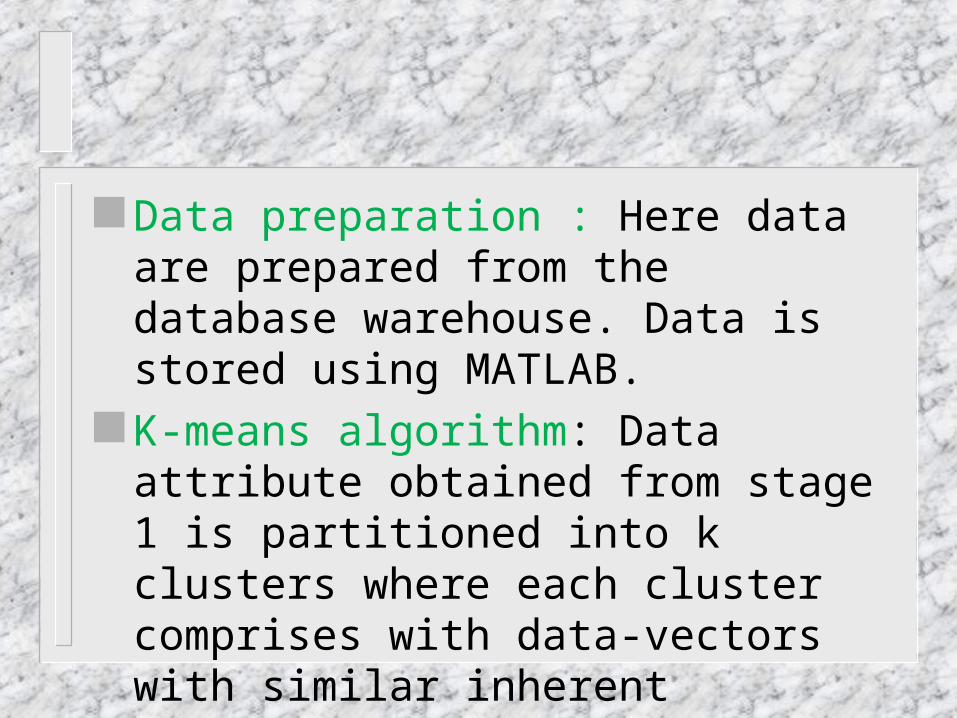
Data preparation : Here data are prepared from the database warehouse. Data is stored using MATLAB.
K-means algorithm: Data attribute obtained from stage 1 is partitioned into k clusters where each cluster comprises with data-vectors with similar inherent characteristics

The K-Means Algorithm Process:
The dataset is partitioned into K clusters and the data points are randomly assigned to the clusters resulting in clusters that have roughly the same number of data points .
For each data point, calculate the distance from the data point to each cluster.
If the data point is closest to its own cluster leave it where it is. If the data point is not closest to its own cluster, move it into the closest cluster.
Repeat the above step until a complete pass through all the data points results in no data point moving from one cluster to another. At this point the clusters are stable and
the clustering process ends.

Quick-reduct algorithm: Quick-reduct algorithm is used to compute a minimal
reduct without exhaustively generating all possible subsets.
The reduction of attribute is achieved by comparing equivalence relations generated by set of attributes so that the reduced set provides the same predictive capability of the decision feature as the original.
