Embed Size (px)
Citation preview

CS3773 Software Engineering
Lecture 9 Software Testing

UTSA CS37732
Software Verification and Validation
Software verification and validation ( V & V) techniques are applied to improve the quality of software
V & V takes place at each stage of software process – Requirements analysis– Design analysis– Implementation checking
Inspection Testing

UTSA CS37733
Goal of Verification and Validation
Establish confidence that the software systems is “fit for purpose”
– Software function– User expectations– Marketing environment
Two verification and validation ( V & V) approaches– Software inspections or peer reviews
Manual or automated
– Software testing Exercising program using data and discovering defects through
output

UTSA CS37734
V & V versus Debugging
V & V process are interleaved with debugging V & V process are intended to establish the existence of
defects in a software system Debugging is a process that locates and corrects these
defects – Patterns in the test output– Design additional tests– Trace the program manually– Use debugging tools

UTSA CS37735
Software Inspection
Software inspection is a static process Compared with testing, software inspections have some
advantages– During testing, errors can hide other errors; during
inspection, a single session can discover many error – During testing, you have to develop test harnesses to test
available parts; during inspection, incomplete system can be checked without additional cost
– During testing, only program defects are disclosed; during inspection, broader quality attributes are considered

UTSA CS37736
Program Inspection
Manual program inspection detects defects, other types of inspections may be concerned with schedule, costs, etc.
Manual program inspection is carried out by a team Program inspection activities
– Planning– Overview– Individual preparation– Inspection meeting– Rework– Follow-up

UTSA CS37737
Issues of Program Inspection
Have a precise specification of the code to be inspected Inspection team members are familiar with the
organizational standards Compilable version of the code has to be distributed to
all team members Program inspection is driven by checklist of errors Program inspection should focus on defect detection,
standards conformance, and poor quality programming

UTSA CS37738
Automated Static Analysis
Automated static analysis tools scan the source code and detect possible faults and anomalies, such as variables used without initialization
– Statements are well-formed– Make inference about the control flow– Compute the set of all possible values for program data
Static analysis complements the error detection facilities provided by compiler

UTSA CS37739
Activities in Static Analysis
Control flow analysis: loop identification– e.g., Unreachable code
Data use analysis: highlighting variables– e.g., Variables declared but never used
Type checking Information flow analysis: detecting dependencies
between input and output variables Path analysis: path examination

UTSA CS377310
Verification and Formal Methods
Formal methods are mathematical notations and analysis techniques for enhancing the quality of systems
Confidence in software can be obtained by using formal methods
– Formal methods are rigorous means for specification and verification
– Formal requirements models can be automatically analyzed and requirement errors are easier and cheaper to fix at the requirement stage
– Powerful tools (e.g., model checkers) have been increasingly applied in modeling and reasoning about computer-based systems

UTSA CS377311
Software Testing
Testing is the most commonly used validation technique Testing is an important part of the Software Lifecycle Testing is the process of devising a set of inputs to a
given piece of software that will cause the software to exercise some portion of its code
The developer of the software can then check that the results produced by the software are in accord with his or her expectations

UTSA CS377312
Testing Levels Based on Test Process Maturity
Level 0 : There’s no difference between testing and debugging
Level 1 : The purpose of testing is to show correctness Level 2 : The purpose of testing is to show that the
software doesn’t work Level 3 : The purpose of testing is not to prove anything
specific, but to reduce the risk of using the software Level 4 : Testing is a mental discipline that helps all IT
professionals develop higher quality software

UTSA CS377313
Software Testing Objectives
Find as many defects as possible Find important problems fast Assess perceived quality risks Advise about perceived project risks Certify to a given standard Assess conformance to a specification (requirements,
design, or product claims)

UTSA CS377314
Software Testing Stages
Unit testing– Testing of individual components
Integration testing– Testing to expose problems arising from the combination of
components System testing
– Testing the overall functionality of the system Acceptance testing
– Testing by users to check that the system satisfies requirements. Sometimes called alpha testing

