Embed Size (px)
Citation preview

D5.3 Roadmap v23
1
D5.3 Roadmap v23
Document Information
Contract Number 619788
Project Website www.rethinkbig-project.eu
Contractual Deadline Month 22 (Dec 2015)
Dissemination Level Public
Nature Report
Author RETHINK big Editorial Team: Gina Alioto, Christophe Avare, Paul Carpenter, Marcus Leich, Osman Unsal
Reviewer RETHINK big Editorial Team
Keywords See complete list of terms and abbreviations.
This project has received funding from the European Union’s Seventh Framework Programme for research, technological development and demonstration under grant agreement no 619788. This content of this document reflects only the author’s views; the Union is not
liable for any use that may be made of the information contained therein. 2016 RETHINK big Project. All rights reserved. www.rethinkbig-project.eu

D5.3 Roadmap v23
2
Change Log
Version Description of Change
v20 This is the first version sent to the European Commission.
v22 This version addresses anonymization concerns (from v20) as well as implements some additional Validation Interview feedback. All changes have been marked in gray.
v23 This version no longer shows the changes from the previous version marked in gray.

D5.3 Roadmap v23
3
Table of Contents
Terms and Abbreviations ........................... ................................................... 5
Introduction ...................................... ....................................................... 6 11.1 Objectives ......................................................................................................................6 1.2 Target audience and scope ............................................................................................6
1.2.1 Big Data within the context of this document ...........................................................6 1.2.2 The EC Public Private Partnership for Big Data and beyond ...................................7
1.3 Process ..........................................................................................................................8 1.4 Document organization .................................................................................................9
Roadmap at-a-glance................................ ............................................ 10 22.1 Industry key findings ...................................................................................................10 2.2 High level action summary ..........................................................................................11
Network: Beyond the backbone, edging out the compet ition .......... 13 33.1 Scope of network architecture .....................................................................................13 3.2 Where we are today: Market trends and main actors .................................................13
3.2.1 Network appliance hardware: from specialized to bare metal ................................13 3.2.2 From hardware to “softwarization” and virtualization ............................................14
3.2.3 Deconstructing the data center (beyond +400GE) ..................................................15 3.3 Where we want to be ...................................................................................................17
3.3.1 Industry pains and expected gains ...........................................................................17 3.3.2 Key findings ............................................................................................................20
3.4 How we are going to get there ....................................................................................20 3.4.1 TRL > 5: Accelerating adoption of current technologies ........................................20 3.4.2 TRL 3 - 5: Preparing the next generation ................................................................22 3.4.3 TRL < 3: Anticipating future challenges ................................................................24
Architecture: Accelerating compute for machine lear ning for 4analytics ......................................... .............................................................. 26
4.1 Scope of compute node architecture ............................................................................26 4.2 Where we are today: Market trends and main actors .................................................27
4.2.1 The march toward heterogeneous systems ..............................................................27 4.2.2 Specialization and vendor lock-in ...........................................................................28 4.2.3 Integration inside the compute node .......................................................................29 4.2.4 Verticalization and hyperscalers .............................................................................30 4.2.5 Non-von Neumann ..................................................................................................31
4.3 Where we want to be ...................................................................................................32 4.3.1 Industry pains and expected gains ...........................................................................32 4.3.2 Key findings ............................................................................................................34
4.4 How are we going to get there ....................................................................................35 4.4.1 TRL > 5: Accelerate the adoption of heterogeneous systems .................................35
4.4.2 TRL 3 - 5: Preparing the next generation hardware ................................................36 4.4.3 TRL < 3: Anticipating future challenges ................................................................37
Software and beyond: Supporting hardware optimizati ons for Big 5Data ............................................................................................................... 39
5.1 Where we are today: Market trends and main actors .................................................40 5.1.1 Big Data processing: From query languages to frameworks ..................................40 5.1.2 March toward hardware dependence ......................................................................40
5.1.3 Too many hardware programming abstractions ......................................................40 5.1.4 Complex cloud service offerings: ML-as-a-Service and beyond ............................42
5.1.5 A lack of Big Data benchmarks ..............................................................................42

D5.3 Roadmap v23
4
5.2 Where we want to be ...................................................................................................42 5.2.1 Industry pains and expected gains ...........................................................................42 5.2.2 Key findings ............................................................................................................44
5.3 How we are going to get there ....................................................................................44 5.3.1 TRL > 5: Accelerating adoption of current technologies ........................................44 5.3.2 TRL 3 - 5: Preparing the next generation for adoption of new technologies ..........47 5.3.3 TRL < 3: Anticipating future challenges ................................................................48
Bibliography ...................................... .................................................... 49 6

D5.3 Roadmap v23
5
Terms and Abbreviations ADAS Advanced Driver Assistance System API Application Programmer Interface ASIC Application Specific Integrated Circuit Chiplet Individual die in a Silicon-in-Package (SiP) CMOS Complementary Metal Oxide Semiconductor CPU Central Processing Unit CUDA Compute Unified Device Architecture (Nvidia’s language for GPGPUs) DARPA (U.S.) Defense Advanced Research Agency DCI Data Center Interconnect DRAM Dynamic Random Access Memory DSP Digital Signal Processor DWDM Dense Wavelength Division Multiplexing EMIB Embedded Multi-die Interconnect Bridge FPGA Field Programmable Gate Array GPGPU General Purpose Graphics Processing Unit (compute-capable GPU) GPU Graphics Processing Unit HDL Hardware Description Language, e.g. VHDL or Verilog HLS High Level Synthesis (designing hardware using high-level programming languages) HPC High-Performance Computing IoT Internet of Things IP Intellectual Property / Internet Protocol LAN Large Area Network ML Machine Learning MPI Message Passing Interface NIC Network Interface Controller NFV Network Function Virtualization NLP Natural Language Processing NOS Network Operating System NRE Non-Recurring Engineering (cost) PCIe Peripheral Component Interconnect Express RDMA Remote Direct Memory Access ROI Return on Investment SaaS Software as a Service (e.g. Facebook, LinkedIn, Bluebee) SATA Serial Advanced Technology Attachment SDN Software Defined Network SIMD Single Instruction Multiple Data SIMT Single Instruction Multiple Thread SiP System-in-Package SoC System-on-Chip SME Small and Medium Enterprises SPARQL SPARQL Protocol and RDF Query Language SQL Standard Query Language TCO Total Cost of Ownership TPC Transaction Processing Performance Council TRL Technology Readiness Level USB Universal Serial Bus VHDL VHSIC Hardware Description Language VPS Virtual Private Server

D5.3 Roadmap v23
6
Introduction 1
1.1 Objectives The overarching objective of the RETHINK big Roadmap is to provide a set of coordinated technology development recommendations (focused on optimizations in networking and hardware) that would be in the best interest of European Big Data companies to undertake in concert as a matter of competitive advantage. As authors, we had the following objectives in mind when we started writing the document:
• Identify business opportunities from European industry stakeholders in the area of Big Data
• Predict the future technologies that will disrupt the state of the art in Big Data processing in terms of hardware and networking optimizations
• Identify a critical mass of European industry stakeholders that see a clear competitive advantage enabled by embracing specific future technologies
• Develop clear recommendations for the European Commission that ultimately facilitate timely European industry access to these future technologies via instruments that bring together the appropriate mix of technology providers, system integrators, Big Data analytics providers and academic research.
1.2 Target audience and scope This document is intended for the European Commission as a guide for promoting targeted industry / academic collaborations in future funding calls over the next 10 years. However, it is equally targeted at Big Data analytics and computer science professionals, students, and professors, as well as the public at large interested in technology and technology use. While we tried to be complete and exhaustive, it is inevitable that some technologies and aspects have been omitted. In most cases when a technology has been omitted, it is largely due to the lack of potential European competitive advantage which is the foundation of this document. A clear example of this type of omission is memory technology, a capital-intensive low margin industry in which there is currently no major European player.
1.2.1 Big Data within the context of this document In a 2014 article in Forbes [Pre14] technology “thought leader” Gil Press provides no fewer than twelve – yes, twelve! – definitions for the term Big Data. He begins with the classical Oxford English Dictionary definition (definition #1) “data of a very large size, typically to the extent that its manipulation and management present significant logistical challenges” but quickly moves on to the widely quoted 2011 McKinsey study definition of (#3) “datasets whose size is beyond the ability of typical database software tools to capture, store, manage, and analyze,” only to later settle on the more esoteric “A new attitude by businesses, non-profits, government agencies, and individuals that combining data from multiple sources could lead to better decisions.” Even world renowned American linguist and adjunct professor at the U.C. Berkeley School of Information, Geoffrey Nunberg (and champion of Big Data for his own research) in his 2012 push to make Big Data “word of the year” [Nun12] concedes that Big Data is “no more exact a notion than Big Hair… The fact is that an exponential curve looks just as overwhelming wherever you get onboard… After all,

D5.3 Roadmap v23
7
digital data has been accumulating for decades in quantities that always seemed unimaginably vast at the time.” He then concludes that it’s not the amount of data that makes Big Data but rather “…the way data is generated and processed… It's only when all those little chunks are aggregated that they turn into Big Data.” Stack Overflow believes the definition of Big Data is a matter of opinion with endless scope: “If you can imagine an entire book that answers your question, you’re asking too much.” [STA16] while Quora users posted more than 100 definitions, most of them lengthy. Despite the philosophical discussions that this topic seems to incite, there seems to be a general recognition that the proof is in the processing, meaning that what makes it BIG data is the fact that the standard and traditional methods and architectures are not enough to process (and store) the data within a reasonable timeframe. For the purposes of this roadmap, we will assume that Big Data is precisely that, Big enough to cause undesirable processing bottlenecks be them at the chip, node or network level.
1.2.2 The EC Public Private Partnership for Big Dat a and beyond This roadmap serves as one piece of the larger framework of roadmaps (See Figure 1) being put together for the European Commission at this time. In the process of putting together the document, it was frequently noted that many of the compute problems related to Big Data are not merely Big Data problems, but rather more general compute problems linked to the end of Moore’s law, Dennard scaling and beyond. As such, this document attempts to limit the scope to those problems that have the most direct impact on Big Data-related European industry with the understanding that more general compute problems are handled within the context of the ICT ETP Roadmaps (NEM, NESSI, EPoSS and Photonics21). This roadmap was developed while keeping advancements in High Performance Computing in mind considering the growing importance of data in this area; however, it is again limited to activities that show a clear benefit for EU Big Data Industry. HPC-related aspects are covered in the ETP4HPC Roadmap. The same can be said of the clear connections between Big Data and Cisco prediction of 50 billion connected devices by 2020 and the so-called Internet of Things on its way to becoming the Internet of Everything. The key to this nascent compute area seems to be the data itself, and we believe that the opportunities provided by IoT will be “enabled by and dependent on the tremendous data collections and compute capacities in the back-end machines and datacenters that use such data” [IEE14]. As such, we maintain our focus on these back-end machines and data centers, leaving all other aspects to be covered under the Alliance of Internet of Things Initiative and the regulation and standards for communication at the network level under the work of the 5G-PPP (Public Private Partnership). Finally, while no discussion regarding Big
Figure 1 – [BDV16] ETP/PPP Collaboration

D5.3 Roadmap v23
8
Data is complete without a detailed discussion of Software, it is important to understand that the treatment of Software in this document is limited to lower level system software that supports hardware and networking optimizations for Big Data. We leave the more detailed discussion of the Big Data analytics applications and the data itself to the roadmap of the Big Data Value Association.
1.3 Process This document is the direct outcome of a 2-year project (RETHINK big) funded by the European Commission. During the first year of the project a core team of ten technologists met once in person as well as monthly by phone in preparation for a face-to-face expert workshop held in Madrid. The workshop aimed to bring together representatives from both industry applications and technology domains to establish a common vocabulary and an understanding of Big Data business barriers. The team also conducted a detailed technical survey prior to the event in order to set the discussion topics. Through these two methods, we were able to identify a comprehensive list of largely industry-related Big Data problems; however, we did not have enough information from the individual companies to understand how each respective problem generated a specific business need nor did we posit the potential business benefit that could be achieved by solving each problem. We focused on remedying the fact that we had not gathered sufficient information from industry during the second year of the project. We began by developing a set of Initial Company Interview Questions, tailoring our questions to both Software
Applications and Services providers and to Technology providers while at the same time focusing on the business plan of each specific company. We began each interview by asking the interviewee to explain their product and / or service offering and then would characterize the company in terms of their product type and business model. Next, we focused directly on each
company’s own roadmap by asking whether or not each
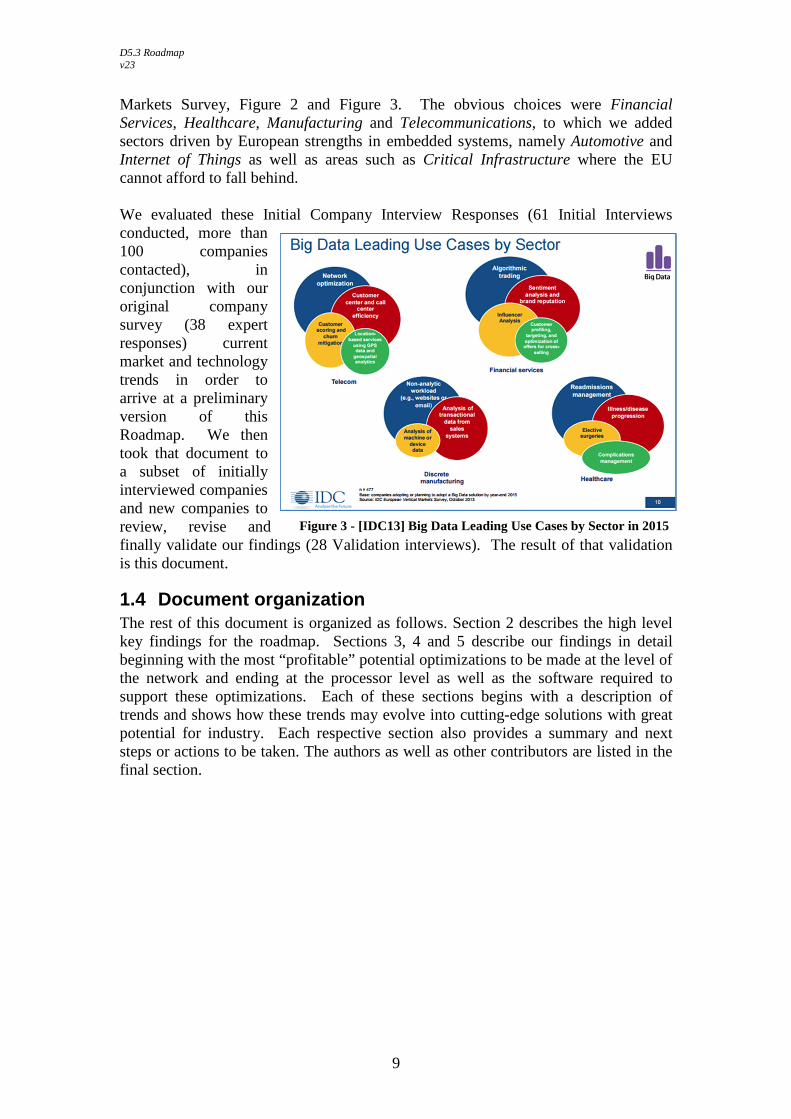
company has its own roadmap for optimization for Big Data as well as whether or not this kind of roadmap could directly impact its business. Finally, we worked to better understand the relationships between each of the Application / Service Providers and their own Technology Providers in terms of business needs by examining the magnitude improvement in TCO, performance and productivity that would be required for companies to adopt Big Data-related hardware optimization strategies. We determined which companies to interview based on the 2013 IDC Report [IDC13] on the industries that had the biggest plans for adoption of Big Data as well as the Top Big Data Use Cases as identified in the results of the 2013 IDC European Vertical
Figure 2 - [IDC13] Big Data Adoption by Industry by 2015
D5.3 Roadmap v23
9
Markets Survey, Figure 2 and Figure 3. The obvious choices were Financial Services, Healthcare, Manufacturing and Telecommunications, to which we added sectors driven by European strengths in embedded systems, namely Automotive and Internet of Things as well as areas such as Critical Infrastructure where the EU cannot afford to fall behind. We evaluated these Initial Company Interview Responses (61 Initial Interviews conducted, more than 100 companies contacted), in conjunction with our original company survey (38 expert responses) current market and technology trends in order to arrive at a preliminary version of this Roadmap. We then took that document to a subset of initially interviewed companies and new companies to review, revise and finally validate our findings (28 Validation interviews). The result of that validation is this document.
1.4 Document organization The rest of this document is organized as follows. Section 2 describes the high level key findings for the roadmap. Sections 3, 4 and 5 describe our findings in detail beginning with the most “profitable” potential optimizations to be made at the level of the network and ending at the processor level as well as the software required to support these optimizations. Each of these sections begins with a description of trends and shows how these trends may evolve into cutting-edge solutions with great potential for industry. Each respective section also provides a summary and next steps or actions to be taken. The authors as well as other contributors are listed in the final section.
Figure 3 - [IDC13] Big Data Leading Use Cases by Sector in 2015