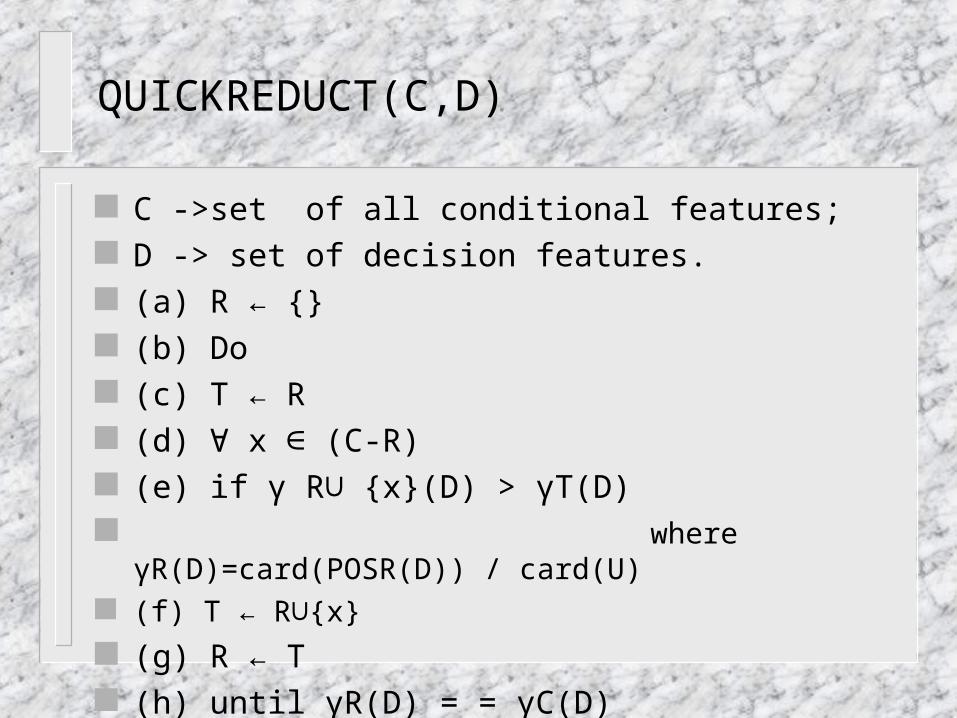
QUICKREDUCT(C,D)
C ->set of all conditional features; D -> set of decision features. (a) R ← {} (b) Do (c) T ← R (d) x (C-R) ∀ ∈ (e) if γ R {x}(D) > γT(D)∪ where γR(D)=card(POSR(D)) / card(U) (f) T ← R {x}∪ (g) R ← T (h) until γR(D) = = γC(D) (i) return R

Rule extraction:
It uses the following Heuristic Approach
– Merge identical rows that has similar condition and decision attribute
– Compute the core of every row
– Merge duplicate rows and compose a table with reduct value
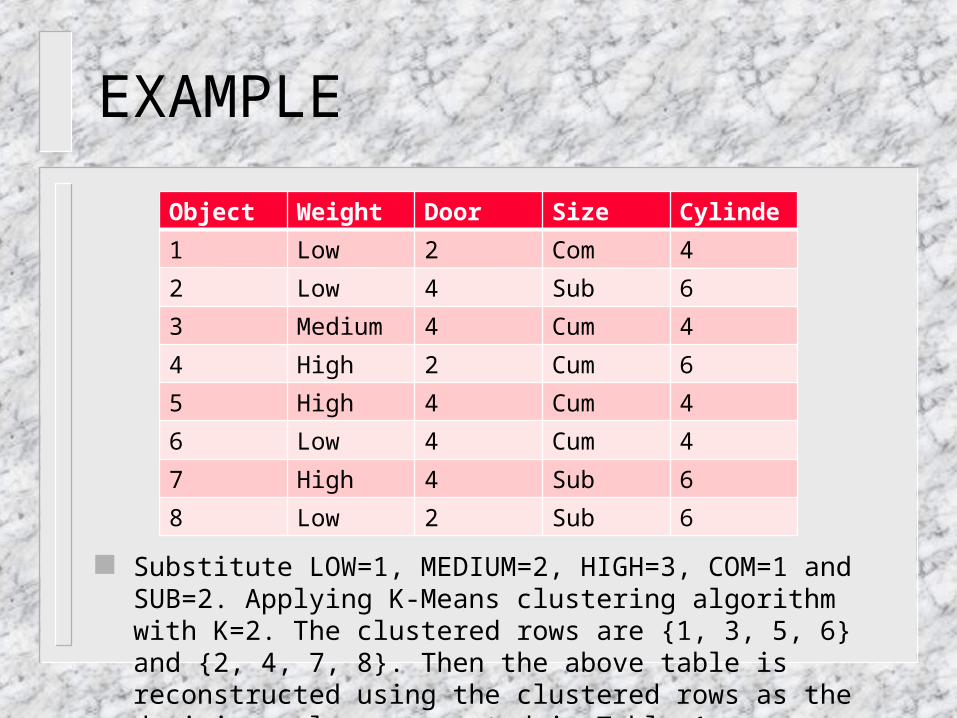
EXAMPLE
Substitute LOW=1, MEDIUM=2, HIGH=3, COM=1 and SUB=2. Applying K-Means clustering algorithm with K=2. The clustered rows are {1, 3, 5, 6} and {2, 4, 7, 8}. Then the above table is reconstructed using the clustered rows as the decision value, presented in Table 1.