UTSA CS377315
Software Testing Activities
Test planning: design test strategy and test plan Test development: develop test procedures, test
scenarios, test cases, and test scripts to use in testing software
Test execution: execute the software based on the plans and test cases, and report any errors found to the development team
Test reporting: generate metrics and make final reports on their test effort and whether or not the software tested is ready for release
Retesting the revised software

UTSA CS377316
Test Case
Input values
Expected outcomes– Things created (output)
– Things changed/updated database?
– Things deleted
– Timing
…
Environment prerequisites: file, net connection …

UTSA CS377317
Design Test Case
Build test cases (implement)
– Implement the preconditions (set up the environment)
– Prepare test scripts (may use test automation tools)
Structure of a test case
Simple linear Tree(I, EO) {(I1, EO1), (I2, EO2), …} I
EO1 EO2

UTSA CS377318
Test Script
Scripts contain data and instructions for testing
– Comparison information
– What screen data to capture
– When/where to read input
– Control information
Repeat a set of inputs
Make a decision based on output
– Testing concurrent activities

UTSA CS377319
Test Results
Compare (test outcomes, expected outcomes)
– Simple/complex (known differences)
– Different types of outcomes
Variable values (in memory)
Disk-based (textual, non-textual, database, binary)
Screen-based (char., GUI, images)
Others (multimedia, communicating apps.)

UTSA CS377320
Software Testing Techniques
Functional testing is applied to demonstrate the system meets its requirements, it is also called black-box testing
– Testers are only concerned with the functionality, performance, and dependability
– The system is treated as a black box that takes input and produces output
Structural testing is applied to expose defects and tests are derived from the knowledge of the internal workings of items
– Testers understand the algorithm and the structure of systems
– The system is treated as a white box

UTSA CS377321
Functional Testing
Boundary value testing– Boundary value analysis– Robustness testing– Worst case testing– Special value testing
Equivalence class testing Decision table based testing

UTSA CS377322
Boundary Value Analysis
Errors tend to occur near the extreme values of an input variables
Boundary value analysis focuses on the boundary of the input space to identity test cases
Boundary value analysis selects input variable values at their
– Minimum– Just above the minimum– A nominal value– Just below the maximum– Maximum
UTSA CS377323
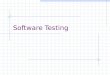
Example of Boundary Value Analysis
Assume a program accepting two inputs y1 and y2, such that a < y1< b and c < y2 < d
a b
c
d
y2
y1
.. . .. . .
. .

UTSA CS377324
Single Fault Assumption for Boundary Value Analysis
Boundary value analysis is also augmented by the single
fault assumption principle
“Failures occur rarely as the result of the simultaneous
occurrence of two (or more) faults”
In this respect, boundary value analysis test cases can
be obtained by holding the values of all but one variable
at their nominal values, and letting that variable assume
its extreme values

UTSA CS377325
Generalization of Boundary Value Analysis
The basic boundary value analysis can be generalized in
two ways:– By the number of variables - (4n +1) test cases for n
variables
– By the kinds of ranges of variables Programming language dependent
Bounded discrete
Unbounded discrete (no upper or lower bounds clearly defined)
Logical variables

UTSA CS377326
Limitations of Boundary Value Analysis
Boundary value analysis works well when the program
to be tested is a function of several independent
variables that represent bounded physical quantities
Boundary value analysis selected test data with no
consideration of the function of the program, nor of the
semantic meaning of the variables
We can distinguish between physical and logical type of
variables as well (e.g. temperature, pressure speed, or
PIN numbers, telephone numbers etc.)