D5.3 Roadmap v23
10
Roadmap at-a-glance 2In this section, we first summarize the key findings based on the collective response from our interviews and surveys. Additionally, we introduce the high level actions that will be presented in detail in later sections of the document.
2.1 Industry key findings (1) Industry is still focused on finding how to extract value from their data, and they are also still looking for the right business model to turn this value into profit. Consequently, they are not focused on processing (and storage) bottlenecks, let alone on the underlying hardware. As we mentioned in the previous section, we were in touch via interview or survey with more than 100 companies across a broad spectrum of Big Data-related Industries including major and up-and-coming players from telecommunications, hardware design and manufacturers as well as a strong representation from health, automotive, financial and analytics sectors. The overwhelming response is that Industry does not see Big Data problems, only Big Data opportunities. We believe that this is largely the case because the industry is not yet mature enough for most companies to be trying to do that kind of analytics and all-encompassing Big Data processing that leads to undesirable bottlenecks. (2) European companies are not convinced of the Return on Investment of using novel architectures. First, it is important to note that all of the analytics companies with which we spoke were extremely price-sensitive. Moreover, they are content to use the currently available hardware as long as they continue to receive the most competitive pricing. All of this coupled with the fact that there is no clean metric or benchmark for side-by-side comparisons for heterogeneous architectures, the majority of the companies were not convinced that the investment in expensive hardware coupled with the person months required to make their products work with new hardware were worthwhile. (3) Europe is at a strong disadvantage with respect to hardware / software co-design. The European ecosystem is highly fragmented while media and internet giants such as Google, Amazon, Facebook, Twitter and Apple and others (also known as hyperscalers) are pursuing verticalization and designing their own infrastructures from the ground up. European companies that are not closely considering hardware and networking technologies as a means to cutting cost and offering better future services run the risk of falling further and further behind. Hyperscalers will continue to take risks and transform themselves because they are the “ecosystem”, moving everybody else in their trail. (4) Dominance of non-European companies in the server market complicates the possibility of new European entrants in the area of specialized architectures. Intel is currently the gatekeeper for new Data Center architectures; moreover, Intel is spearheading the effort to increase integration into the CPU package which can only exacerbate this problem.

D5.3 Roadmap v23
11
Consolidation among DRAM manufacturers has reduced the worldwide number of DRAM suppliers to three: Samsung, SK Hynix and Micron. It is unrealistic for Europe to enter the DRAM industry. Without the right support, the best outcome for any European hardware provider will be that it is acquired by a non-European company, so the IP leaves Europe.
2.2 High level action summary Promote adoption of current and upcoming networking standards Europe should accelerate the adoption of the current and upcoming standards (10 and 40Gb Ethernet) based on low-power consumption components proposed by European Companies and connect these companies to end users and data-center operators so that they can demonstrate their value compared to the bigger players. Prepare for the next generation of hardware and take advantage of the convergence of HPC and Big Data interests In particular, Europe must take advantage of its strengths in HPC and embedded systems by encouraging dual-purpose products that bring these different communities together (e.g. HPC / Big Data hardware that can be differentiated in SW). This would allow new companies to sell to a bigger market and decrease the risk associated with development of new product. Anticipate the changes in Data Center design for 400Gb Ethernet networks (and beyond) This includes paying special attention to photonics-on-silicon integration and novel Data Center interconnect designs. Reduce risk and cost of using accelerators Europe must lower the barrier to entry of heterogeneous systems and accelerators; collaborative projects should bring together end users, application providers and technology providers to demonstrate significant (10x) increase in throughput per node on real analytics applications. Encourage system co-design for new technologies Europe must bring together end users, application providers, system integrators and technology providers to build balanced system architectures based on silicon-in-package integration of new technologies, I/O interfaces and memory interfaces, driven by the evolving needs of big data. Improve programmability of FPGAs Europe should also fund research projects involving providers of tools, abstractions and high-level programming languages for FPGAs or other accelerators with the aim of demonstrating the effectiveness of this approach using real applications. Europe should also encourage a new entrant into the FPGA industry. Pioneer markets for neuromorphic computing and increase collaboration For neuromorphic computing and other disruptive technologies, the principal issue is the lack of a market ecosystem, with insufficient appetite for risk and few European companies with the size and clout to invest in such a risky direction. Europe should encourage collaborative research projects that bring together actors across the whole

D5.3 Roadmap v23
12
chain: end users, application providers and technology providers to demonstrate real value from neuromorphic computing in real applications. Create a sustainable business environment including access to training data Europe should address access to training data by encouraging the collection of open anonymized training data and encouraging the sharing of anonymized training data inside EC-funded projects. To address the lack of information sharing, Europe should encourage interaction between hardware providers and Big Data companies using the network-of-excellence instrument or similar. Establish standard benchmarks It is difficult for Industry to assess the benefits of using novel hardware. We propose establishing benchmarks to compare current and novel architectures using Big Data applications. Identify and build accelerated building blocks We propose to identify often-required functional building blocks in existing processing frameworks and to replace these blocks with (partially) hardware-accelerated implementations. Investigate intelligent use of heterogeneous resources With edge computing and cloud computing environments calling for heterogeneous hardware platforms, we propose the creation of dynamic scheduling and resource allocation strategies. Continue to ask the question – Do companies think that hardware and networking optimizations for Big Data can solve the majority of their problems? As more and more companies learn how to extract value from Big Data as well as determine which business models lead to profits, the number of service offerings and products based on Big Data analytics will grow sharply. This growth will likely lead to an increase in consumer expectations with respect to these Big Data-driven products and services, and we expect companies to run into more and more undesirable performance bottlenecks that will require optimized hardware.