Object Weight Door Size Cylinder
1 Low 2 Com 4
2 Low 4 Sub 6
3 Medium 4 Cum 4
4 High 2 Cum 6
5 High 4 Cum 4
6 Low 4 Cum 4
7 High 4 Sub 6
8 Low 2 Sub 6
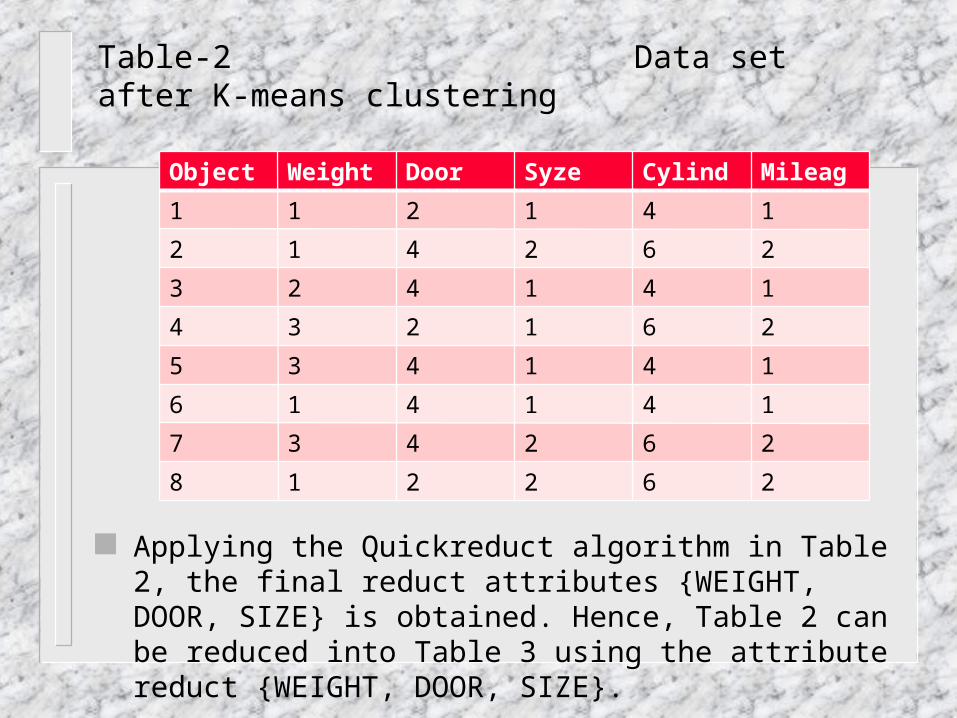
Table-2 Data set after K-means clustering
Applying the Quickreduct algorithm in Table 2, the final reduct attributes {WEIGHT, DOOR, SIZE} is obtained. Hence, Table 2 can be reduced into Table 3 using the attribute reduct {WEIGHT, DOOR, SIZE}.