UTSA CS377327
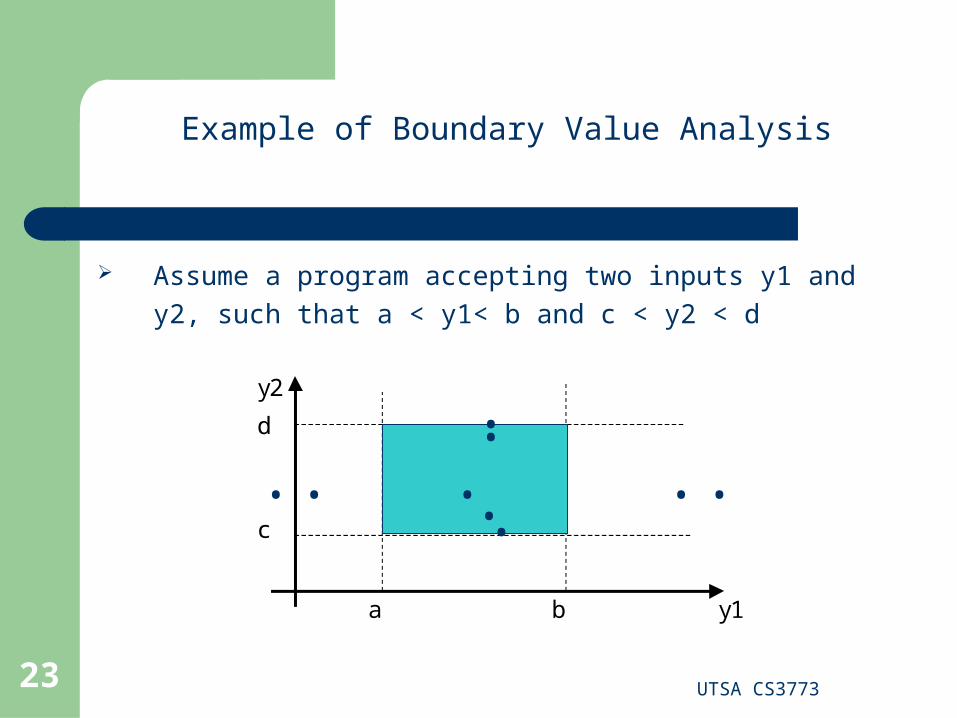
Robustness Testing
Robustness testing is a simple extension of boundary value analysis
In addition to the five boundary value analysis values of variables, we add values slightly greater that the maximum (max+) and a value slightly less than the minimum (min-)
The main value of robustness testing is to force attention on exception handling
In some strongly typed languages values beyond the predefined range will cause a run-time error
UTSA CS377328
Example of Robustness Testing
a b
c
d
y2
y1
... . … . .
. . .
.

UTSA CS377329
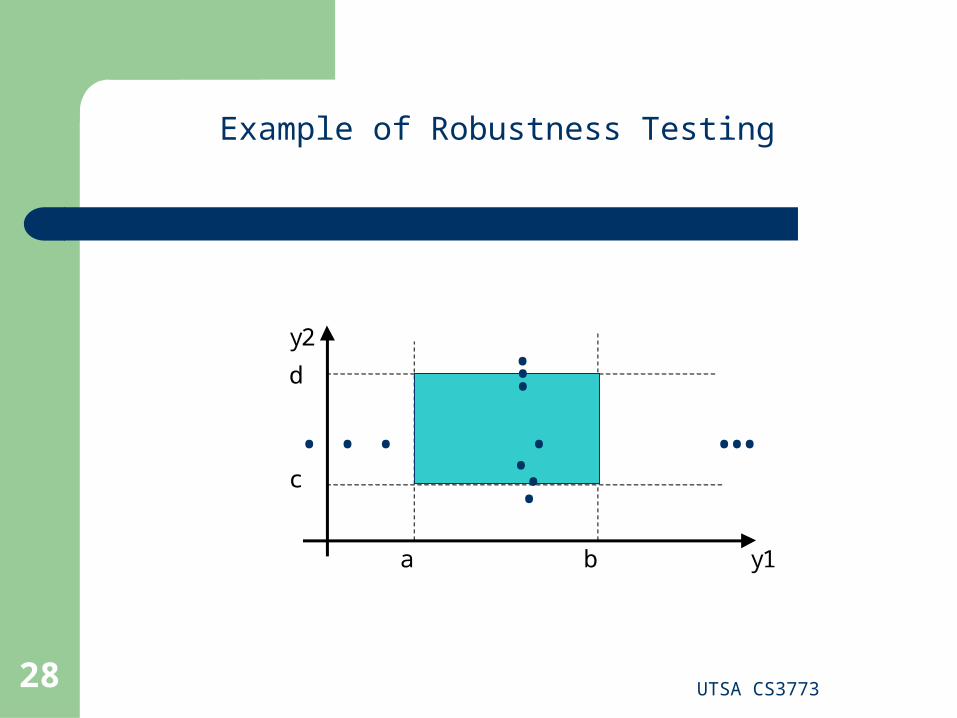
Worst Case Testing
In worst case testing we reject the single fault assumption and we are interested what happens when more than one variable has an extreme value
Considering that we have five different values that can be considered during boundary value analysis testing for one variable, now we take the Cartesian product of these possible values for 2, 3, … n variables
We can have 5n test cases for n input variables The best application of worst case testing is where
physical variables have numerous interactions
UTSA CS377330
Example of Worst Case Testing
a b
c
d
y2
y1
.. . .... . .... . ..
.. . .... . ..