D5.3 Roadmap v23
13
Network: Beyond the backbone, edging out 3the competition
3.1 Scope of network architecture The network is the most pervasive element of any modern technology-based business, and network optimizations targeted at Big Data could profoundly affect those businesses focused on analytics and beyond. However, these optimizations may not be as straightforward as the employment of accelerators for a specific Big Data workload due to emerging trends in “softwarization” and virtualization of conventional networking appliances. As such, we will explain the potential of optimizations for Big Data with innovative technologies applied to these appliances - specifically routers and switches - as related to this virtualization, and from there explore advancements in the area of interconnects, new materials and beyond. Our analysis will consider network requirements for executing Big Data workloads, be they inside a large public cloud, a private corporate data center or even in a future high performance / Big Data embedded system. We will examine these requirements from the perspective of the “data receiving end”, meaning that we will initially limit our scope to the network communication inside of the Data Center. As a result, we will only consider the nascent IoT sensors market, the Internet or mobile infrastructure challenges faced by the global telecom networks, and the actual access to the data by businesses (including regulatory & privacy concerns) from this perspective. After a brief survey of the market and current trends, we define several industry user profiles and summarize their respective concerns and requirements related to Big Data as gathered through our interviews and other publicly available information sources such as product roadmaps, published papers and international conferences. Additionally, for each profile, we describe the potential impact to overcoming the previously mentioned concerns via action. The roadmap proposals for networking are the result of this analysis.
3.2 Where we are today: Market trends and main actors The “network” consists of multiple functions embedded at different layers spread across many physical devices ranging from the server motherboard and interface peripherals to the top of rack switches, routers and the operator infrastructure. Until now, the networking hardware lifecycle has been driven by the quest for increasing bandwidth. But today’s market landscape is rapidly changing under the pressure of demand coming from Big Data, mobile phones and IoT combined requirements.
3.2.1 Network appliance hardware: from specialized to bare metal To get a sense of what this business globally represents, we can look at the router and switch market as a proxy indicator for the leading companies. In 2016, the switch market is forecast to reach $26 billion [Del15a] driven by large data center deployments. The interesting shift is that while the majority of revenue is for 10GE, the 40-100GE is forecast to top $3 billion by 2016, with 100GE adoption by major players as early as 2015 [Del15b].
D5.3 Roadmap v23
14
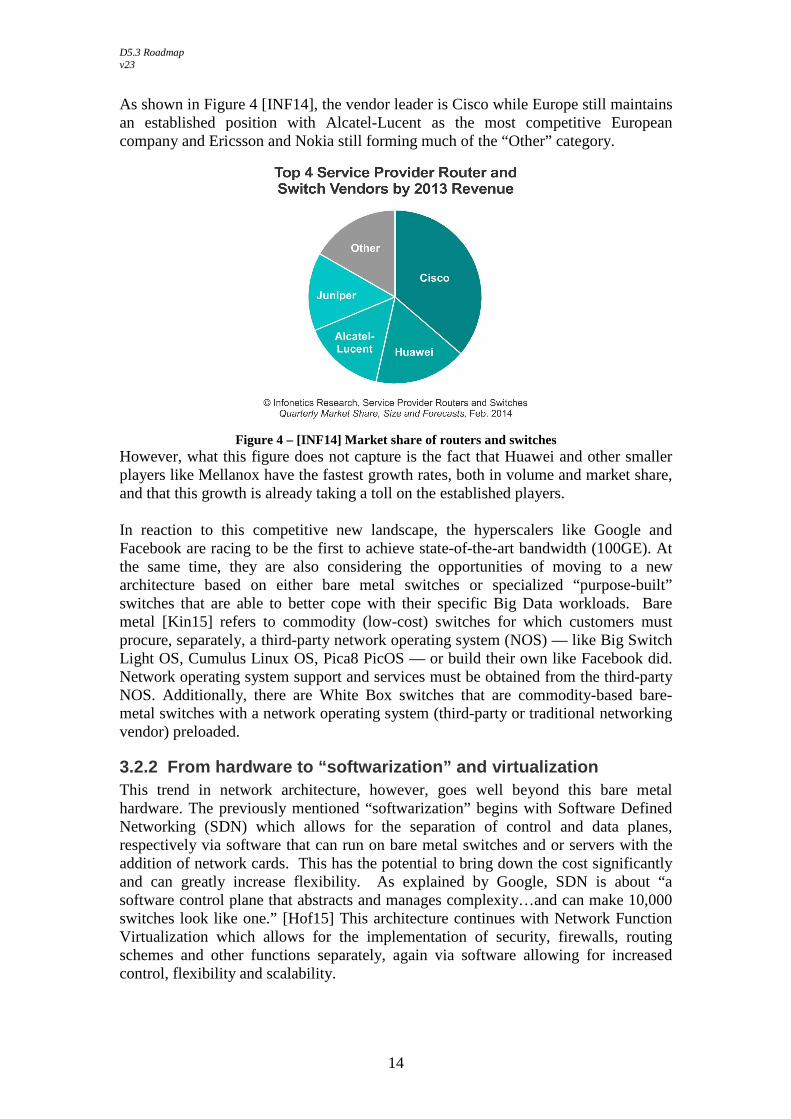
As shown in Figure 4 [INF14], the vendor leader is Cisco while Europe still maintains an established position with Alcatel-Lucent as the most competitive European company and Ericsson and Nokia still forming much of the “Other” category.
Figure 4 – [INF14] Market share of routers and switches
However, what this figure does not capture is the fact that Huawei and other smaller players like Mellanox have the fastest growth rates, both in volume and market share, and that this growth is already taking a toll on the established players. In reaction to this competitive new landscape, the hyperscalers like Google and Facebook are racing to be the first to achieve state-of-the-art bandwidth (100GE). At the same time, they are also considering the opportunities of moving to a new architecture based on either bare metal switches or specialized “purpose-built” switches that are able to better cope with their specific Big Data workloads. Bare metal [Kin15] refers to commodity (low-cost) switches for which customers must procure, separately, a third-party network operating system (NOS) — like Big Switch Light OS, Cumulus Linux OS, Pica8 PicOS — or build their own like Facebook did. Network operating system support and services must be obtained from the third-party NOS. Additionally, there are White Box switches that are commodity-based bare-metal switches with a network operating system (third-party or traditional networking vendor) preloaded.
3.2.2 From hardware to “softwarization” and virtual ization This trend in network architecture, however, goes well beyond this bare metal hardware. The previously mentioned “softwarization” begins with Software Defined Networking (SDN) which allows for the separation of control and data planes, respectively via software that can run on bare metal switches and or servers with the addition of network cards. This has the potential to bring down the cost significantly and can greatly increase flexibility. As explained by Google, SDN is about “a software control plane that abstracts and manages complexity…and can make 10,000 switches look like one.” [Hof15] This architecture continues with Network Function Virtualization which allows for the implementation of security, firewalls, routing schemes and other functions separately, again via software allowing for increased control, flexibility and scalability.
D5.3 Roadmap v23
15
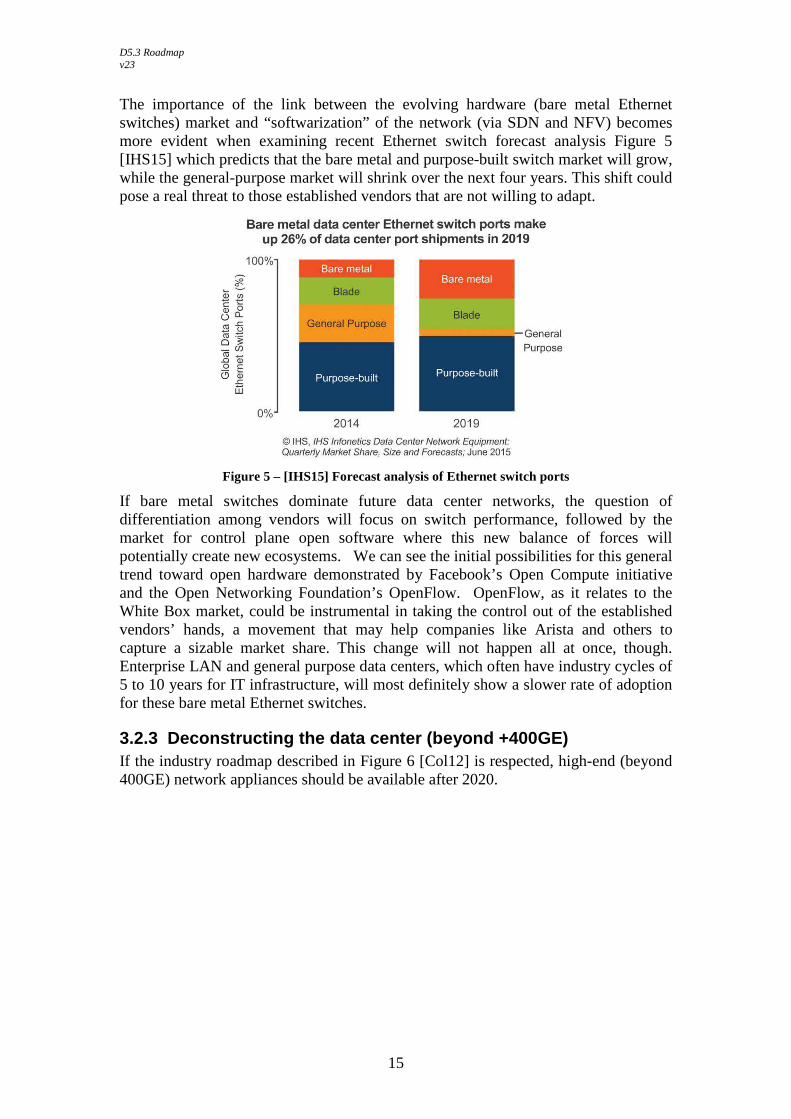
The importance of the link between the evolving hardware (bare metal Ethernet switches) market and “softwarization” of the network (via SDN and NFV) becomes more evident when examining recent Ethernet switch forecast analysis Figure 5 [IHS15] which predicts that the bare metal and purpose-built switch market will grow, while the general-purpose market will shrink over the next four years. This shift could pose a real threat to those established vendors that are not willing to adapt.
Figure 5 – [IHS15] Forecast analysis of Ethernet switch ports
If bare metal switches dominate future data center networks, the question of differentiation among vendors will focus on switch performance, followed by the market for control plane open software where this new balance of forces will potentially create new ecosystems. We can see the initial possibilities for this general trend toward open hardware demonstrated by Facebook’s Open Compute initiative and the Open Networking Foundation’s OpenFlow. OpenFlow, as it relates to the White Box market, could be instrumental in taking the control out of the established vendors’ hands, a movement that may help companies like Arista and others to capture a sizable market share. This change will not happen all at once, though. Enterprise LAN and general purpose data centers, which often have industry cycles of 5 to 10 years for IT infrastructure, will most definitely show a slower rate of adoption for these bare metal Ethernet switches.
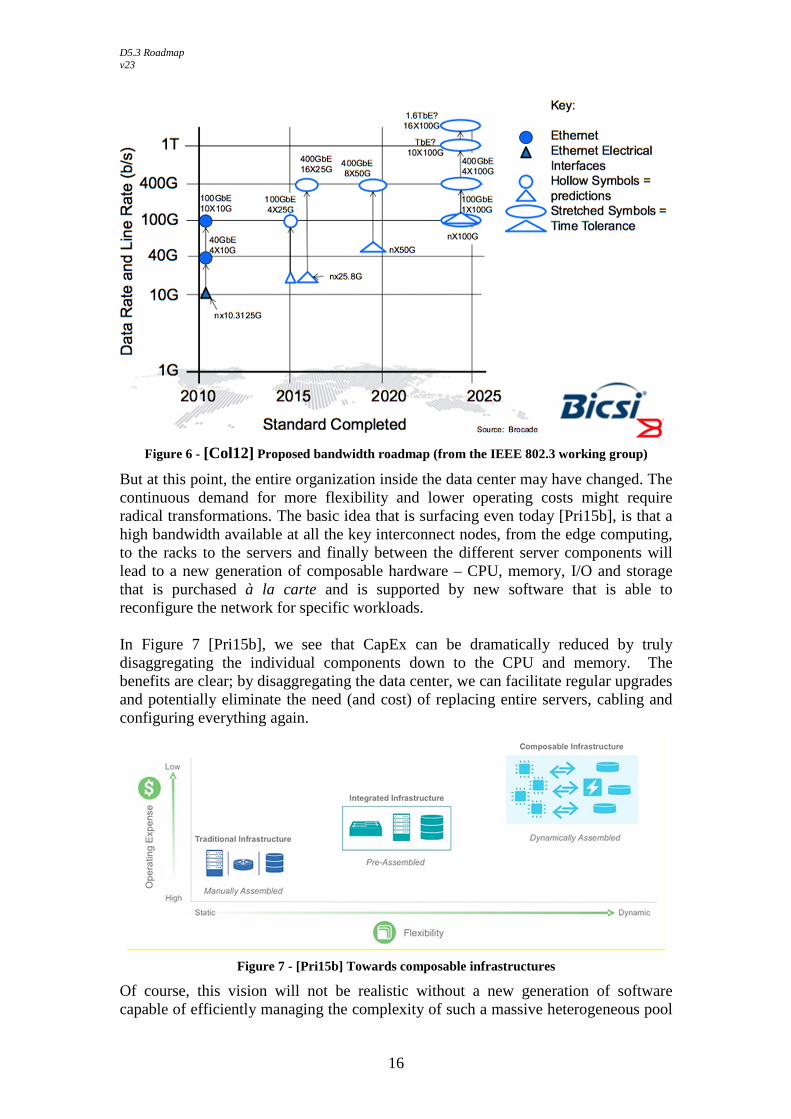
3.2.3 Deconstructing the data center (beyond +400GE ) If the industry roadmap described in Figure 6 [Col12] is respected, high-end (beyond 400GE) network appliances should be available after 2020.
D5.3 Roadmap v23
16
Figure 6 - [Col12] Proposed bandwidth roadmap (from the IEEE 802.3 working group)
But at this point, the entire organization inside the data center may have changed. The continuous demand for more flexibility and lower operating costs might require radical transformations. The basic idea that is surfacing even today [Pri15b], is that a high bandwidth available at all the key interconnect nodes, from the edge computing, to the racks to the servers and finally between the different server components will lead to a new generation of composable hardware – CPU, memory, I/O and storage that is purchased à la carte and is supported by new software that is able to reconfigure the network for specific workloads. In Figure 7 [Pri15b], we see that CapEx can be dramatically reduced by truly disaggregating the individual components down to the CPU and memory. The benefits are clear; by disaggregating the data center, we can facilitate regular upgrades and potentially eliminate the need (and cost) of replacing entire servers, cabling and configuring everything again.
Figure 7 - [Pri15b] Towards composable infrastructures
Of course, this vision will not be realistic without a new generation of software capable of efficiently managing the complexity of such a massive heterogeneous pool

D5.3 Roadmap v23
17
of resources – each resource potentially located anywhere in a data center. This could lead to interesting opportunities for SMEs, especially if we can help to reinforce the trend toward open hardware and networking and potentially move the ecosystem out the hands of the big vertical chip makers.
3.3 Where we want to be
3.3.1 Industry pains and expected gains In our survey, we have identified the following categories of industrial users for which we have found the corresponding major concerns. The information is conveniently captured in the following tables, and organized around two main areas:
• “Pains” identifies the root cause of the problem beyond the obvious ones (i.e. not enough revenue, too many taxes, …)
• “Gains” captures the concrete benefits that could be achieved if some of the current pains are removed.
The information captured at this stage (with a focus on the network) is not always directly amenable to solutions, as some specific problems could also come from a wrong business model, regulatory constraints and so on. But it is important that any solution must at some point be connected to these pains and the impact will certainly be measured against the expected gains. The first category of users consists of those using Big Data infrastructure be it in the Cloud or on Premises. For this category, the network is both an enabler and a cost.
Big Analytics developers / customers
Infrastructure (IaaS) or Platform As
a Service (PaaS) users
Examples: Company 1, Company 4, Company 7, Company 9, Company 11, Company
12, Company 15, Company 17, Company 20, Company 24, Company
28, Company 52, Company 64, Company 74, Company 101
Pains • Cost of using the network grows faster than
revenue generated from business • Lack of network control / flexibility compared to
application needs (semantic gap) • Complex architecture designs required to
compensate for lack of “reliability”
Gains • Lower latency means faster end-to-end
performance • Increase in available bandwidth can be
translated into better global efficiency for workloads that are I/O bound
• More power efficient datacenters will decrease overall TCO and possibly lead to better offerings for Users
• Low power devices also relevant for edge computing
The second user profile is focused on the “offer” side of the market. These users must make a sustainable business out of operating a data center and providing Cloud or Virtualization services. The spectrum is now quite large, both in size and offerings, but these users generally still share a common set of concerns with respect to the network.

D5.3 Roadmap v23
18
In our interviews with large Telcos, we were surprised to learn how cautious they are before adopting new technologies. They prefer established industry standards and do not express (at least publicly) specific needs for their networks. The roadmaps for these Telcos are based almost entirely on software enabled services like Virtualization and Open Stack deployments. They see Big Data as an additional business opportunity and they want to leverage their existing data center infrastructure capabilities to match this new demand, essentially by providing new services to match those of Amazon or Microsoft. On the other hand, smaller operators seem to be willing to take more risks, and invest in new hardware but only if they can at the same time decrease the cost of operating their network in order to stay competitive.
Data center operator (IaaS, VPS hosting, private cloud)
Examples:
Company 29, Company 30, Company 27, Company 47, Company 81,
Company 96, Company 112
Pains • Bandwidth within and between datacenters or
between datacenter and customer is the core issue.
• Cost of operation too high, networking a growing (in %) part of it.
• 100GE is needed now, but at the cost of 10GE. • Network seen as the “weakest link” in terms of
reliability, backup infrastructure is costly. • Security, a major concern but also a potential
differentiator. • Energy efficiency is a nice-to-have for data
centers, but not as important as bandwidth, etc.
Gains • Increased interest in open hardware opens the
door to many new opportunities. • Open Flow could be implemented as a cost
cutting solution, but there is still the need to be a way to prove its value (required skills, costs difficult to evaluate).
• More bandwidth for spine network but coupled with flexible allocation at top of racks to match the flexibility required in Big Data workloads.
The third profile is composed of equipment vendors, both from the established industry, but also from a growing ecosystem of new players. In this last category, there are two extremes situations: on one side the hyperscale internet companies like Google or Facebook and on the other side a series of smaller shops with highly innovative products or solutions, comprised of not only startups but also more traditional chip makers like Intel. These two communities are linked by a common interest around open hardware designs and a strong interest in “softwarization” of the networking functionalities. The driver in this case, is to provide cheap hardware and to compensate for the lack of flexibility through software.

D5.3 Roadmap v23
19
Networking hardware device makers, designers and providers
Examples: Company 65, Company 75
Pains • Cisco and others in the sector are worried about
strong Asian competitors, new entrants • Googles and others are building everything
themselves due to the inability to find in the market what they need
• NIC chip designers & network start-ups struggle with:
o Market access (telco) o Finding the right differentiators
(i.e. matching customer needs) o Costs of dedicated HW design
Gains • Large adoption of open hardware • Efficient hardware supplemented by new software
for control and data plane attractive to early adopters
• HW to provide lower port to port latency • Progress in optical networking technologies
At this point in time, we simply cannot ignore what companies like Google and Facebook are doing. They are already moving their data center networks to the next generation of hardware. As they are often the first to see the problem, they are often the first to solve the problem. What these early adopters say is an important indicator of how the rest of us will solve these problems down the line. Right now, Facebook is very focused on their open hardware initiative, OpenCompute, [OpenCompute] that pushes for decoupling the software from the hardware in the network switch business, while at the same time moving toward disaggregated network architecture as quickly as possible. Here is what Najam Ahmad, Director of Operations at Facebook, has to say [Ahm15] about the problems they have seen while transitioning to 100GE: “In the spine, we use a lot of 40 Gb/sec today, but to the NIC is still 10 Gb/sec. As that NIC goes to 25 Gb/sec and 50 Gb/sec, that forces increases upstream. … What happens in the 400 Gb/sec timeframe?” He explains how by solving one problem, they are simply moving the bottleneck, the next of which seems to be the optical interconnects. “What we have to spend more time is on the optics. With this disaggregated architecture, you have hundreds of thousands of optical interconnects, this becomes a much more significant part of your spending in the datacenter than switching is.” If Facebook is seeing their next limiting factor in the cost of the DCI or Data Center Interconnect, then we can be certain that the rest of us will come up against this same problem. However, it is having the problem that will drive companies to come up with solutions. In other words, hyperscaler-defined solutions are going to make their way into our data centers and eventually the consumer market, so we had better be ready for them.