Object Weight Door Syze Cylinder
Mileage
1 1 2 1 4 1
2 1 4 2 6 2
3 2 4 1 4 1
4 3 2 1 6 2
5 3 4 1 4 1
6 1 4 1 4 1
7 3 4 2 6 2
8 1 2 2 6 2
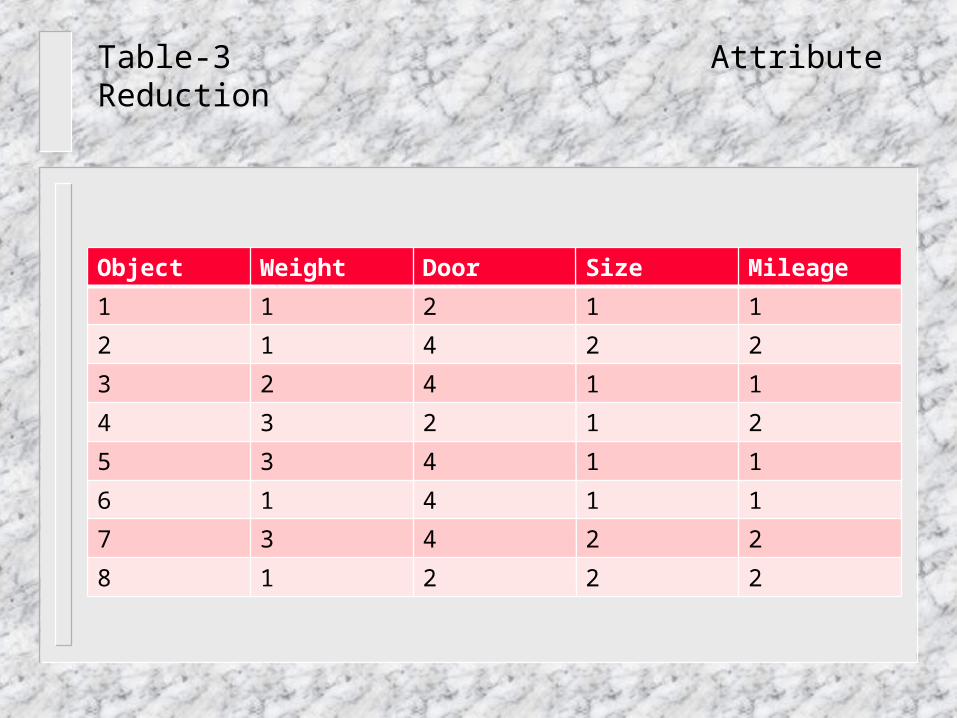
Table-3 Attribute Reduction
Object Weight Door Size Mileage
1 1 2 1 1
2 1 4 2 2
3 2 4 1 1
4 3 2 1 2
5 3 4 1 1
6 1 4 1 1
7 3 4 2 2
8 1 2 2 2
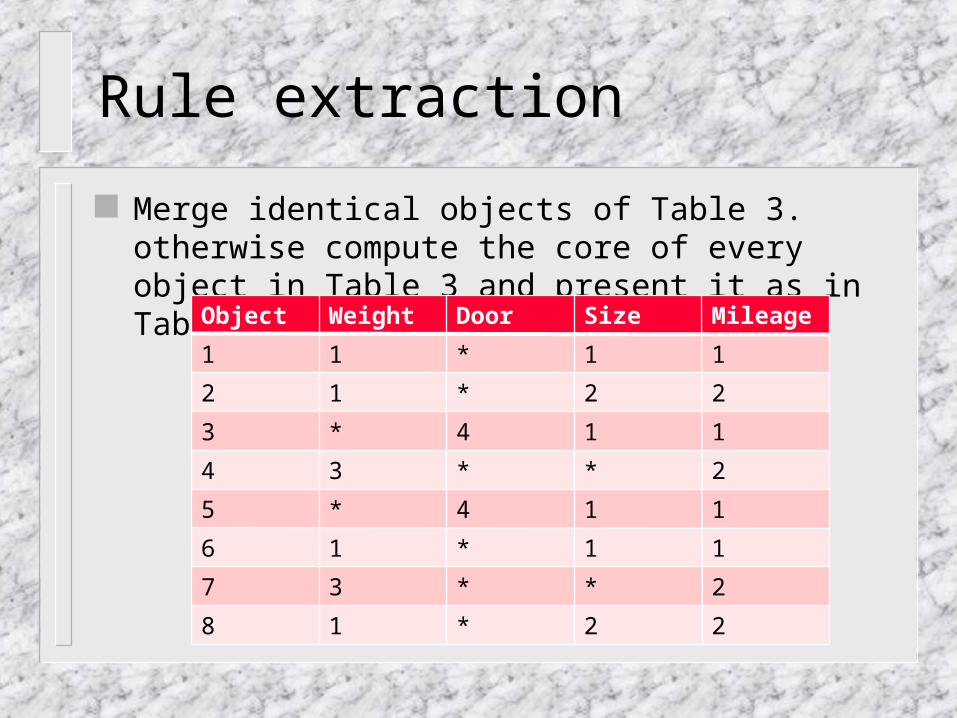
Rule extraction