UTSA CS377331
Special Value Testing
Special value testing is probably the most widely
practiced form of functional testing, most intuitive, and
least uniform
Utilizes domain knowledge and engineering judgment
about program’s “soft spots” to devise test cases
Event though special value testing is very subjective on
the generation of test cases, it is often more effective
on revealing program faults

UTSA CS377332
Equivalence Class Testing
The use of equivalence class testing has two motivations:
– Sense of complete testing– Avoid redundancy
Equivalence classes form a partition of a set that is a collection of mutually disjoint subsets whose union is the entire set
Two important implications for testing:– The entire set is represented provides a form of
completeness– The disjointness assures a form of non-redundancy

UTSA CS377333
Example of Equivalence Class Testing
The program P with 3 inputs: a, b and c and the corresponding input domains are A, B, and C
4321
21
321
CCCCC
BBB
AAAA

UTSA CS377334
Example of Equivalence Class Testing
Define a1, a2 and a3 as:
– let ai be a “representative” or “typical” value within its
respective equivalence class (e.g. the midpoint in a linear equivalence class).
– similarly define bi and ci.
Test cases can be stated for the inputs <a,b,c> in terms of the representative points
The basic idea behind the techniques is that one point within an equivalence class is just as good as any other point within the same class

UTSA CS377335
Decision Table
Decision tables make it easy to observe that all possible
conditions are accounted for
Decision tables can be used for:– Specifying complex program logic
– Generating test cases (Also known as logic-based testing)
Logic-based testing is considered as:– structural testing when applied to structure, i.e. control
flow graph of an implementation
– functional testing when applied to a specification

UTSA CS377336
Decision Table Usage
The use of the decision-table model is applicable when :– Specification is given or can be converted to a decision
table
– The order in which the predicates are evaluated does not
affect the interpretation of the rules or resulting action
– The order of rule evaluation has no effect on resulting
action
– Once a rule is satisfied and the action selected, no other
rule need be examined
– The order of executing actions in a satisfied rule is of no
consequence

UTSA CS377337
Example of Decision Table
Conditions
Printer does not print Y Y Y Y N N N N
A red light is flashing Y Y N N Y Y N N
Printer is unrecognized Y N Y N Y N Y N
Actions
Heck the power cable X
Check the printer-computer cable X X
Ensure printer software is installed X X X X
Check/replace ink X X X X
Check for paper jam X XPrinter Troubleshooting

UTSA CS377338
Structural Testing
Program Flow Graph Testing– Basis Path Testing
– Decision-to-Decision Path
– Test Coverage Metrics
Data Flow Testing