D5.3 Roadmap v23
20
3.3.2 Key findings The following diagram summarizes the key objectives to be addressed through the actions recommended in the next section.
3.4 How we are going to get there
3.4.1 TRL > 5: Accelerating adoption of current tec hnologies TRL > 5 relate to mature technologies and established standards like 10GE or Infiniband. In this case, the objective is to prioritize low power and low latency of software-controlled switches.
3.4.1.1 Create the conditions for affordable low po wer network appliances There is already a strong interest in low power network appliances. Cloud providers and enterprise data centers will facilitate the adoption of such appliances if the power reduction is considerable, even if there is no significant increase in bandwidth. Europe hosts some very innovative companies, which are mainly focusing their businesses today on the high-end, embedded and HPC markets. This know-how in FPGA designs or low-power, high-performance CPUs bears a significant advantage for entering the next generation of high performance networking market. That said, it is simply too difficult to enter the increasingly specialized networking business as a young company. One of the pains often cited by these start-ups is the fact that it is nearly impossible to find customers that are willing to support their initial R&D effort.
3.4.1.2 Action plan We have combined the actions to promote the creation of affordable low power network appliances in conjunction with programmable hardware in the section to follow, 3.4.1.4 below.
• Objective: Reduction in power / latency
• 10x Energy reduction for the network infrastructure
• Affordable 10/40 Gbps, 100us latency (node-to-node)
• Increase investment in "programmable networking hardware"
TRL >5 Accelerate adoption
TIMEFRAME: Now
• Objective: New generation hardware, promote open hardware movement
•2x Energy reduction (20x compared to now)
• 100 GE, 10 us
• Data Center Interconnect disaggregation
3 < TRL < 5 Prepare next
generation
TIMEFRAME: in 5 years
• Objective: New materials R&D, new virtualized functions
• 400+ GE, 1us
• New materials, progress in silicon photonics, spintronics
• The "composable infrastructure" becomes a possibility
TRL < 3 Anticipate future challenges
TIMEFRAME: in 10 years

D5.3 Roadmap v23
21
3.4.1.3 Promote programmable network appliance hard ware However, effort to build less power hungry devices alone will not be enough. Network improvements must evolve with architecture, ideally supported by different use cases to address the diversity of the workloads. These new kinds of workloads found in Big Data applications, the disaggregation of storage or the need for more stream-based analytics puts a huge, but different, pressure on the network. In recent years, we have seen a strong trend toward open hardware that has demonstrated the value of simpler efficient hardware designs, coupled with dedicated software. We also see this approach applied to networking, first through the adoption of SDN and then as OpenFlow as a standard for programming data paths directly into networking equipment. OpenFlow allows for the use of commodity hardware for control plane decision-making and inexpensive programmable switches for packet forwarding. Progress is still needed on the OpenFlow API and design or implementations for different hardware will be needed. But coupled with this new generation of programmable hardware, a new market for early adopters and cloud providers willing to move away from the expensive vendor appliances might be created. Reducing latency by improving the low network layers is necessary but must be accompanied by a complete review of the software architecture so that the benefits are actually visible at the level of the application. This is particularly true in the case of Big Data software stacks. To date, much progress has been made by reducing slow disk usage and moving as much data as possible into memory, but there are still many inefficiencies that are open for improvement. For example, ScyllaDB proposes a 10x performance improvement over Cassandra, (a commonly used noSQL database for very large datasets), while preserving compatibility by simply moving from a Java-based implementation to C++ in addition to using a direct data path between the network interface and the application memory. Another interesting evolution can be seen in the HPC community where Mellanox is working to shift parts of the MPI responsibilities directly into the switch [Pri16]. In essence, Mellanox is working to move compute as close to the network as possible, to which we should respond: Could this be replicated for the Big Data architectures? Both of these examples demonstrate how critical it is to address the network concurrently with the architecture evolution, while applying different use cases to address the diversity of the workloads.
3.4.1.4 Action plan In order to promote the creation of affordable low power network appliances in conjunction with programmable hardware, we recommend short term actions that facilitate projects where:
• A Hardware Company or Telco willing to develop a new network appliance targeting the Cloud Computing market can work with
• A Cloud Operator looking for cost reductions and differentiators to attract • A Big Data Customer able to provide data and use cases

D5.3 Roadmap v23
22
• Supported by Academics and SMEs interested in validating new OpenFlow functionalities or new software designs
• For testing at scale an end-to-end optimized solution. As an example:
• Kalray [Kalray] wants to expand its many-core SMARTNIC product line, which currently provides 8x10GE for less than 20W, a 10x improvement over traditional vendor switches;
• This might interest a Cloud provider like OVH, which is aggressively looking at reducing its operational costs [OVH], thus increasing its vendor independence and expanding its customer base outside its traditional VPS hosting & CDN business;
• Based on the use-case and data provided by a customer, a sandbox cluster can be setup so that;
• Researchers at the INRIA Sophia-Antipolis can validate some of their ideas about new efficient OpenFlow routing modes presented in [Ngu14].
The outcome of such projects could serve as a starting point to push a de facto standard and build on a larger ecosystem, such as the Open Networking Foundation (ONF)1 and help bootstrap the emergence of highly optimized software.
3.4.2 TRL 3 - 5: Preparing the next generation For TRL between 3 and 5, the danger zone known as the Innovation “Valley of Death”, it is then logical to double the effort on current technologies with the same kind of action plan, but now targeting new hardware and software.
3.4.2.1 Take advantage of the convergence of HPC an d Big Data interests
As we move toward implementing 100GE interconnect while reducing the energy and latency, the network appliance hardware will have to evolve from a 32-bit to 64-bit (micro-architecture) and 20nm to 14nm (technology). With this new compute power available inside a switch, another round of opportunities for implementing network functions in software will be possible. We propose that HPC and Big Data communities work together to co-design this novel network appliance hardware, and then differentiate to meet the respective needs of their communities in software. The combined interest from both these communities would provide a larger customer base and lower the risk for hardware companies unwilling to focus on “niche markets”. We are already witnessing some transformations in this direction via initiatives like “CaffeOnSpark” [Caf16] from Yahoo. CaffeOnSpark takes advantage of state-of-the-art Big Data architecture for deep learning while at the same time utilizing a common set-up for HPC clusters (MPI on RDMA). The end result of this Big Data / HPC convergence is that training and inference tasks may be performed on a single cluster instead of two separate clusters which both reduces system cost and complexity.
1However, we should be cautious concerning such organizations: besides Ericsson, there are few established European companies or startups currently referenced by the ONF, pointing at a lack of interest and/or awareness of the potential benefits of being part of this industry effort.
D5.3 Roadmap v23
23
3.4.2.2 Action plan Under these conditions, we recommend an initiative that is oriented towards a converged Big Data / HPC networking hardware product line with differentiators implemented in software. This could be a key business enabler for European companies willing to compete with the market leaders.
3.4.2.3 Prepare for Data Center Interconnect (DCI) disaggregation
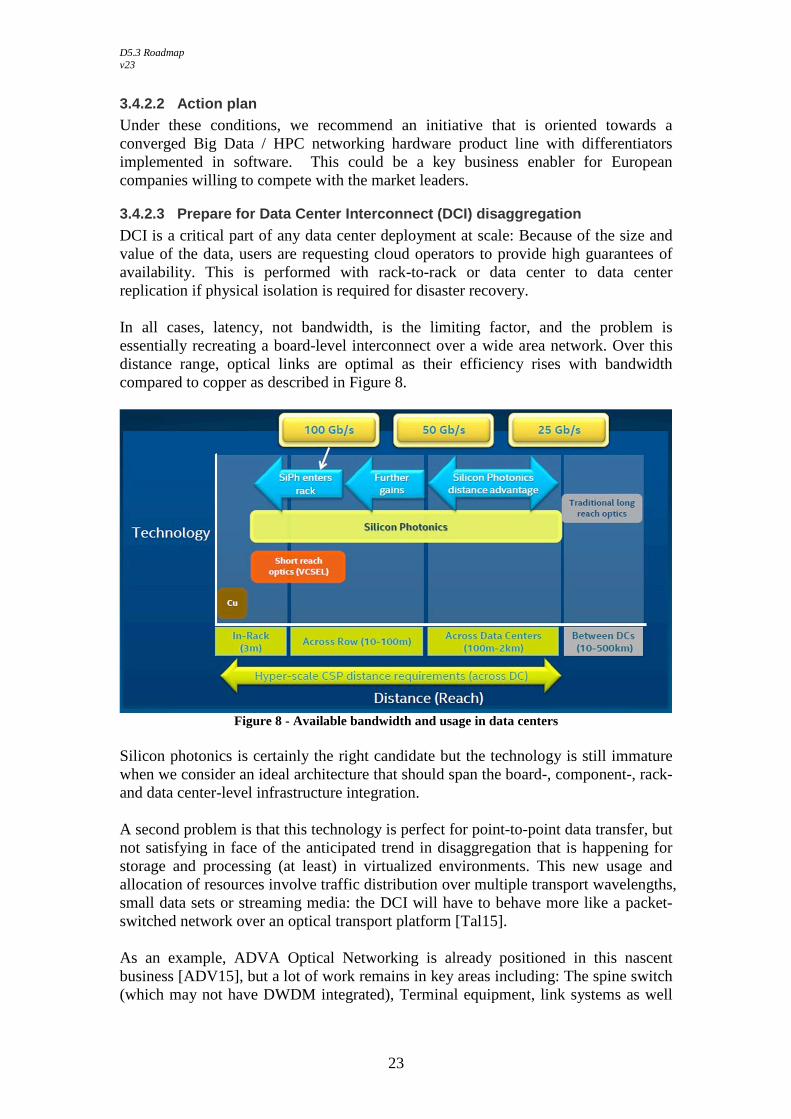
DCI is a critical part of any data center deployment at scale: Because of the size and value of the data, users are requesting cloud operators to provide high guarantees of availability. This is performed with rack-to-rack or data center to data center replication if physical isolation is required for disaster recovery. In all cases, latency, not bandwidth, is the limiting factor, and the problem is essentially recreating a board-level interconnect over a wide area network. Over this distance range, optical links are optimal as their efficiency rises with bandwidth compared to copper as described in Figure 8.
Figure 8 - Available bandwidth and usage in data centers
Silicon photonics is certainly the right candidate but the technology is still immature when we consider an ideal architecture that should span the board-, component-, rack- and data center-level infrastructure integration. A second problem is that this technology is perfect for point-to-point data transfer, but not satisfying in face of the anticipated trend in disaggregation that is happening for storage and processing (at least) in virtualized environments. This new usage and allocation of resources involve traffic distribution over multiple transport wavelengths, small data sets or streaming media: the DCI will have to behave more like a packet-switched network over an optical transport platform [Tal15]. As an example, ADVA Optical Networking is already positioned in this nascent business [ADV15], but a lot of work remains in key areas including: The spine switch (which may not have DWDM integrated), Terminal equipment, link systems as well

D5.3 Roadmap v23
24
as network management systems in order to make them highly integrated with little if any multiple peripherals, converters, amplifiers or multiplexers as is the case today.
3.4.2.4 Action plan As a means to preparing for this DCI disaggregation, we encourage the creation of an Optical DCI Open Architecture Initiative, inspired by open hardware and associated with suitable control software. Because this specific topic is not yet organized, there is room for establishing a de facto standard for the European companies. Involving large networking, telecom operators and optical network manufacturers will be a key success factor.
3.4.3 TRL < 3: Anticipating future challenges Even if the hardware/software designs do make progress according to the roadmap, some questions will remain unanswered:
• Can latency be reduced below the microsecond? • What does it mean for the network if the hardware accelerators are widely
used? Does the network become the next bottleneck? • What does finally having a 400GE network really mean?
In this paragraph, we put the emphasis on some possible future evolutions that can heavily disrupt the way the “data center” can be transformed. Because a low power, high performance network will allow distributed systems built with more sensors processing more data, connected to more remote resources, the very notion of “data center” will change: the future self-driving car will be a kind of “data center” in itself.
3.4.3.1 Anticipate the changes in Data Center desig n towards the composable infrastructure (and beyond)
Let’s suppose that environments will be more heterogeneous, denser and more applications or devices will share the same physical ports through virtualization. Now the physical interface becomes the new bottleneck. We recommend the following research topics for investigation in order to remove this next bottleneck:
• Adoption of new network topologies. High-end HPC clusters are using 2D or 3D torus topology networks that are cheaper than the classical fat-tree and links are on average shorter, providing lower latency, etc. Adopting this topology for Big Data workloads might be interesting, but will require non-trivial software modifications.
• New routing decision algorithms. With these new topologies, new “shortest path” or equivalent algorithms that go beyond what the current Internet Protocol (IP) can do (Spanning Tree and its variants) will be interesting to investigate
• Towards a more “functional” network. By separating the control and data planes, the routing decisions can be made “on the fly” and per packet. Leveraging this capability, an application might only declare its “intent” in terms of results (store this chunk of data into the database called x), without a priori knowledge of some target server/proxy/service on the network. The same way bio-inspired computing has led to advances in neuromorphic

D5.3 Roadmap v23
25
computing, there are some ideas to borrow from the “functional network” organization of the brain.
3.4.3.2 Action plan Our final recommendation in the area of Networking would be to facilitate partnership between Users, Data Center Operators and Network experts via research calls to explore and experiment with new network topologies, routing algorithms and higher level networking functions based on the research topics mentioned above. Based on the next generation of hardware, these projects will accelerate the return of experience and help reduce time to market by providing on the field validation. Associated with the composable infrastructure (see Figure 7), these approaches will open an entirely new set of opportunities. The basis for this research could be, for example, the RapidIO [Bol15] interconnect protocol which provides such flexibility, with the interesting addition over PCIe of supporting asymmetric links. These links not only require less power to transmit information, but the resulting pattern also fits nicely with the majority of Big Data workload data flows.
D5.3 Roadmap v23
26
Architecture: Accelerating compute for 4machine learning for analytics
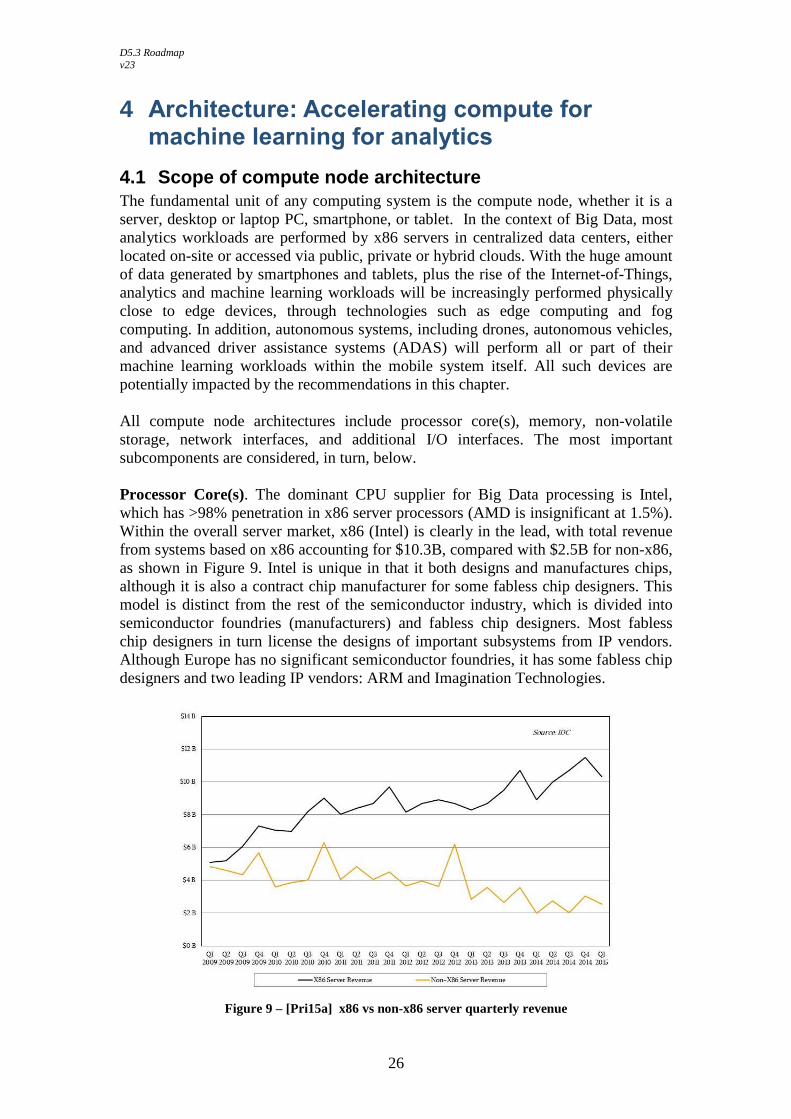
4.1 Scope of compute node architecture The fundamental unit of any computing system is the compute node, whether it is a server, desktop or laptop PC, smartphone, or tablet. In the context of Big Data, most analytics workloads are performed by x86 servers in centralized data centers, either located on-site or accessed via public, private or hybrid clouds. With the huge amount of data generated by smartphones and tablets, plus the rise of the Internet-of-Things, analytics and machine learning workloads will be increasingly performed physically close to edge devices, through technologies such as edge computing and fog computing. In addition, autonomous systems, including drones, autonomous vehicles, and advanced driver assistance systems (ADAS) will perform all or part of their machine learning workloads within the mobile system itself. All such devices are potentially impacted by the recommendations in this chapter. All compute node architectures include processor core(s), memory, non-volatile storage, network interfaces, and additional I/O interfaces. The most important subcomponents are considered, in turn, below. Processor Core(s). The dominant CPU supplier for Big Data processing is Intel, which has >98% penetration in x86 server processors (AMD is insignificant at 1.5%). Within the overall server market, x86 (Intel) is clearly in the lead, with total revenue from systems based on x86 accounting for $10.3B, compared with $2.5B for non-x86, as shown in Figure 9. Intel is unique in that it both designs and manufactures chips, although it is also a contract chip manufacturer for some fabless chip designers. This model is distinct from the rest of the semiconductor industry, which is divided into semiconductor foundries (manufacturers) and fabless chip designers. Most fabless chip designers in turn license the designs of important subsystems from IP vendors. Although Europe has no significant semiconductor foundries, it has some fabless chip designers and two leading IP vendors: ARM and Imagination Technologies.
Figure 9 – [Pri15a] x86 vs non-x86 server quarterly revenue