Merge identical objects of Table 3. otherwise compute the core of every object in Table 3 and present it as in Table -4.
Object Weight Door Size Mileage
1 1 * 1 1
2 1 * 2 2
3 * 4 1 1
4 3 * * 2
5 * 4 1 1
6 1 * 1 1
7 3 * * 2
8 1 * 2 2
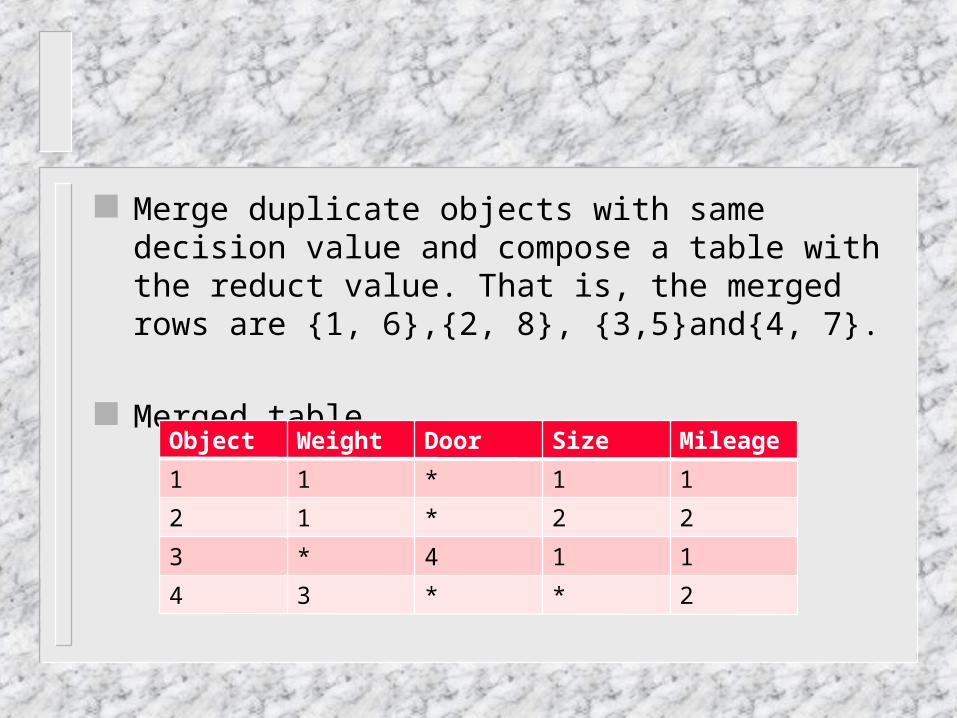
Merge duplicate objects with same decision value and compose a table with the reduct value. That is, the merged rows are {1, 6},{2, 8}, {3,5}and{4, 7}.
