Embed Size (px)
Citation preview

CS 4705
Morphology: Wordsand their Parts
CS 4705
Julia Hirschberg

Words
• In formal languages, words are arbitrary strings• In natural languages, words are made up of
meaningful subunits called morphemes– Morphemes are abstract concepts denoting
entities or relationships – Morphemes may be
• Stems: the main morpheme of the word• Affixes: convey the word’s role, number, gender,
etc.• cats == cat [stem] + s [suffix]• undo == un [prefix] + do [stem]

Why do we need to do Morphological Analysis?
• The study of how words are composed from smaller, meaning-bearing units (morphemes)
• Applications:– Spelling correction: referece– Hyphenation algorithms: refer-ence– Part-of-speech analysis: googler [N], googling
[V]– Text-to-speech: grapheme-to-phoneme
conversion• hothouse (/T/ or /D/)

– Let’s us guess the meaning of unknown words• ‘Twas brillig and the slithy toves…
• Muggles moogled migwiches

Morphotactics
• What are the ‘rules’ for constructing a word in a given language?– Pseudo-intellectual vs. *intellectual-pseudo– Rational-ize vs *ize-rational– Cretin-ous vs. *cretin-ly vs. *cretin-acious
• Possible ‘rules’– Suffixes are suffixes and prefixes are prefixes– Certain affixes attach to certain types of stems
(nouns, verbs, etc.)– Certain stems can/cannot take certain affixes

• Semantics: In English, un- cannot attach to adjectives that already have a negative connotation:– Unhappy vs. *unsad– Unhealthy vs. *unsick– Unclean vs. *undirty
• Phonology: In English, -er cannot attach to words of more than two syllables– great, greater– Happy, happier– Competent, *competenter– Elegant, *eleganter– Unruly, ?unrulier

• Regular– Walk, walks, walking, walked, (had) walked– Table, tables
• Irregular – Eat, eats, eating, ate, (had) eaten– Catch, catches, catching, caught, (had) caught– Cut, cuts, cutting, cut, (had) cut– Goose, geese
Regular and Irregular Morphology

Morphological Parsing
• Algorithms developed to use regularities -- and known irregularities -- to parse words into their morphemes
• Cats cat +N +PL• Cat cat +N +SG• Cities city +N +PL• Merging merge +V +Present-participle
• Caught catch +V +past-participle

Morphology and Finite State Automata
• We can use the machinery provided by FSAs to capture facts about morphology• Accept strings that are in the language• Reject strings that are not• Do this in a way that does not require us to list
all the words in the language

How do we build a Morphological Analyzer?
• Lexicon: list of stems and affixes (w/ corresponding part of speech (p.o.s.))
• Morphotactics of the language: model of how and which morphemes can be affixed to a stem
• Orthographic rules: spelling modifications that may occur when affixation occurs– in il in context of l (in- + legal)
• Most morphological phenomena can be described with regular expressions – so finite state techniques often used to represent morphological processes

Some Simple Rules
• Regular singular nouns stay as is• Regular plural nouns have an -s on the end• Irregulars stay as is
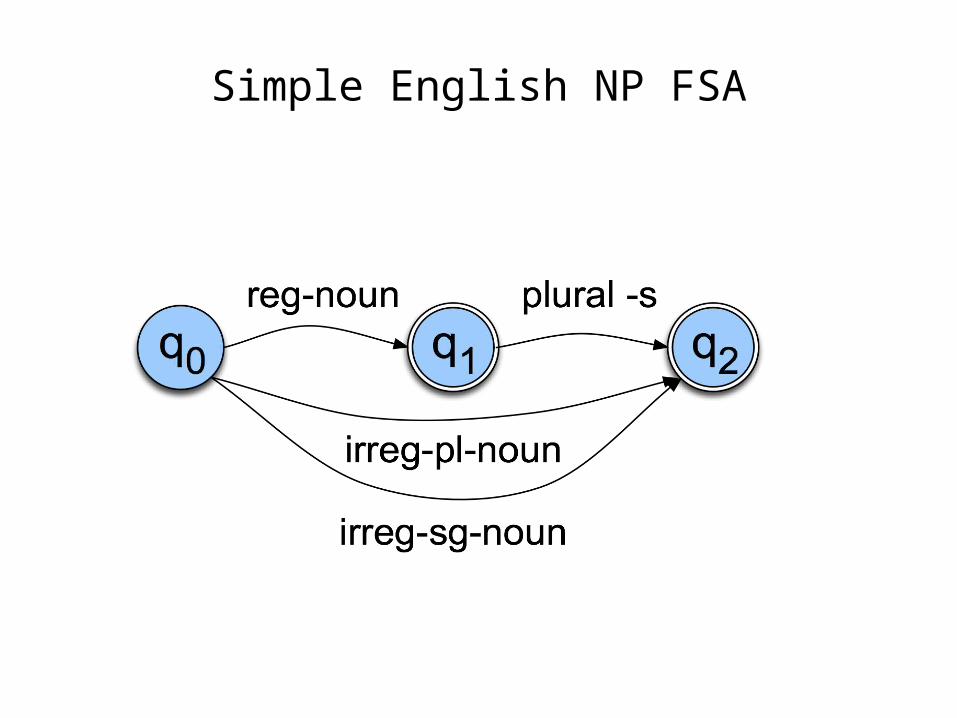
Simple English NP FSA
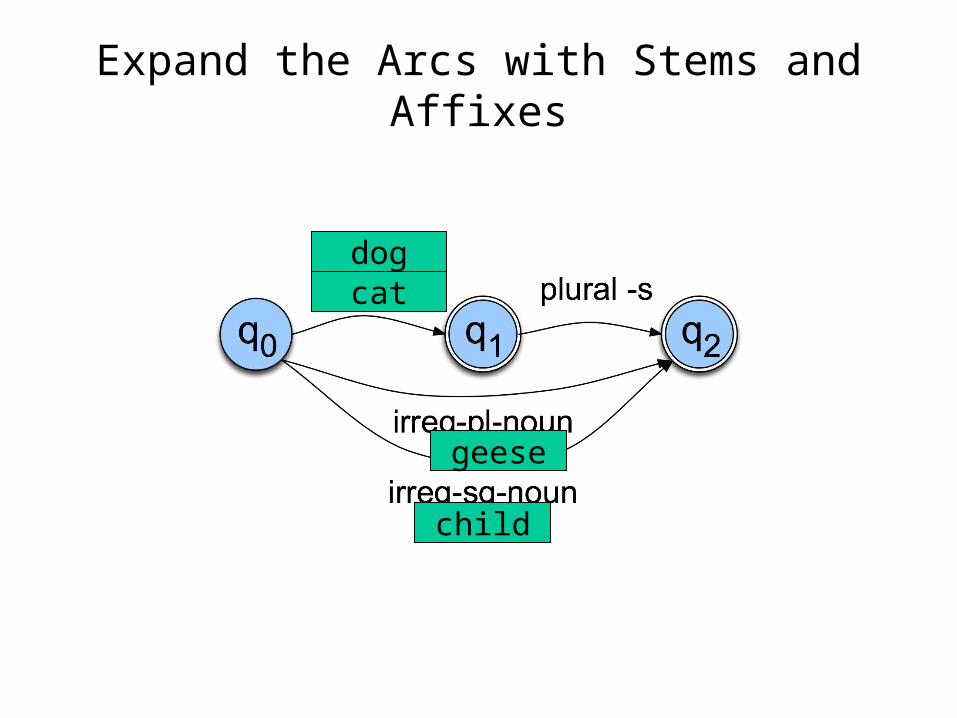
Expand the Arcs with Stems and Affixes
catdog
child
geese