D5.3 Roadmap v23
27
Memory. Regarding memory components, consolidation among DRAM manufacturers has reduced the number of suppliers to three: Samsung (47%), SK Hynix (28%), and Micron (19%) [TRE15]. Given the high fixed costs [Shi15], low margins and extensive patent cross licensing, it is unrealistic to expect a European company to compete in this market, or in the similar market in NAND flash. There may, however, be an opportunity for European entrants in advanced non-volatile memory (NVM) technologies, since relevant European research is close to market, but a successful European company would likely soon be acquired by one of the big three memory companies.
4.2 Where we are today: Market trends and main actors Regarding Big Data compute node hardware, there are three important trends to consider. The first is toward heterogeneous computing. Several European companies may potentially benefit from a trend towards heterogeneity, either as fabless/IP vendors or as suppliers of programming tools or languages. Most European companies in this space, however, will be too small on their own to overcome the significant difficulties in programmability and the risk of vendor lock-in through proprietary programming languages and frameworks. A second major trend is towards increased integration within the compute node, with more and more functionality being integrated into a single CPU package. Given Intel’s dominance in Big Data server processors, smaller fabless/IP vendors will therefore have their profitability squeezed by a single dominant customer. Finally, we see the hyperscalers pursuing verticalization, in order to benefit not only from economies of scale but also from hardware–software co-design. In comparison with hyperscalers such as Google, Amazon and Facebook, the European industry is highly fragmented, and there is a considerable disconnect between data-driven companies, analytics companies and technology providers. We discuss each of these trends in detail in the sections that follow.
4.2.1 The march toward heterogeneous systems There is a noticeable movement away from general-purpose architectures towards heterogeneous systems and specialized accelerators. This change is mainly driven by a slowdown in Moore’s Law [Hua15], the exponential growth in the number of transistors per chip that has been consistently followed from the 1960s until now. As recently pointed out in Nature, “The doubling [in transistors per chip] has already started to falter, thanks to the heat that is unavoidably generated when more and more silicon circuitry is jammed into the same small area” [Wal16]. System integrators are therefore looking to heterogeneous systems, which combine multiple kinds of processors and accelerators, including GPUs, many-cores, FPGAs, and application-specific accelerators, in order to improve performance or energy efficiency. Several European companies seem poised to benefit from a diverse accelerator market, including fabless companies (Movidius and Kalray), IP vendors (ARM and Imagination Technologies), as well as the suppliers of programming tools, abstractions or languages (Xtremlogic, Mitrionics or Maxeler). Despite the potential benefits of moving toward heterogeneous systems, the barriers to entry are substantial. Perhaps the most obvious barrier is the cost of purchasing accelerator hardware, such as FPGAs or GPGPUs. More important than the actual

D5.3 Roadmap v23
28
equipment costs is the fact that these systems introduce significant software complexity. The effort to run a Big Data application on these systems requires specialized skills and usually knowledge of hardware due to the complex nature of the available tools and programming models. Even after investing in the appropriate human capital, there are still no guarantees of achieving a Return on Investment (ROI), as these systems often require hand optimization to attain near theoretical performance. On top of this, software for heterogeneous systems is not portable and subject to vendor lock-in. For example, once an application has been ported and optimized for one type of heterogeneous system (e.g. GPU-based), a company would have to start again from scratch in order to make that same application run on a different heterogeneous system (e.g. FPGA-based). In addition, many open-source communities are philosophically opposed to accepting hardware-specific software patches [Cor05], meaning that only open standard languages and APIs are likely to be supported by general software beyond specific driver modules connected using general-purpose (and often) restrictive interfaces. Finally, many of these new technologies have yet to be proven in terms of performance due to the lack of standard real-world benchmarks. The overarching result is that in order for European software vendors to adopt heterogeneous systems, they would need to keep pace with each successive new candidate technology, which is not economically viable. This is evident in the results of our project surveys, in which the majority of European software vendors reported these they had no hardware roadmap and they preferred to wait until new technologies became widely accepted and inexpensive commodities. Upon further research, we found a limited number of companies that were engaging with new technologies, including SAP with Intel and Neo4j with IBM, but these companies were the exceptions to the rule.
4.2.2 Specialization and vendor lock-in General-purpose GPU (GPGPU) is a maturing technology with a growing rate of adoption, especially in the area of high-performance computing (HPC). GPUs are especially suitable for computer vision and deep learning and in particular for training convolutional neural networks. Facebook is already using GPUs for face recognition while in the automotive market; Nvidia is pushing GPUs in the DRIVE PX on-board compute platform for computer vision and deep learning for Advanced Driver Assistance Systems (ADAS) [DRI15]. The GPGPU market is currently dominated by Nvidia (>95% of GPU-accelerated systems in the TOP500 use Nvidia), and their next target market is the server market. That said, GPGPUs have not yet achieved wide-scale penetration into data centers due an uncertain ROI. Small to medium-sized data center operators are unwilling to deploy GPGPUs at large scale, as the power consumption is too high and utilization too low to justify the investment. Moreover, even at the level of GPGPU implementation, there are elements of vendor lock-in. Nvidia’s market lead is sustained through aggressive promotion of its proprietary CUDA programming language, while other programming languages, namely OpenCL, are supported by other GPGPU vendors including AMD and ARM. As is the case for moving from a GPGPU-based heterogeneous architecture to an FPGA-based one, there is considerable Non-recurring Engineering (NRE) cost required for a change in GPU vendor.

D5.3 Roadmap v23
29
FPGAs (field-programmable gate arrays) were originally designed for ASIC prototyping. An FPGA device can be programmed at a later time, after its manufacture, to emulate hardware (hence “field programmable”). The possibility of being able to re-implement functionality on-the-fly makes FPGAs a prime candidate for the server market where services are currently evolving rapidly. More important, however, is their potential to “shoulder a large proportion of the processing burden while reducing power consumption”. The Catapult project was designed to speed up Microsoft’s Bing web ranking algorithm using FPGAs, and it resulted in Bing’s web ranking being achieved using approximately half the number of servers that were required previously [Put14]. The success of this architecture has led to its implementation in Microsoft’s production data centers largely driven by the significant reduction in Total Cost of Ownership (TCO) as well as increased sustainability. Upon acquiring Altera, Intel said that it expected a third of cloud service providers to be using hybrid CPU–FPGA servers by 2020 [INT15]. Moreover, the implications of using FPGA heterogeneous systems are particularly clear with respect to Big Data–related tasks that are similarly suited to hardware acceleration [Fee15]:
• Image recognition and classification • Encryption and decryption • Video applications (e.g. encode and decode) • Cloud security • Load balancing • Internet key exchange • Deep learning and neural networks
That said, even more so than GPGPUs, FPGAs are expensive and difficult to program, meaning that the tools and programming models are not accessible to software developers: FPGA hardware programming abstractions expose the facts that FPGA hardware is inherently concurrent, timing is explicit, memory is subdivided into multiple distributed memory blocks, and communication between subsystems requires special hardware rather than shared memory [Bai15]. The potentially high NRE to develop FPGA-based accelerators means that adopting FPGAs is high risk and it has a potentially low ROI. We see the two major FPGA vendors finally starting to take this programmability issue seriously. Altera was the first to support OpenCL on its FPGAs. Xilinx has released High Level Synthesis tools like Vivado, in addition to adding support for OpenCL.
4.2.3 Integration inside the compute node A second clear trend for compute node architecture is for increased integration within the CPU node, in order to improve performance and reduce energy consumption. There are two approaches: System-on-Chip (SoC) and System-in-Package (SiP). A System-on-Chip (SoC) integrates a complete computing system onto a single silicon die. This approach has been used for some time in embedded systems, mobile phones and tablets, where space and power are at a premium and volumes are very high. The SoC approach is now being extended into the server market. Intel Xeon D integrates dual 10GE, PCIe, USB, and SATA (disk) interfaces. In addition, all companies that are supplying or will soon supply ARM-based server chips, such as Applied Micro, AMD, Broadcom and Qualcomm are adopting the SoC approach.

D5.3 Roadmap v23
30
Given the above trend for heterogeneous systems and specialization (Specialization and vendor lock-in 4.2.2), together with fast evolution in the Ethernet standard (see Section 3.2.3), investing in a market-specific server SoC is likely to be cost-prohibitive, unless the designer can support the SoC vertically through its business or address a very large-volume market (such as mobile). SoCs provide no flexibility: adding a new technology such as 40Gb Ethernet to a die that currently supports only 10GE requires a costly redesign, resulting in the loss of the NRE that was invested into the original die. In addition, an SoC must be implemented in its entirety using a single silicon process. Since the SoC includes the performance- and energy-critical processing cores, the entire die must be fabricated using a leading edge, i.e. expensive, silicon technology. An alternative approach is System-in-Package (SiP). Intel supports SiP for its foundry customers through a technology it calls Embedded Multi-die Interconnect Bridge (EMIB). A similar approach is 2.5D/3D integration using a silicon or organic interposer, which enables efficient high-bandwidth interfacing between multiple silicon dies (chiplets) inside the same package. The latter approach was pioneered by the EC EUROSERVER project [Euroserver], led by CEA, with partners including STMicroelectronics and ARM. EUROSERVER has led to two start-ups, one of which is commercializing a European solution for microservers [Kaleao], based on ARM cores and 2.5D integration. Having multiple dies in the same package provides flexibility in that faster evolving technologies may be separated from more slowly evolving ones and thus replaced without affecting the rest of the design. This means that new technologies such as 40GE could replace older ones without a need to re-engineer the whole die. In addition, market-specific products can be built from standard commodity compute chiplet(s) connected to specialized chiplet(s) providing accelerators and I/O interfaces, without the need to design an entire SoC. This flexibility may give smaller companies the opportunity to compete on a more level playing field with their standalone accelerator solutions, as there will be better integration into a state-of-the-art system. Finally, this 2.5D integration may allow European accelerators to be fabricated using less expensive silicon technologies on a separate die from the CPU while at the same time remaining closely integrated with the CPU, which must be fabricated using a leading edge process.
4.2.4 Verticalization and hyperscalers The final major trend is the increasing dominance of a small number of vertically-integrated companies that co-design all or parts of the server stack, to varying degrees, ranging from the user-visible software, through (Big Data) frameworks, down to system integration and potentially even chip design. Examples include Google, Apple, Facebook, Twitter and Amazon (“GAFTA”), plus Baidu, Alibaba and others, none of which is European. These companies have enormous market share and economies of scale, made more so through efficiencies from their vertically-integrated perspective. In Europe, however, the industry is fragmented, with a large disconnect between technology providers and analytics companies. Almost all analytics companies expressed that they have no hardware roadmap, take little notice of new hardware trends and are only looking at existing commodity hardware. Since Europe currently has no market share in server compute CPUs, there is limited opportunity for these companies to engage with the incumbent supplier(s). Technology providers need

D5.3 Roadmap v23
31
software vendor input into the design of future architectures and they face specific problems, such as the lack of labeled training data sets, the most comprehensive of which are being collected by vertically-integrated companies.2 This large disconnect between technology providers and analytics companies carries a significant risk of being left behind by the larger U.S. companies. Even when a company releases its technology as open-source software; e.g. TensorFlow, the public version is limited (in the case of TensorFlow to a single node). The concern is not just that Europe will fall behind, but that European companies will be put out of business.
4.2.5 Non-von Neumann A final, longer-term, trend is towards non-von Neumann computing architectures. The von Neumann architecture, defined in 1945 by John von Neumann and others, defines the fundamental architecture of a stored-program computer, consisting of a Central Processing Unit (CPU), memory containing both data and instructions, non-volatile storage, and input/output (I/O) interfaces. FPGAs are non-Von Neumann devices, at least when they are programmed using Hardware Description Languages (HDLs) such as VHDL and Verilog; but High-Level Synthesis (HLS) and OpenCL programmability mean that FPGAs are increasingly programmed in a von-Neumann style. New technologies, including resistive computing, neuromorphic computing, and quantum computing are fundamentally non-Von Neumann architectures. Defining the programming models for these devices is still an open research problem, with, as yet, no compatibility with existing software programming paradigms, tools, or software frameworks. Among non-von Neumann accelerators, this roadmap makes specific recommendations only for FPGAs and neuromorphic computing. Quantum computing, in particular, is still at very low TRL, and is subject to specific research funding mechanisms outside the context of Big Data. Neuromorphic computing originally referred to hardware operating using the same (analog) principles as the human brain, but the term is commonly used nowadays to refer to a computer architecture inspired by the brain, whether built from many-cores, analog electronics, custom CMOS, or new technologies such as memristors. Neuromorphic computing systems use a large number of primitive “neurons” to break the von-Neumann bottleneck, greatly reducing energy consumption [Cal13].The potential improvement in energy efficiency is illustrated by comparing IBM Watson, which won Jeopardy! in 2011 with a human brain. IBM Watson consumes 80 kW, whereas a human brain consumes only about 100 W. Neuromorphic devices are relevant for Big Data algorithms including those in computer vision and machine learning. A significant improvement in neuromorphic computing will enable new applications, including face recognition, target tracking (military), toys, automatic defect checking in manufacturing, market research, self-driving cars, and ADAS. Many research projects are working towards neuromorphic computing, including SpiNNaker and the Human Brain Project in Europe, the DARPA SyNAPSE project, Stanford Brains in Silicon, and Neuflow. Some large U.S. companies are working
2 Access to data is an important reason why a consortium of German automotive companies, including Audi, BMW and Daimler, bought Nokia HERE for $3.2B in 2015.