Merged table
Object Weight Door Size Mileage
1 1 * 1 1
2 1 * 2 2
3 * 4 1 1
4 3 * * 2

The decision obtained from the above example
Decision rules are often presented as implications and are often called “if….then…” rules. We can express the rules as follows:
If SIZE = 1 THEN MILEAGE = 1 If SIZE = 2 THEN MILEAGE = 2 If DOOR = 4 and SIZE = 1 THEN MILEAGE = 1 If WEIGHT = 3 THEN MILEAGE = 2
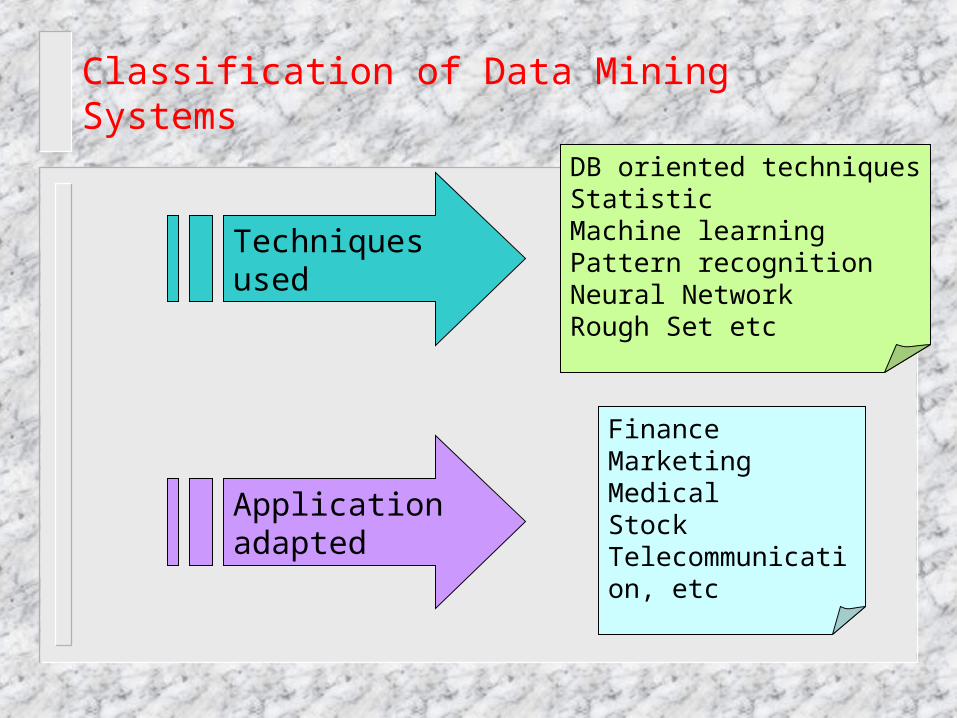
Classification of Data Mining Systems
Techniques used
DB oriented techniquesStatisticMachine learningPattern recognitionNeural NetworkRough Set etc