UTSA CS377339
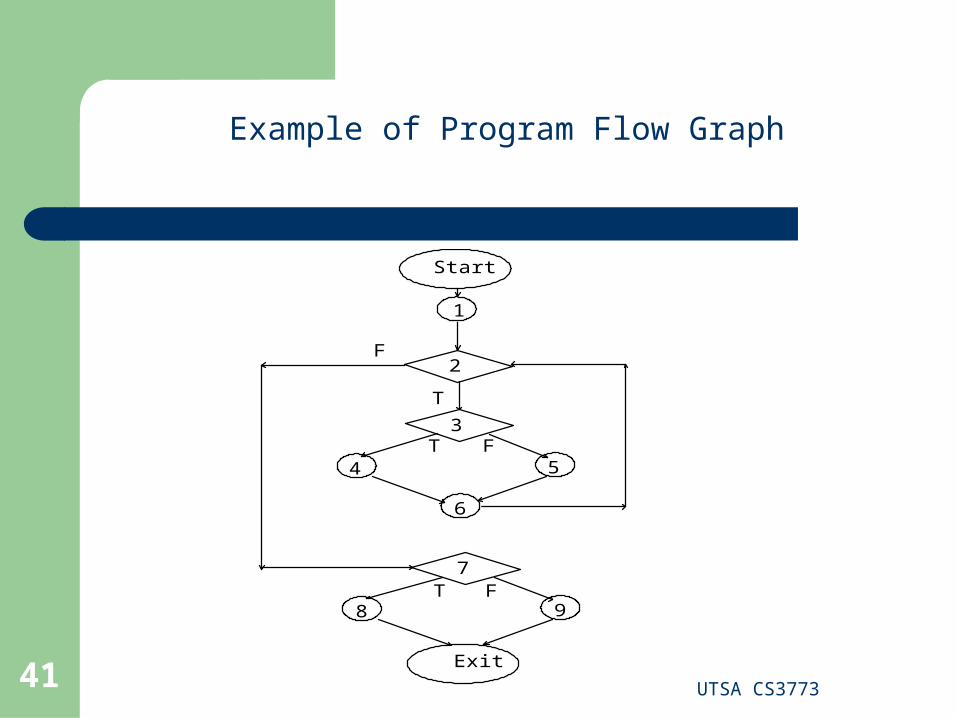
Program Flow Graph
“Given a program written in an imperative programming language, its Program Graph, is a directed labeled graph in which nodes are either groups of entire statements or fragments of a statement, and edges represent flow of control” – by P. Jorgensen
If i, j, are nodes (basic block) in the program graph, there is an edge from node i, to node j in the program graph if an only if, the statement corresponding to node j, can be executed immediately after the last statement of the group of statement(s) that correspond to node i.
UTSA CS3773 40
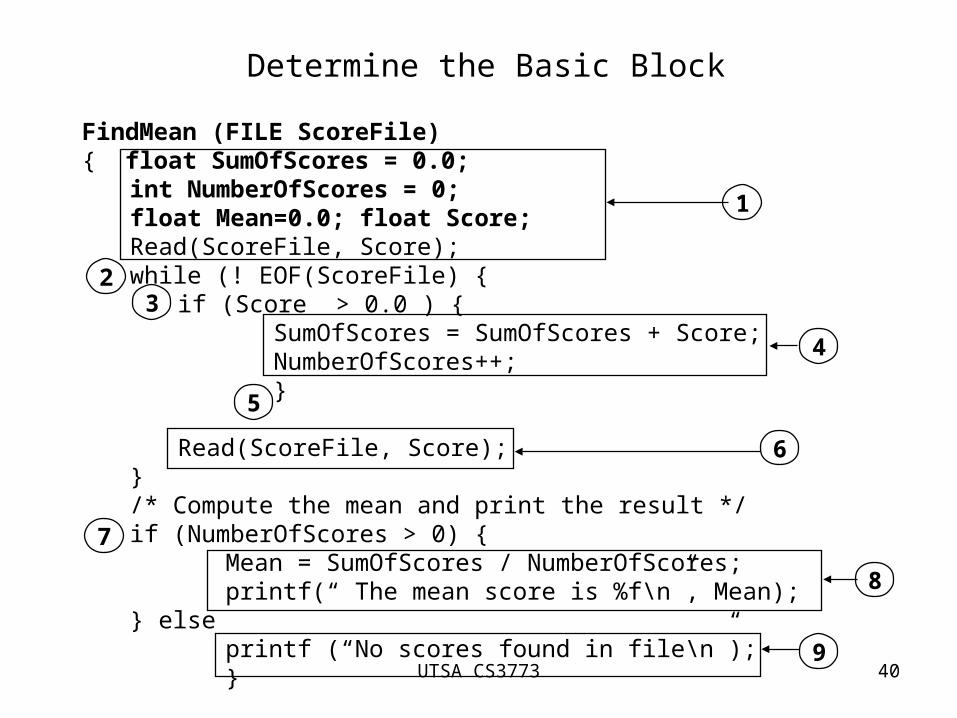
Determine the Basic Block
FindMean (FILE ScoreFile){ float SumOfScores = 0.0;
int NumberOfScores = 0; float Mean=0.0; float Score;Read(ScoreFile, Score);while (! EOF(ScoreFile) {
if (Score > 0.0 ) {SumOfScores = SumOfScores + Score;NumberOfScores++;}
Read(ScoreFile, Score);}/* Compute the mean and print the result */if (NumberOfScores > 0) {
Mean = SumOfScores / NumberOfScores;printf(“ The mean score is %f\n”, Mean);
} elseprintf (“No scores found in file\n”);}
1
23
4
5
7
6
8
9
UTSA CS377341
Example of Program Flow Graph
Start
2
3
4 5
6
7
8 9
Exit
1
F
T F
T F
T