D5.3 Roadmap v23
32
seriously in this direction; e.g. IBM TrueNorth, Qualcomm Zeroth. European technology providers have expressed difficulty with the gap between research and the market, which has not yet been established, as well as difficulties in raising suitable investment funding. Quantum computers operate on a different basis from existing computers, both in theory, since they are not Turing machines, and in practice. Existing computers are based on (classical) bits, which always take a definite value 0 or 1. Quantum computing systems operate in terms of quantum bits (qubits), which are in a quantum superposition of both 0 and 1 at the same time [IQC]. Two qubits together hold four values at once (00, 01, 10, and 11), and increasing the number of qubits increases the power of the system at an exponential rate. Quantum computing has the potential to significantly enormously improve the performance of certain workloads. It is expected that machine learning will be transformed into quantum learning [Sim15a]. Significant progress has been made on basic quantum algorithms, beyond Shor’s algorithm for integer factorization and Grover’s algorithm for function inversion, to include Binary Welded Tree, Boolean Formula Algorithm, Ground State Estimation, and others [Kud13]. Prototype quantum computers already exist. Google operates a quantum computer, built by D-Wave, that can perform quantum annealing 100 million times faster than a conventional processor [Sim15a]. The quantum chip itself uses a fraction of a microwatt, but including the cooling system needed to operate it at an extremely low temperature close to absolute zero (80mK) increases the total system consumption to about 15 kW [Met15]. Microsoft [Sim14] and IBM [Sim15b] have similar quantum computing projects.
4.3 Where we want to be
4.3.1 Industry pains and expected gains The first category of actors consists of those using Big Data infrastructure be it in the cloud or on premises. Almost all companies in this category said that they did not have a hardware roadmap and that they are only interested in the current commodity architectures.
Big Analytics developers / customers
Infrastructure (IaaS) or Platform As a Service (PaaS) users
Examples:
Company 1, Company 4, Company 7, Company 9, Company 11, Company 12,
Company 15, Company 17, Company 20, Company 24, Company 28,
Company 52, Company 64, Company 74, Company 101
Pains • Difficult to compete with vertically integrated
companies that co-design software with hardware.
• Unable to benefit from FPGAs, GPUs and other accelerators, due to difficulty in programming and a lack of support in open-source Big Data frameworks/projects.
Gains • A broader range of services and service
models will be enabled through efficient use of highly-optimized hardware.
The second category of actors is that of data center operators. These users must make a sustainable business out of operating a data center and providing Cloud or

D5.3 Roadmap v23
33
Virtualization services. The spectrum is now quite large, both in size and offerings, but these users generally still share a common set of concerns with respect to the network. In comparison with U.S. companies, they are not willing to take much risk.
Data center operator (IaaS, VPS hosting, private cloud)
Examples:
Company 29, Company 30, Company 27, Company 47, Company 81,
Company 96, Company 112
Pains • Difficult to compete with vertical hyperscalers
such as Google, Amazon, Facebook and Microsoft that are working on Big Data frameworks that are highly optimized for their platforms. Even when released open source, the public version is limited.
• Google, Amazon, Facebook, Microsoft are already aggressively pushing GPGPUs and are interested in FPGAs, They have the economy of scale to solve the majority problems well before their European competitors.
• High risk and uncertain ROI from investing in FPGAs and GPGPU accelerators, due to large capital costs, complex tools and programming models, and specialized skills.
• Little visibility of new hardware technologies. • Difficulty in providing FPGA accelerators as a
service, due to IP block licensing business model and expensive license fees.
Gains • By reducing the risk and cost of using
accelerators, independent data centers operators will continue to be competitive.
A third group of actors is related to FPGA compilers and programming languages (XtremLogic and Mitrionics). A similar example is Maxeler, which sells Data Flow Engines (DFEs) which implement dataflow computing using their OpenSPL and MaxJ programming languages. Maxeler’s technology is currently implemented using FPGAs, so they may benefit from widespread FPGA accelerators-as-a-service.
Tools / abstractions / language providers
Examples: Company 51, Company
60, Company 63, Company 87
Pains • FPGAs and other accelerators are currently only
used in certain niches, such as financial services, oil/gas discovery, and bioinformatics.
Gains
• Increased adoption of FPGAs and Hardware Accelerators as a Service will increase the size of their target market.
The technology vendors find it difficult to engage European customers, and are affected by the fragmentation of the European market. Some face difficulties in proving the benefits of their solution, due to a lack of benchmarks, and high costs to port existing software to their architectures. These points are expanded upon in Section 5, Software.

D5.3 Roadmap v23
34
Hardware technology providers
Examples: Company 43, Company 44, Company 46, Company 49,
Company 52, Company 60, Company 79, Company 85, Company 93,
Company 105
Pains • Greater integration within the compute node will
make it harder for a standalone solution to compete in terms of performance and energy.
• Market dominance of Intel and vertically integrated hyperscalers (the only customers for integrated accelerator IP) will squeeze the profitability of independent technology providers.
• Will be hard to compete, in terms of performance, energy and applicability, with co-designed solutions designed by the vertically integrated hyperscalers.
• Risk of lock out by NVIDIA’s aggressive push of CUDA GPUs into automotive and drones (Movidius, Mobileye).
• Big data frameworks do not support specialized accelerators, making porting expensive. Many open-source communities are philosophically opposed to hardware-specific patches.
• Disruptive technology providers; e.g. in neuromorphic computing find it very difficult to create an ecosystem and raise suitable investment.
Gains • Adoption of ARM architecture or 2.5D SiP
integration would allow European companies to get their solutions or IP blocks into the server space.
• Coordinated action between technology providers would allow specialized accelerators to enter the server CPU package.
• Collaborative projects would help technology providers and potential customers to work together to prove the benefit from specialized accelerators.
4.3.2 Key findings The following diagram summarizes the key objectives to be addressed through the actions recommended in the next section.

D5.3 Roadmap v23
35
4.4 How are we going to get there
4.4.1 TRL > 5: Accelerate the adoption of heterogen eous systems
4.4.1.1 Reduce risk and cost of using accelerators
Over the next five years: We want to lower the barrier to entry for the adoption of heterogeneous systems (including lowering the risk and cost of using and / or providing HW accelerators as a service), so that (a) European users can learn how to exploit new hardware optimizations for Big Data, and (b) European technology providers can understand which products would help them advance in the area. Open source Big Data software projects should support accelerators efficiently and transparently; e.g. frameworks such as Apache Flink should easily use FPGAs. This will enable the adoption of accelerators in existing codebases. Approaches similar to the VINEYARD project and Quickplay should be encouraged to improve the usability of FPGAs. In particular, an approach for an “app-store” for FPGA IP blocks, is needed in order to enable useable FPGA accelerators-as-a-service.
4.4.1.2 Action plan As a means to reduce the risk and cost of using accelerators, we recommend collaborative projects that demonstrate significant (10×) increase in throughput per node through cross-layer optimization of real analytics applications using accelerators and other new technologies, with the involvement of end users, application providers and technology providers. These projects should include users potentially moving towards the cloud; e.g. analysis boxes for hospitals. A critical requirement will be a demonstrated ability to work with the relevant open source community to integrate software updates into mainline development. This project should provide mechanisms system to hide the programming complexity of the resulting heterogeneous system based on the hardware accelerators. Involvement of cloud providers is also necessary on the path to accelerators-as-a-service. Such research funding will encourage users and technology providers to engage with each other. For cloud providers it will reduce
• Objective: Accelerate adoption of heterogeneous systems
• Reduce risk and cost associated with taking advantage of heterogeneous systems
TRL >5 Accelerate adoption
TIMEFRAME: Now
• Objective: Ready the ecosystem for new generation hardware
• Promote mechanisms that abstract hardware complexity from software, including software-friendly development environments and open IP blocks
• Develop these mechanisms in direct collaboration with Big Data Industry applications and service providers.
3 < TRL < 5 Prepare next
generation
TIMEFRAME: in 5 years
• Objective: Ready the ecosystem for disruptive technologies
• Increase collaboration to pioneer neuromorphic and quantum computing in industry,
• Include the appropriate software stack approach
TRL < 3 Anticipate future challenges
TIMEFRAME: in 10 years

D5.3 Roadmap v23
36
the risk and improve the ROI of adopting accelerators and new technologies, allowing them to keep up with the large vertical hyperscalers. Additionally, Research projects should develop a unified software framework for acceleration in Big Data stacks, addressing the problems of the efficiency of abstractions.
4.4.2 TRL 3 - 5: Preparing the next generation hard ware
4.4.2.1 Encourage system co-design for new technolo gies As described in Section 4.2.3, silicon-in-package integration significantly reduces the NRE costs to design market-specific products, with I/O interfaces, memory interfaces, mix of processor cores, and so on, driven by evolving needs of big data. In Europe, this requires a close collaboration among IP providers and designers of accelerators (who need to be part of the silicon-in-package ecosystem), system integrators (who will be able to increase their differentiation), application providers (who should adapt their software to take advantage of new technologies and system architectures) and end users (who would benefit from higher performance per watt or per euro).
4.4.2.2 Action plan In order to encourage system co-design for new technologies, we recommend collaborative projects that bring together end users, application providers, system integrators and technology providers to demonstrate the potential for a significant (2–3×) increase in throughput beyond existing fully optimized solutions. In comparison with the projects in Section 4.4.1.2, the lower TRL means that the potential for improvement should be shown using small-scale prototypes, simulation and modeling. The purpose should be to integrate laboratory-proven technologies into a balanced system architecture, rather than developing new technologies themselves. A critical requirement will be a demonstrated ability for the software partners to work with the relevant open source community to integrate software updates into mainline development. The system architectures designed in these projects will allow European technology providers to offer leading products optimized for large big data markets, while having software support ensured through the application partners and open source software.
4.4.2.3 Create a sustainable business environment i ncluding access to training data
Over the next five years, Europe should encourage a sustainable business environment for European companies working in the area of accelerators. A significant issue is access to labeled training data for supervised learning, which is currently being collected by large non-European companies. This may also be felt by European cloud hosting companies, who will not be able to compete with machine learning as-a-service (MLaaS) offerings from Google, Amazon and Microsoft. Even if these companies and Facebook release their software as open source, they will not release the training data. It may be worthwhile to support training neural networks with proprietary data as a business.
4.4.2.4 Action plan Europe should address access to training data by a) encouraging the collection of open anonymized training data, b) encouraging the sharing of anonymized training data

D5.3 Roadmap v23
37
inside EC-funded collaborative projects, and c) when privacy concerns make this necessary, encouraging the end-user partner(s) to train the application/technology provider’s model(s) at user’s premises, without restrictions on future exploitation. To address the lack of information sharing, Europe should encourage interaction between hardware providers and Big Data companies using the network-of-excellence instrument or similar. This will allow sharing of expertise, so that hardware actors have access to application requirements (and visibility of training data) and application providers have early access to technology (FPGA, GPGPU, etc.).
4.4.2.5 Improve programmability of FPGAs Over the next five years, Europe should encourage the uptake of FPGAs by addressing the programmability challenge. FPGAs are currently developed using hardware-like languages, which are incomprehensible to most software developers. FPGA IP blocks are expensive, with large up-front licensing costs. Current FPGA vendors have not realized the potential for Big Data.
4.4.2.6 Action plan
Europe should encourage uptake of OpenCL and additional optimization and tuning tools. Europe should also fund research projects involving providers of tools, abstractions and high-level programming languages for FPGAs or other accelerators. These research projects should demonstrate the effectiveness of this approach using real applications from multiple industries. Europe should also encourage a new entrant into the FPGA industry, to be competitive with Intel/Altera and Xilinx. This activity could be coordinated with the BRAVE-NG initiative for FPGA fabrication for space applications, whose tools and devices will be made available for research and commercial exploitation. The results should be extended to mainstream markets, which do not require radiation hardening, and the devices should be fabricated in more advanced silicon technologies.
4.4.3 TRL < 3: Anticipating future challenges
4.4.3.1 Pioneer new markets for neuromorphic comput ing and increase collaboration
In the next five to ten years, Europe should pioneer neuromorphic computing in new markets. This will be especially important for (embedded) machine learning and autonomous learning in a constrained power budget, as well as new advanced applications of machine learning / artificial intelligence. A major problem is investment to bring new ICs to market.
4.4.3.2 Action plan For neuromorphic computing, the principal issue is the lack of a market ecosystem, with insufficient appetite for risk among venture capital firms (VCs) and few European companies with the size and clout to invest in such a risky direction. Collaborative research projects should bring together actors across the whole chain: end users, application providers and technology providers to demonstrate real value from neuromorphic computing in real applications. The issue is not research and development per se, but an interest from the end user in commercialization and an ongoing (lead customer) relationship after the end of the project.

D5.3 Roadmap v23
38
Other potential disruptive ideas should also be explored, always with a focus on bringing the solutions to market. Potential directions include hardware in-memory compression, memory-in-compute (similar to Micron’s Automata) and hardware stochastic computing.