Application adapted
FinanceMarketingMedicalStockTelecommunication, etc
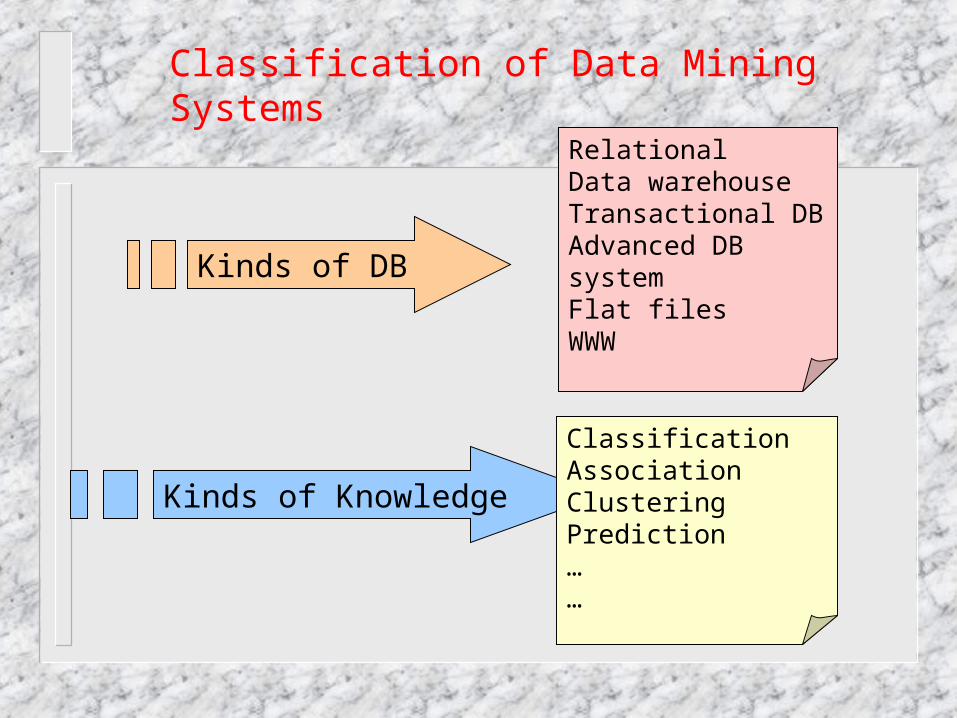
Kinds of DB
RelationalData warehouseTransactional DBAdvanced DB systemFlat filesWWW
Kinds of Knowledge
ClassificationAssociationClusteringPrediction……
Classification of Data Mining Systems
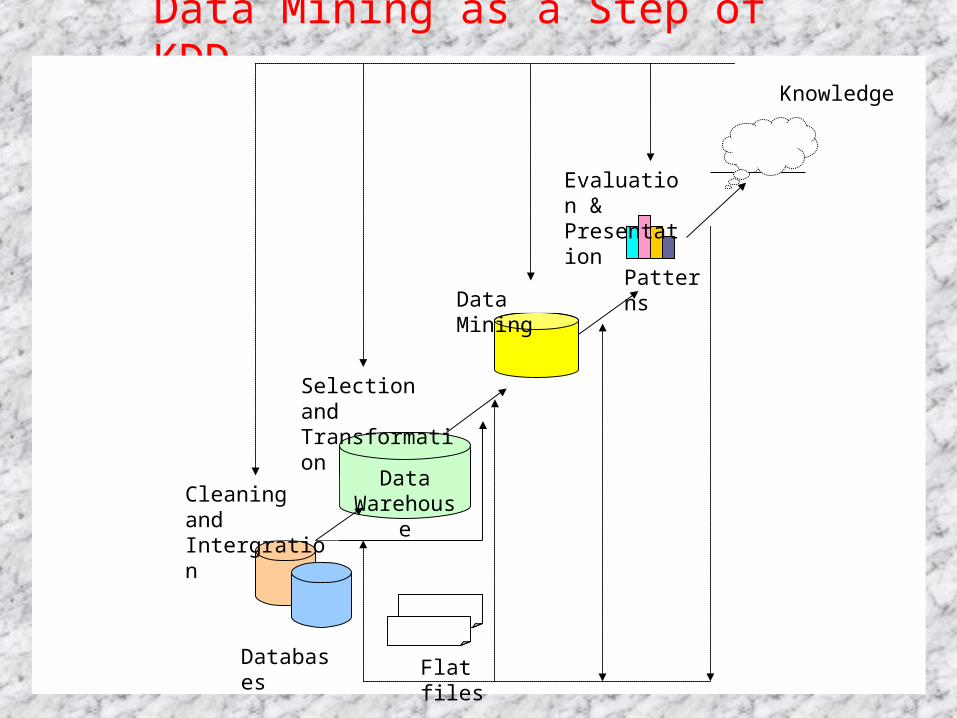
Data Mining as a Step of KDD
Patterns
DataWarehouse
Databases Flat files
Selection and Transformation
Data Mining
Evaluation & Presentation
Cleaning and Intergration
Knowledge

WHY MATLAB FOR DATA MINING?