UTSA CS377342
Path Testing
Path Testing is focusing on test techniques that are based on the selection of test paths through a program graph. If the set of paths is properly chosen, then we can claim that we have achieved a measure of test thoroughness
The fault assumption for path testing techniques is that something has gone wrong with the software that makes it take a different path than the one intended
Structurally, a path is a sequence of statements in a program unit. Semantically, a path is an execution instance of the program unit. For software testing we are interested in entry-exit paths

UTSA CS377343
Path Testing Process
Unit Input: – Source code and a path selection criterion
Process:– Generation of a Program Flow Graph (PFG)
– Selection of Paths
– Generation of Test Input Data
– Feasibility Test of a Path
– Evaluation of Program’s Output for the Selected Test Cases
UTSA CS3773 44
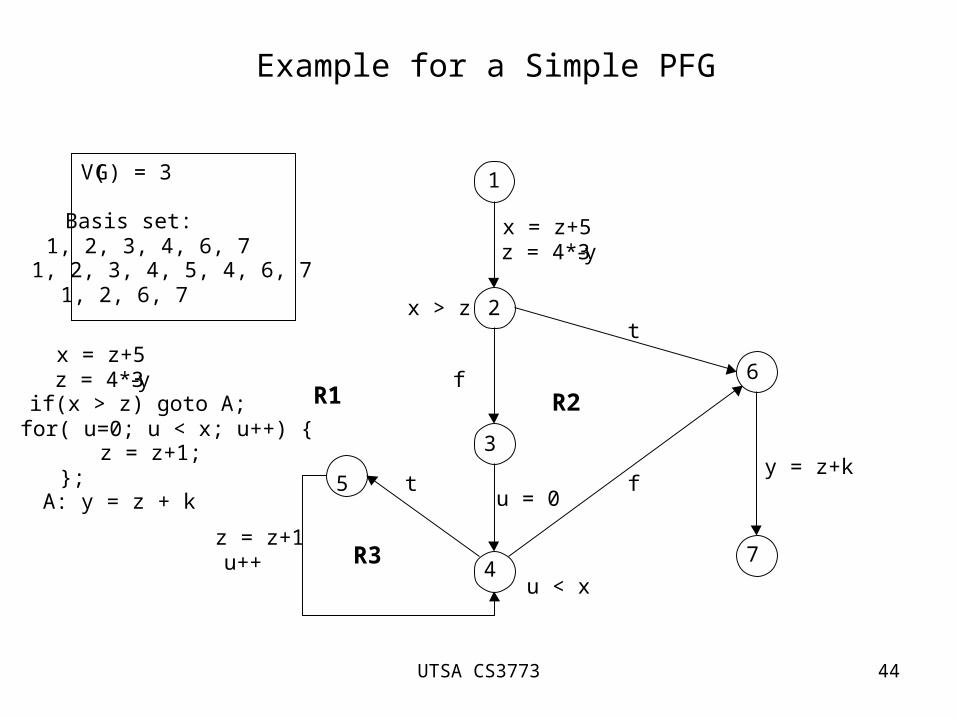
Example for a Simple PFG
x = z+5 z = 4*3-y if(x > z) goto A; for( u=0; u < x; u++) { z = z+1; }; A: y = z + k
x = z+5 z = 4*3-y
x > z
z = z+1 u++
y = z+k
u = 0
f
f t
t
u < x
1
2
3
4
5
6
7
R1 R2
R3
V(G) = 3 Basis set: 1, 2, 3, 4, 6, 7 1, 2, 3, 4, 5, 4, 6, 7 1, 2, 6, 7