D5.3 Roadmap v23
39
Software and beyond: Supporting hardware 5optimizations for Big Data
Most hardware devices cannot function (well) unless there is specific support in software. This creates a classic chicken-and-egg problem, since hardware is not viable until sufficient compatible software is available and hardware-specific software is not worthwhile until the hardware has been widely adopted [Fis09]. Any hardware roadmap must therefore carefully consider the relationships between hardware and its supporting software. With respect to this roadmap, accelerators and neuromorphic computing devices, for instance, require software modules to be rewritten and internal interfaces to be redesigned, in order to use the hardware. Heterogeneous systems and composable infrastructure, for instance, not only require low-level software support, but they also need the higher-level software to exploit the hardware in an intelligent way, in order to obtain high performance and low energy consumption. There is a large and complex ecosystem of open source software for Big Data, including databases, data analysis frameworks, machine learning libraries, programming languages, tools, and so on—See Figure 10. This enormous diversity makes it expensive for a hardware company to develop sufficient software support. Once the software support has been developed, the changes (“patches”) should be incorporated into the “official” version, but open-source communities usually do not accept patches that increase complexity for the sake of uncommon hardware. Moreover, as remarked in Section 4.2.1, many open-source communities are philosophically opposed to accepting any hardware-specific software patches. The hardware developer would be forced to maintain an expensive and unsustainable “fork” of the software codebase.
Figure 10 - [DA14] The complex open-source landscape for Big Data

D5.3 Roadmap v23
40
5.1 Where we are today: Market trends and main actors
5.1.1 Big Data processing: From query languages to frameworks In the early years of data processing, when data analysts knew exactly which answers they were looking for and their datasets were clean and preprocessed, query languages were the tool-of-choice. Query languages were bound to a specific purpose, for instance SQL for relational querying, SPARQL for querying Resource Description Framework data, and XPath/XQuery for XML. Moreover, the higher-level software could be easily written in a way that was independent of the hardware. Over the years, with the advent of Big Data, several changes in the data processing landscape have rendered query languages difficult to use. Firstly, there has been a nearly exponential increase in the volume and variety of data – data that is increasingly heterogeneous, unstructured, “dirty” and unprocessed, and therefore unsuitable for the SQL abstraction. In addition, there has been a broad shift from local to distributed computing, which has required the use of distributed frameworks, such as MapReduce, Spark and Flink, that could hide the complexity of distributed hardware. These lower-level frameworks have not been directly compatible with existing query languages. The consequence has been a shift away from query languages towards more data analysis libraries and APIs targeting Machine Learning (ML) and Natural Language Processing (NLP).
5.1.2 March toward hardware dependence The inevitable push from the business intelligence community toward Big Data analytics has resulted in the widespread adoption of distributed frameworks. At the same time, we are currently observing that, open source communities try to provide suitable ML code high-level libraries (MLlib) for these frameworks. Additionally, and similar to what happened during the era of widespread adoption of SQL, large companies and hyperscalers have already started to develop their own solutions for NLP and ML, in the form of specialized high-level libraries such as IBM’s SystemT and SystemML, and Google’s Tensor-Flow. The advantage to these companies is that these higher-level libraries can be run on nearly any distributed framework. They allow users to specify computations in a way that ensures that the program can be executed in parallel and the frameworks can then run this code on a supported set of hardware. Every time novel hardware becomes available, these frameworks need to be adapted to support the hardware. In summary, the Big Data domain has until recently struggled to champion framework-independent programming abstractions suitable for complex problems like NLP and ML. We are now starting to see suitable approaches in the form of specialized high-level libraries (including and also sometimes referred to Domain Specific Languages) that sit on top of distributed frameworks; however, these approaches are not hardware independent.
5.1.3 Too many hardware programming abstractions At the lower levels of the software stack, there are a large number of programming abstractions. Heterogeneous architecture approaches come with diverse programming

D5.3 Roadmap v23
41
interfaces that usually need to be addressed explicitly by Big Data application developers and cannot be easily integrated into existing workflows automatically. Even though every programming concept relevant for Big Data requires parallelizing work across available hardware, and even though all relevant hardware structures support parallel processing in some way, the specifics are incompatible, in that there are no common abstractions that work for everything. Abstraction for parallelism at the data center level means using MapReduce or another distributed framework while abstraction for parallelism (multicore) at node level requires yet another layer such as OpenMP (multi-core), heterogeneous architectures (CPU, GPU, FPGA) require an abstraction such as OpenCL, and so on. On a larger scale, MapReduce and its successors for batch and stream processing implemented by the Apache Spark and Apache Flink projects allow the parallel execution of code on shared-nothing clusters. All of these frameworks specify in a declarative way the data placement and unit of parallelization, while leaving the actual processing in each parallel instance to conventional functional or procedural code. The unit of parallelization supported here is an operating system thread. Any hardware that can execute such a thread, such as a CPU core, is potentially available for MapReduce, while everything else needs to be addressed explicitly by the programmer. At the hardware level on a single node, there are similar mismatches: GPUs and CPUs are tailored for processing multiple data items at once. For each piece of hardware, however different programming approaches are necessary. GPUs rely on SIMT, and CPUs provide SIMD functionality to achieve a similar goal at least on a single CPU core. Multi-core operations need to be implemented explicitly. Modern compilers and frameworks like OpenMP are capable of abstracting away some of these differences. Especially the kernel-based programming abstractions of OpenCL translate very well to all of the previously mentioned parallelization concepts, however even OpenCL only ensure correctness of the computation on each platform. It does not ensure that the computation has been optimized for execution on these same platforms. The situation with more advanced accelerator hardware in heterogeneous architectures is similar. While FPGAs usually support standard Hardware Description Languages (HDLs) such as VHDL and Verilog, these languages describe the functionality required at a very low level, in a way that is difficult for software engineers to understand (see Section 4.2.2). While there are approaches to generate such code from higher-level languages, such translation requires a considerable amount of compile time and the higher-level languages do not necessarily integrate the remaining Big Data software stack. Specialized solutions such as ASICs, DSPs and neuromorphic hardware require programming interfaces that are likewise specialized and for the time being cannot be accessed automatically from conventional Big Data framework code.

D5.3 Roadmap v23
42
5.1.4 Complex cloud service offerings: ML-as-a-Serv ice and beyond
Large companies and hyperscalers have chosen to provide analytics solutions as a service alongside their existing cloud offerings as a response to the growing demand for more sophisticated analytics (like ML and NLP). Google, Amazon, and Microsoft all offer regular Big Data cloud services now with machine learning. The complete control of the software stack and especially the customer-facing API allows these companies to replace the implementations of these APIs based on any hardware they deem suitable. It is unlikely that these companies have solved the programming abstraction mismatch problems outlined in the previous section, though. The programs that perform the actual model training and evaluation are very likely not automatically optimized to changing hardware configurations, but this does not need to be the case. Being in control of the entire functionality, hyperscalers do not need to optimize customer code for their platform, but rather can hand-tune their own fixed service implementation to their hardware. These efficient implementations then enable a competitive pricing policy for such services, which is an advantage to cloud service providers that can otherwise only offer bare compute and storage solutions.
5.1.5 A lack of Big Data benchmarks Over the course of our interviews, we noted that many companies could not adequately estimate the Return on Investment for adopting heterogeneous architectures. In other words, these businesses could not easily determine whether the investment in costly code adaptations (on top of the cost of new hardware) would be justified by sufficient improvements in performance, energy efficiency and other metrics. The standard way to evaluate the performance of a given system configuration is to run a representative workload that mimics the target workloads. While benchmarks exist for a variety of workloads, such as analytical and transactional database queries (TPC Range of Benchmarks for SQL), and even for Big Data specific tasks such as low-level data shuffling (Terasort), there are minimal benchmarks that mimic the complete application such as sentiment analysis and item recommendations (BigBench). In fact, “the diversity and rapid evaluation of Big Data systems means it is challenging to develop Big Data benchmarks to reflect various workload cases.” [Han15].
5.2 Where we want to be
5.2.1 Industry pains and expected gains The first category of actors consists of those using Big Data to solve problems. Such companies find it difficult to assess the business case for new hardware technologies, due to the lack of standardized benchmarks.
D5.3 Roadmap v23
43
Application companies, Big Analytics developers / customers
Infrastructure (IaaS) or Platform As
a Service (PaaS) users
Examples: Company 1, Company 4, Company 7, Company 9, Company 11, Company
12, Company 15, Company 17, Company 20, Company 24, Company
28, Company 52, Company 64, Company 74, Company 101
Pains • Application and analytics companies focused
almost exclusively on how to extract value from Big Data.
• Business case for heterogeneous architecture is difficult to assess
• Informed hardware selection requires costly benchmarking
• Difficult to compete with vertically integrated companies that co-design software with hardware.
Gains • Decision support for hardware selection allows
better assessment of business case • Nearly software-transparent hardware
acceleration • European alternatives for hyperscale service
providers
The second category of actors are data center operators and cloud service providers. These users must make a sustainable business out of operating a data center and providing cloud or virtualization services. In comparison with U.S. companies, they are not willing to take much risk. An important criterion, with regard to software, is optimized use of their hardware resources.
Data center operator (IaaS, VPS hosting, private cloud)
Examples:
Company 29, Company 30, Company 27, Company 47, Company 81,
Company 96, Company 112
Pains • Hyperscalers already provide go-to solutions for
most customers • Idle resources in multi-tenant systems
Gains • Competitive service for European and non-
European customers • Better resource utilization
The technology vendors find it difficult to prove the benefits of their solution, due to a lack of benchmarks, and the fact that their potential customers in Europe are unwilling to invest in novel hardware solutions.
Hardware technology providers
Examples: Company 43, Company 44, Company 46, Company 49,
Company 52, Company 60, Company 79, Company 85, Company 93,
Company 105
Pains • Assessment of customer needs • Smaller customers unwilling to invest in novel
hardware solutions
Gains • Product optimization target defined key
benchmarks • Broaden reach to smaller customers

D5.3 Roadmap v23
44
5.2.2 Key findings The following diagram summarizes the key objective to be addressed through the actions recommended in the next section.
5.3 How we are going to get there
5.3.1 TRL > 5: Accelerating adoption of current tec hnologies
5.3.1.1 Provide software support for novel and / or heterogeneous architectures
To facilitate the adoption of modern hardware, software can be designed in a way that makes more hardware platforms accessible to actors without requiring them to re-engineer their existing application software. Since novel hardware may pursue completely new processing paradigms, that may not be readily anticipated by current solutions, and given the reluctance of open-source communities to accept patches for specific hardware, the only feasible approach appears to be to identify and specify common subtasks in Big Data processing problems, that are either implemented using conventional software for conventional hardware, or implemented using novel hardware and suitable glue or driver code. While OpenCL appears to be widely accepted standard for general purpose computations on various hardware types, the dependency of specific OpenCL programs on hardware details as explained above may only yield sub-optimal performance on a given device. OpenCL programs specifically written for machine learning would also fail to translate to special purpose neuromorphic hardware. The solution to this problem appears to be further abstraction to allow different vendors to implement previously specified APIs. Software developers write code that targets such an API, and their call gets executed by whichever hardware provides the
• Objective: Accelerating adoption of current technologies
• Software support for novel hardware architectures
• Availability of standardized benchmarks will help quantify the benefits of novel hardware technologies
•Full-stack software optimization for better resource utilization
TRL >5 Accelerate adoption
TIMEFRAME: Now
• Objective: Preparing the next generation
• Encourage standardized accelerated building blocks
3 < TRL < 5 Prepare next
generation
TIMEFRAME: in 5 years
• Objective: Anticipating future challenges
• Pioneer intelligent use of heterogeneous resources
TRL < 3 Anticipate future challenges
TIMEFRAME: in 10 years

D5.3 Roadmap v23
45
most suitable implementation. In the case of neural networks, the call could be executed by a default CPU-based implementation, by a specialized OpenCL implementation provided by an accelerator vendor, or by neuromorphic hardware.
5.3.1.2 Action plan In order to provide software support for novel and / or heterogeneous architectures, we recommend the actions described in Section 4.4.2.6.
5.3.1.3 Encourage full-stack software optimization for better resource utilization
Concurrently to these efforts, European companies may also benefit from modern hardware trends originating from non-European vendors. As previously mentioned, there appears to be a tendency to analyze established and highly abstracted processing concepts, and implement these from scratch using low-level programming techniques, specifically tailor to operate on a specific set of hardware. This approach currently allows actors to use novel software that maximizes resources utilization on existing systems. If European companies recognize popular application needs or anticipate novel hardware trends, highly optimized software systems for specific applications could provide a significant performance gain without the need to invest in new hardware, or could amplify the performance gain provided by modern hardware by dropping abstractions that are meant to facilitate hardware adoption without software modifications. These optimizations are of course most effective for concrete and closely delimited software components in often-required application scenarios. Re-engineering an entire general-purpose software stack will likely be too costly to be economically viable. A case in point is non-volatile memory (NVM). Non-European entities such as HP (through its The Machine project) and Intel—Micron (through its 3D XPoint product) have announced possible future products. While a number of European software and systems vendors have expressed interest in exploiting this hardware technology, they have also conditioned their exploitation on this technology becoming a commodity. Although cost is one obstacle to commoditization of NVM, another obstacle is the need to re-engineer the stack, as explained above. This work to re-engineer the software stack requires cooperation between application companies, the open source community, and system integrators, and will be vital to prepare European companies for when the technology becomes a commodity.
5.3.1.4 Action plan To encourage full-stack software optimization for better resource utilization, we suggest calling for projects that consist of:
• A research facility coordinating and analyzing company inputs and dataset properties
• Several application companies, contributing representative workloads • Optionally hardware and solution providers seeking to optimize their product

D5.3 Roadmap v23
46
5.3.1.5 Establish standard Benchmarks Nearly ready is the assessment of novel hardware by means of pre-defined benchmarks. Based on results of previous (BigBench [Gha13]) and ongoing (HOBBIT Project [HOB]) benchmarking initiatives as well as CloudSuite, we need to define standard benchmarks for industry relevant workloads. Hardware providers can then use the benchmark specifications and implement the corresponding workload using whatever programming model or API is required by their hardware. Once accepted benchmarks are in place hardware providers have an incentive for providing extremely optimized workload implementations in order to claim the leadership positions. Actual users of their hardware are usually not capable of optimizing their implementations to a similar degree, unless the benchmark implementation is suitable and available for these users. This vendor side overfitting may distort the predicted performance figures derived from benchmarking results, however these results may still serve as a general guide for assessing the performance gains that can be expected from completely novel hardware devices and configurations. An important addition to established benchmarks like TPC is that certain hardware may require a measure for the correctness of the computation. Analog hardware such as neuromorphic devices might not rely on exactly repeatable numerical calculations, but on slightly imprecise analog measurements of circuit state. This may result in truly random deviations around the numerically correct solution for subsequent executions of the same workload. Corresponding benchmarks need to provide means for assessing such deviations so hardware users can choose a suitable accuracy/performance trade-off.
5.3.1.6 Action plan
Based on this assessment, we recommend projects that bring together applications and hardware providers with specialist research facilities to design benchmarks with a particular industry / application in mind. For example, A company working with neuronal networks for example, may find itself in a situation where it has to decide whether to move to GPU based accelerators, or even to novel neuromorphic hardware to accelerate their model training. A final decision on which of these two options provides the highest gain per cost is only possible if the company implements both solutions and measures the performance. The implementation may require significant investments in terms of re-engineering existing software to make use of these accelerators. In this scenario an accepted benchmarking scheme for machine learning with neural networks would allow the company to estimate the performance of each accelerator based on the benchmark results. The call should include at minimum representation from at least 2 of the following types of organizations:
• A research facility coordinating and analyzing company inputs and dataset properties
• Several application companies, contributing representative workloads for a particular industry
• Hardware and other solution providers seeking to optimize their product