As a programming language, MATLAB is very like other procedural languages such as Fortran or C.
Graphing capability in MATLAB is among the best in the business, and all MATLAB graphs are compeltely configurable through software.
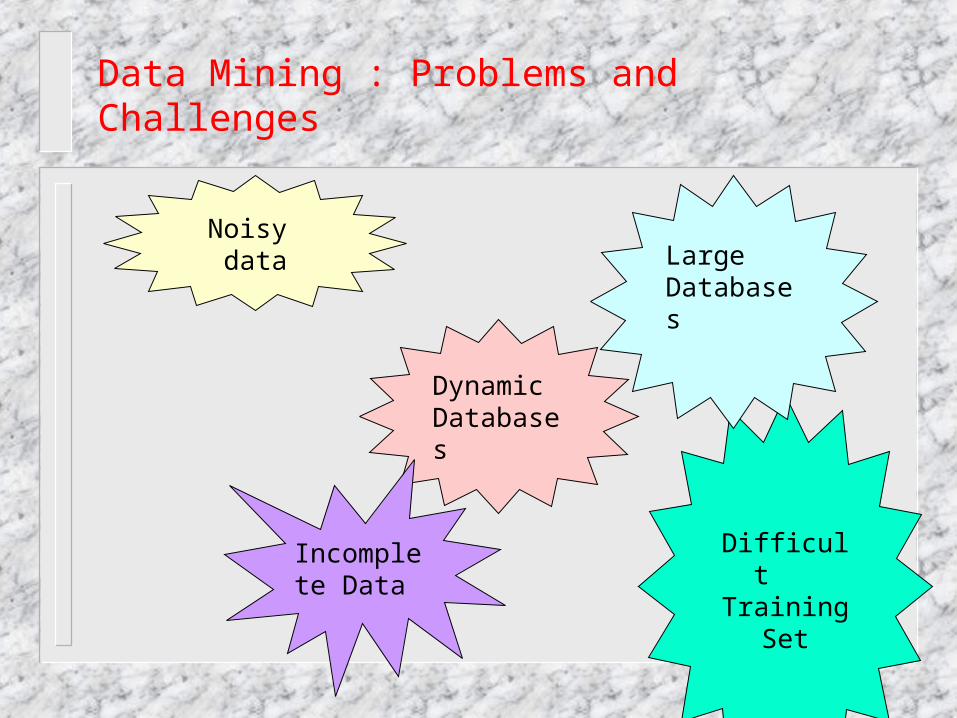
Data Mining : Problems and Challenges
Noisy data
Difficult Training
Set
Dynamic Databases
Large Databases
Incomplete Data

Performance Issues
Cost of the Learning
Set
Time and Memory Constraint
Predictive Ability

Conclusion
Data Mining is an analytic process designed to explore data in search of consistent patterns and/or systematic relationships between variables, and then to validate the findings by applying the detected patterns to new subsets of data.
The ultimate goal of data mining is prediction.
Application of rough set theory in data mining is used for time sequence analysis of electrical signal. It is also used in medical diagnosis.
It is very effective due to its less time complexity, less cost , accuracy, cost of learning is less.

References
www.google.com www.icgst.com http://en.wikipedia.org/wiki/Rough_set http://en.wikipedia.org/wiki/Concept_mining www.ieee.com www.kurth.com www.gosephtechnology.com

THANKS!!!
QUESTIONS??