UTSA CS377345
Decision-to-Decision Path
A DD-Path is a chain obtained from a program graph,
where a chain is a path in which the initial and terminal
nodes are distinct, and every interior node has indegree
= 1, and outdegree = 1
Internal node is 2-connected to every other node in the
chain, and there are no instances of 1- or 3- connected
nodes.– Feasibility Test of a Path
– Evaluation of Program’s Output for the Selected Test Cases
DD-Paths are used to create DD-Path Graphs.

UTSA CS377346
Decision-to-Decision Path Graph
Given a program written in an imperative language, its
DD-Path graph is a labeled directed graph, in which
nodes are DD-Paths of its program graph, and edges
represent control flow between successor DD-Paths
In this respect, a DD-Path is a condensation graph. For
example 2-connected program graph nodes are
collapsed to a single DD-Path graph node
UTSA CS3773 47
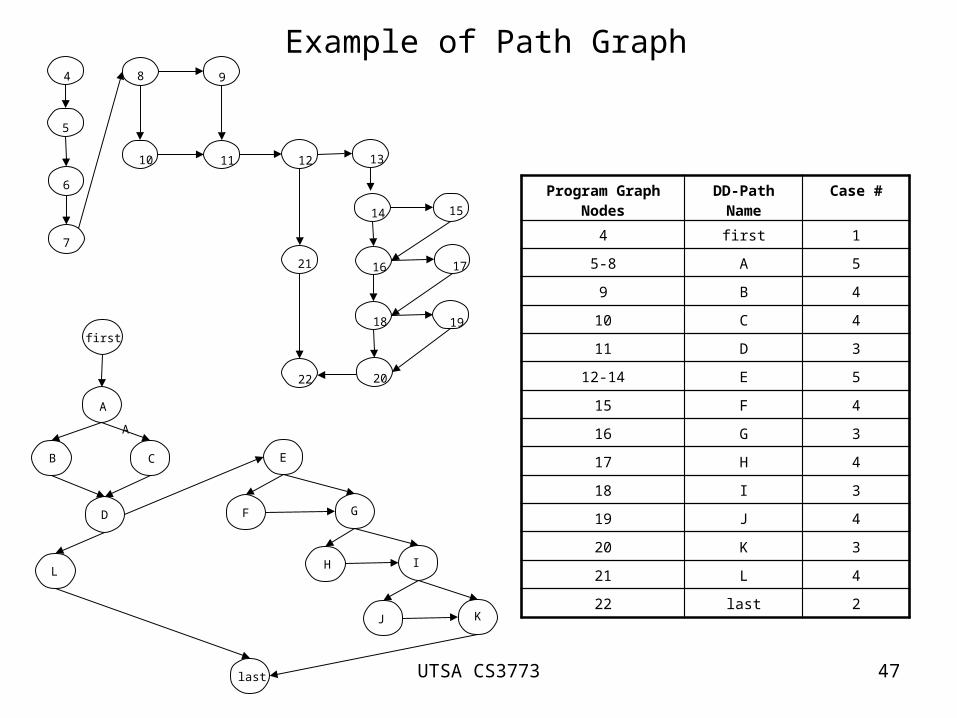
Example of Path Graph 4
5
6
7
8
10
9
11 12 13
21
14 15
22
16 17
18 19
20
Program Graph Nodes
DD-Path Name
Case #
4 first 1
5-8 A 5
9 B 4
10 C 4
11 D 3
12-14 E 5
15 F 4
16 G 3
17 H 4
18 I 3
19 J 4
20 K 3
21 L 4
22 last 2
first
A
B C
D
L
E
F G
H
A
I
J K
last