D5.3 Roadmap v23
47
In addition to performance aspects Benchmarks also need to consider correctness of computation results. With neuromorphic hardware taking cues from analog computing, training and classification results achieved with neuromorphic hardware might not be reproducible with the numeric accuracy offered by conventional digital computations. In order for Benchmarks to accurately reflect real life workloads, suitable datasets need to be collected and made available as part of the Benchmark specification. While it is possible to generate artificial data based on statistical properties, this approach may not be feasible for all scenarios.
5.3.2 TRL 3 - 5: Preparing the next generation for adoption of new technologies
5.3.2.1 Identify and build accelerated building blo cks We propose to select often-required software functionality and define a fixed API for accessing these capabilities. By default, the API can be implemented using standard CPU code. Service providers or hardware providers can the step-in to provide hardware-accelerated implementations that make use of accelerators. Taking the example of machine learning, instead of writing the code from scratch, developers usually rely on libraries that implement established model training and classification routines, such as neural networks or support vector machines. With clearly defined APIs, developers could use such functionality and offload the computation to whatever device supports this computation. Specifics such as data placement and transfer would still be left to the “glue code”, meaning that software adaptions still would be necessary. However, integrating new hardware into the critical code path would still be greatly simplified.
5.3.2.2 Action plan
Instead of leaving the field of machine-learning–as-a-service to established players like Microsoft or Google, we recommend that European service providers offer competitive services using such APIs. Having complete control over the functionality they wish to offer, service providers could initially provide their functionality using conventional CPU-based implementations. Partnering with hardware providers, service providers would later replace implementations transparently to users with more efficient accelerator-based versions. Alternatively, different hardware providers could select features from popular Open Source projects and provide compatible hardware-accelerated implementations of these features, so users have the opportunity to adopt their hardware without major software adjustments into their existing solutions. Suitable projects would consist of:
• A cloud based service provider • One or more hardware or solution provider • One or more application company
For example: • Deutsche Telekom as European Cloud service provider seeking to establish
Machine Learning as a service offer • Maxeler seeking to offer hardware accelerated machine learning functionality
based on Dataflow technology

D5.3 Roadmap v23
48
• Okkam seeking to analyze large amounts of data off-premise but still in a European facility due to privacy concerns
5.3.3 TRL < 3: Anticipating future challenges
5.3.3.1 Investigate intelligent use of heterogeneou s resources Static assignments as to which hardware executes which software sub-routine are highly inflexible in environments where availability of computing devices can change. This is the case in multitenant cloud systems, as well as in IoT systems, where devices may be frequently added to, or removed from the system. In these scenarios it may be inefficient to leave the decision of which code to execute on which device to the developer, since the actually available devices are likely unknown until deployment and may change during execution. Automated decisions regarding operator placement require knowledge about the capabilities of each hardware device available, the expected performance of a workload on each device, the potential data transfer costs between devices, as well as the properties of the data that is to be processed. A runtime that has this information would enable the near optimal execution of complex code using the available hardware, not the hardware the developer initially considered. Solving this problem, however, represents a major challenge. Different operator implementations may have different performance characteristics depending on the data that is to be processed. A certain remote device might be the best choice to execute a certain workload in terms of efficiency, but may require additional network transfers compared to execution on a less efficient but local device.
5.3.3.2 Action plan The many degrees of freedom that need to be considered make this problem very hard to optimize. Consequently, we consider this a research problem in which researchers and data center providers and data center customers need to partner-up to analyze real-life workloads and device effective optimization schemes. Therefore, we recommend research actions that include:
• A cloud service provider, or an IoT system provider • A research facility such as a university • One or more application company seeking to deploy compute diverse compute
jobs on the cloud or IoT edge-computing system For example:
• Qarnot Computing as multi-tenant cloud service provider • TU Berlin as research facility • VICO Research and AMI software seeking to execute an analytics tasks on the
service providers infrastructure

D5.3 Roadmap v23
49
Bibliography 6
[ADV15] ADVA Optical Networking (27-10-15), “What Are the Benefits of a Disaggregated Data Center Interconnect Architecture?” [Online], Available: https://www.youtube.com/watch?v=jo44DvswBN0&feature=youtu.be
[Ahm15] Najam Ahmad in interview with Timothy Prickett Morgan (16-04-15), “Facebook Ops Director On Breaking Open The Switch” [Online], Available: http://www.nextplatform.com/2015/03/16/facebook-ops-director-on-breaking-open-the-switch/
[Bai15] Donald G. Bailey, “The Advantages and Limitations of High Level Synthesis for FPGA Based Image Processing”, ICDSC’15, Available: http://dl.acm.org/citation.cfm?id=2789145
[BDV16] (Jan 2016) BDVA SRIA v2.0 [Online], Available: http://www.bdva.eu/
[Bol15] Jag Boleria (15-10-15) – Linely Wire, “RapidIO Reaches for the Cloud, The Linley Group, [Online], Available: http://www.linleygroup.com/newsletters/newsletter_detail.php?num=5064
[Caf16] Andy Feng(@afeng76), Jun Shi and Mridul Jain (@mridul_jain), et. al. - Café On Spark, Yahoo Tumbler (Feb. 2016), CaffeOnSpark Open Sourced for Distributed Deep Learning on Big Data Clusters [Online], Available: http://yahoohadoop.tumblr.com/post/139916563586/caffeonspark-open-sourced-for-distributed-deep
[Cal13] Andrea Calimera, Enrico Macii, Massimo Poncino. The Human Brain Project and neuromorphic computing. Funct Neurol. 2013 Jul—Sep 28(3): 191—196. Available: http://www.ncbi.nlm.nih.gov/pmc/articles/PMC3812737/
[Col12] Coleman, D. (2012), “Optical Trends in the Data Center” [Online], Available: https://www.bicsi.org/uploadedFiles/BICSI_Website/Global_Community/Presentations/Caribbean/1.07%20Corning.pdf
[Cor05] Linux and TCP offload engines. LWN.net. 2005. https://lwn.net/Articles/148697/
[DA14] The Big Data Open Source Tools Landscape. September 2014. Datafloq. https://datafloq.com/big-data-open-source-tools/os-home/
[DEL15a] Dell’Oro (1 Apr 2015), Ethernet Switch – Five-Year Forecast Report [Online], Synopsis Available: http://www.delloro.com/reports/ethernet-switch-deployment-location
[DEL15b] Dell’Oro (1 Apr 2015), Data Center SDN Including Cloud, White Box, etc. Report [Online], Synopsis Available: http://www.delloro.com/reports/data-center-sdn-including-cloud-white-box-etc
[DRI15] DRIVE PX, Nvidia website, http://www.nvidia.com/object/drive-px.html (accessed 25 Nov 2015).
[Euroserver] EUROSERVER: Green Computing Node for European micro-servers. European Union’s FP7 (ICT-2013-10) research and innovation programme under grant agreement No 610456.

D5.3 Roadmap v23
50
[Fee15] Christian Feest, Using FPGAs to Minimise Data Centre Power Consumption. Telesoft White Papers, September 2015. http://www.sourcingfocus.com/uploaded/documents/Using_FPGAs_to_minimise_power_consumption.pdf
[Fis09] Ruth D. Fisher. Winning the Hardware–Software Game: Using Game Theory to Optimize the Pace of New Technology Adoption. 2009.
[Gha13] Ahmad Ghazal et al. BigBench: Towards an Industry Standard Benchmark for Big Data Analytics. SIGMOD’13.
[Han15] Rui Han, et al. Benchmarking Big Data Systems: State-of-the-Art and Future Directions. Technical Report. ICS, ACS. 2015. http://arxiv.org/pdf/1506.01494.pdf
[HOB] HOBBIT: Holistic Benchmarking of Big Linked Data. European Union’s H2020 research and innovation programme under grant agreement number 688227. http://project-hobbit.eu
[Hof15] Todd Hoff - High Scalability blog (15-08-10), “How Google Invented An Amazing Datacenter Network Only They Could Create” [Online], Available: http://highscalability.com/blog/2015/8/10/how-google-invented-an-amazing-datacenter-network-only-they.html
[Hua15] Andrew Huang. The Death of Moore’s Law Will Spur Innovation, IEEE Spectrum March 2015. http://spectrum.ieee.org/semiconductors/design/the-death-of-moores-law-will-spur-innovation
[IDC13] Gabriella Cattaneo (Oct 2013), European Data Market Presentation [Online], Available: http://www.nessi-europe.eu/files/PastEventsDocs/NESSI-SUMMIT-2014-Presentations/NESSI_European%20data%20market%20presentation_4.0_Cattaneo.pdf
[IEE14] Hasan Alkhatib, Paolo Faraboschi, Eitan Frachtenberg, et. al. (Feb 2014) IEEE CS 2022 Report [Online], Available: https://www.computer.org/cms/ComputingNow/2022Report.pdf
[IHS] http://english.hankyung.com/news/apps/news.view?c1=03&nkey=201504091657231
[IHS15] Infonetics Research (June 2015), “IHS Infonetics Data Center Network Equipment: Quarterly Market Share, Size and Forecasts”
[INF14] Infonetics Research (Feb 2014), “Service Provider Routers and Switches Quarterly Market Share, Size and Forecasts” [Online], Synopsis Avalable: http://www.infonetics.com/pr/2014/3Q14-Service-Provider-Routers-Switches-Market-Highlights.asp
[INT15] Intel Acquisition of Altera, June 1, 2015. [Online], Available: http://intelacquiresaltera.transactionannouncement.com/wp-content/uploads/2015/06/Investor-Deck.pdf
[IQC] Quantum Computing – University of Waterloo: https://uwaterloo.ca/institute-for-quantum-computing/quantum-computing-101
[Kaleao] http://kaleao.com
[Kalray] Kalray Cloud Computing Solutions, http://www.kalray.eu/kalray/solutions/

D5.3 Roadmap v23
51
[Kin15] Andre Kindness - Forrester blog (15-02-23), “What is the difference between white box bare metal branded bare metal and oem network switches?” [Online], Available: http://blogs.forrester.com/andre_kindness/15-02-23-what_is_the_difference_between_white_box_bare_metal_branded_bare_metal_and_oem_network_switches
[Kud13] Daniel Kudrow, Kenneth Bier, Zhaoxia Deng, Diana Franklin, Yu Tomita, Kenneth R. Brown, and Frederic T. Chong: Quantum Rotations: A Case Study in Static and Dynamic Machine-Code Generation for Quantum Computers. 2013 International Symposium on Computer Architecture (ISCA-2013).
[Met15] Cade Metz (Sep 2015), “Google’s Quantum Computer Just Got a Big Upgrade” [Online], Available: http://www.wired.com/2015/09/googles-quantum-computer-just-got-a-big-upgrade-1000-qubits/
[Ngu14] Xuan Nam Nguyen and et al., "Optimizing Rules Placement in OpenFlow Networks: Trading Routing for Better Efficiency," ACM SIGCOMM Workshop on Hot Topics in Software Defined Networking, June 2014. [Online]. Available: https://hal.inria.fr/hal-00993282.
[Nun12] Geoff Nunberg (20-12-12), “Forget YOLO: Why 'Big Data' Should Be The Word Of The Year” [Online], Available: http://www.npr.org/2012/12/20/167702665/geoffrey-nunbergs-word-of-the-year-big-data?live=1
[OpenCompute] The Open Compute Initiative, http://www.opencompute.org/
[OVH] OVH Power Usage Effectiveness (PUE) has been reduced by 33% in less than ten years, https://www.ovh.co.uk/aboutus/green-it.xml
[Pre14] Gill Press (03-09-14), “12 Big Data Definitions: What's Yours?” [Online], Available: http://www.forbes.com/sites/gilpress/2014/09/03/12-big-data-definitions-whats-yours/#32c2a68821a9
[Pri15a] Timothy Prickett Morgan (09-06-15), “X86 Servers Dominate The Datacenter–For Now” [Online], Available: http://www.nextplatform.com/2015/06/04/x86-servers-dominate-the-datacenter-for-now/
[Pri15b] Timothy Prickett Morgan (04-11-15), “Smashing the Server to Put it Back Together Again” [Online], Available: http://www.nextplatform.com/2015/11/04/smashing-the-server-to-put-it-back-together-better/
[Pri16] Timothy Prickett Morgan (29-01-16), “Building 100G Momentum To Lift Mellanox Further” [Online], Available: http://www.nextplatform.com/2016/01/29/building-100g-momentum-to-lift-mellanox-further/
[Put14] Putnam et al, A Reconfigurable Fabric for Accelerating Large-Scale Datacenter Services, ISCA 2014. http://research.microsoft.com/pubs/212001/Catapult_ISCA_2014.pdf
[Shi15] Anton Shilov (08-04-15), “Samsung to use world’s largest $15 billion [Pyeongtaek] fab to produce DRAM” [Online], Available: http://www.kitguru.net/components/memory/anton-shilov/samsung-to-use-worlds-largest-15-billion-fab-to-produce-dram-report/
[Sim14] Tom Simonite: Microsoft’s Quantum Mechanics. MIT Technology Review, October 10, 2014. https://www.technologyreview.com/s/531606/microsofts-quantum-mechanics/

D5.3 Roadmap v23
52
[Sim15a] Tom Simonite: Google’s Quantum Dream Machine, MIT Technology Review, December 18, 2015, www.technologyreview.com/s/544421/googles-quantum-dream-machine/
[Sim15b] Tom Simonite: IBM Shows Off a Quantum Computing Chip. MIT Technology Review, April 29, 2015. www.technologyreview.com/s/537041/ibm-shows-off-a-quantum-computing-chip/
[STA16] Helpdesk response (22-02-16), What is Big Data and what classifies as Big Data? [Online], Available: http://stackoverflow.com/questions/35560823/what-is-big-data-what-classifies-as-big-data
[Tal15] Rick Talbot, (08-05-15), “Data Center Interconnection – Not Quite So Simple” [Online] Available: http://networkmatter.com/2015/08/05/data-center-interconnection-not-quite-so-simple/
[TRE15] TrendForce (11-09-15), “Global Branded DRAM Revenue Ranking, Q3 2015.” [Online], Available: http://press.trendforce.com/node/view/2158.html
[Wal16] M. Mitchell Waldrop, The chips are down for Moore’s law. Nature, Vol. 520, Issue 7589. http://www.nature.com/news/the-chips-are-down-for-moore-s-law-1.19338








![[mangá]fullmetal alchemist v23](https://img.dokumen.tips/doc/110x75/568bd5771a28ab2034988edc/mangafullmetal-alchemist-v23.jpg)




