UTSA CS377348
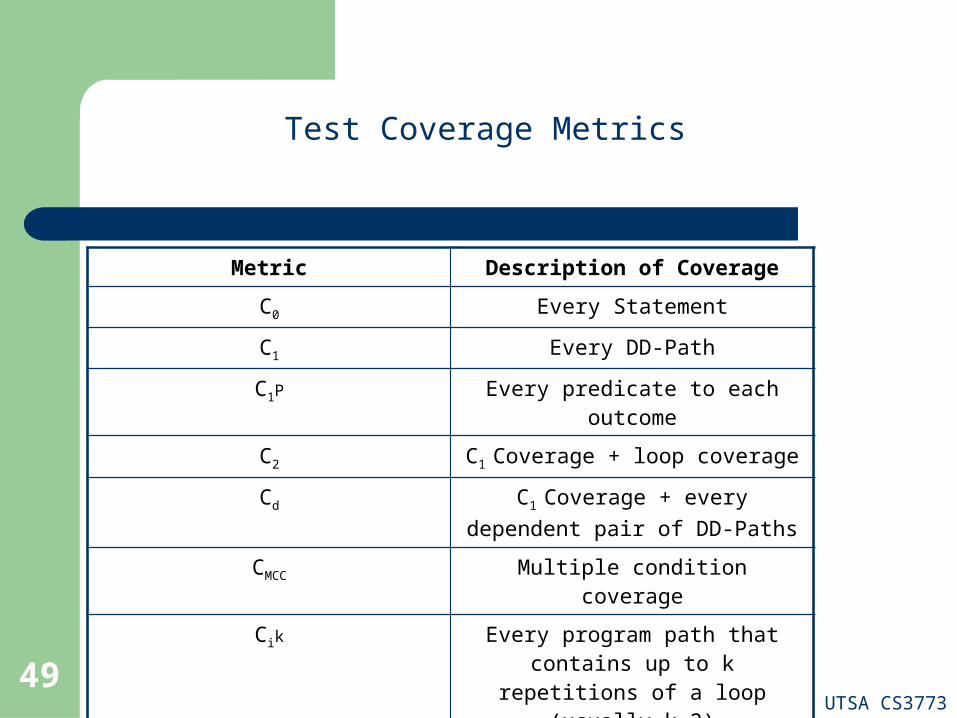
Test Coverage
The motivation of using DD-paths is that they enable
very precise descriptions of test coverage
In our quest to identify gaps and redundancy in our test
cases as these are used to exercise (test) different
aspects of a program we use formal models of the
program structure to reason about testing effectiveness
Test coverage metrics are a device to measure the
extend to which a set of test cases covers a program
UTSA CS377349
Test Coverage Metrics
Metric Description of Coverage
C0 Every Statement
C1 Every DD-Path
C1P Every predicate to each outcome
C2 C1 Coverage + loop coverage
Cd C1 Coverage + every dependent pair of DD-Paths
CMCC Multiple condition coverage
Cik Every program path that contains up to k repetitions of a loop (usually k=2)
Cstat “Statistically significant” fraction of paths
C∞ All possible execution paths

UTSA CS377350
Data Flow Testing
Data flow testing refers to a category of structural testing techniques that focus on the points of the code variables obtain values (are defined) and the points of the program these variables are referenced (are used)
– Around faults that may occur when a variable is defined and referenced in not a proper way A variable is defined but never used A variable is used but never defined A variable that is defined twice (or more times) before it is
used – Parts of a program that constitute a slice – a subset of
program statements that comply with a specific slicing criterion (i.e. all program statements that are affected by variable x at point P)

UTSA CS377351
Data Flow Testing Process
Data-flow testing involves selecting entry/exit paths
with the objective of covering certain data definition
and use patterns, commonly known as data-flow criteria
An outline of data-flow testing is as follows:– Draw a data flow graph for the program
– Select data-flow testing criteria
– Identify paths in the data-flow graph to satisfy the
selection criteria
– Produce test cases for the selected paths

UTSA CS377352
Reading Assignments
Sommerville’s Book, 8th edition – Chapter 22, “Software Inspection”– Chapter 23, “Software Testing”
Somerville’s Book, 9th edition– Chapter 8, “Software Testing”