• We can now run strings through these machines to recognize strings in the language• Accept words that are ok• Reject words that are not
• But is this enough?• We often want to know the structure of a word
(understanding/parsing)• Or we may have a stem and want to produce a surface form
(production/generation)
• Example• From “cats” to “cat +N +PL”• From “cat + N + PL” to “cats”

Finite State Transducers (FSTs)
• Turning an FSA into an FST• Add another tape• Add extra symbols to the transitions• On one tape we read “cats” -- on the other we
write “cat +N +PL”• Or vice versa…

Kimmo Koskenniemi’s two-level morphologyIdea: a word is a relationship between lexical level (its morphemes) and surface level (its orthography)
Koskenniemi 2-level Morphology
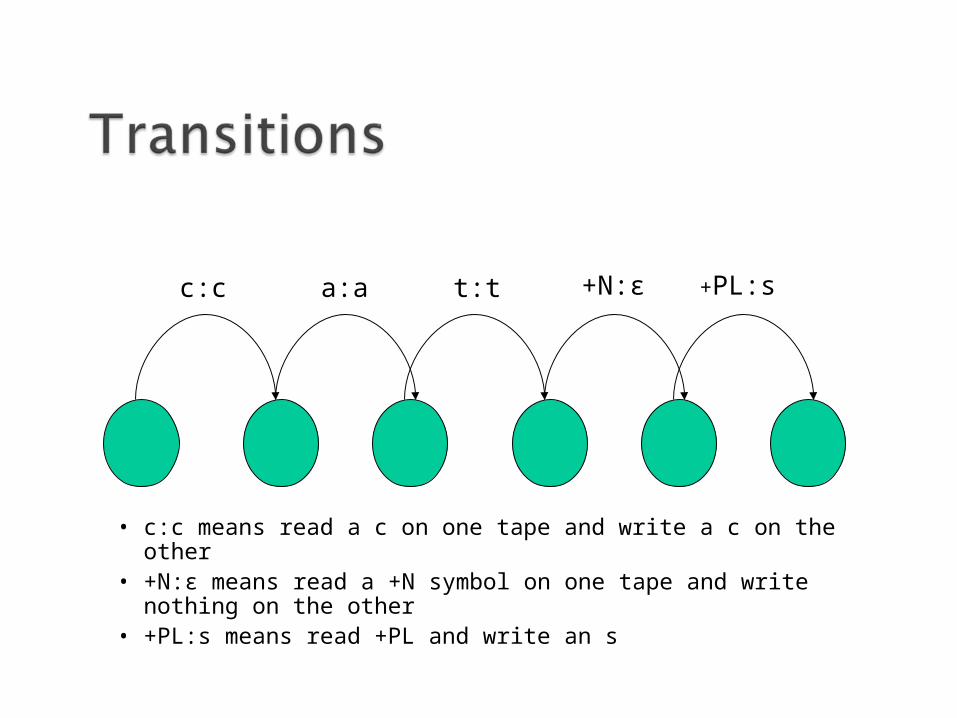
• c:c means read a c on one tape and write a c on the other• +N:ε means read a +N symbol on one tape and write nothing on the other• +PL:s means read +PL and write an s
c:c a:a t:t +N:ε +PL:s

Not So Simple
• Of course, its not all as easy as • “cat +N +PL” <-> “cats”
• What do we do about geese, mice, oxen?• Many spelling/pronunciation changes go along with
inflectional changes, e.g.• Fox and Foxes

Multi-Tape Machines
• Solution for complex changes:– Add more tapes – Use output of one tape machine as input to the
next• To handle irregular spelling changes, add
intermediate tapes with intermediate symbols

Example of a Multi-Tape Machine
• We use one machine to transduce between the lexical and the intermediate level, and another to transduce between the intermediate and the surface tapes
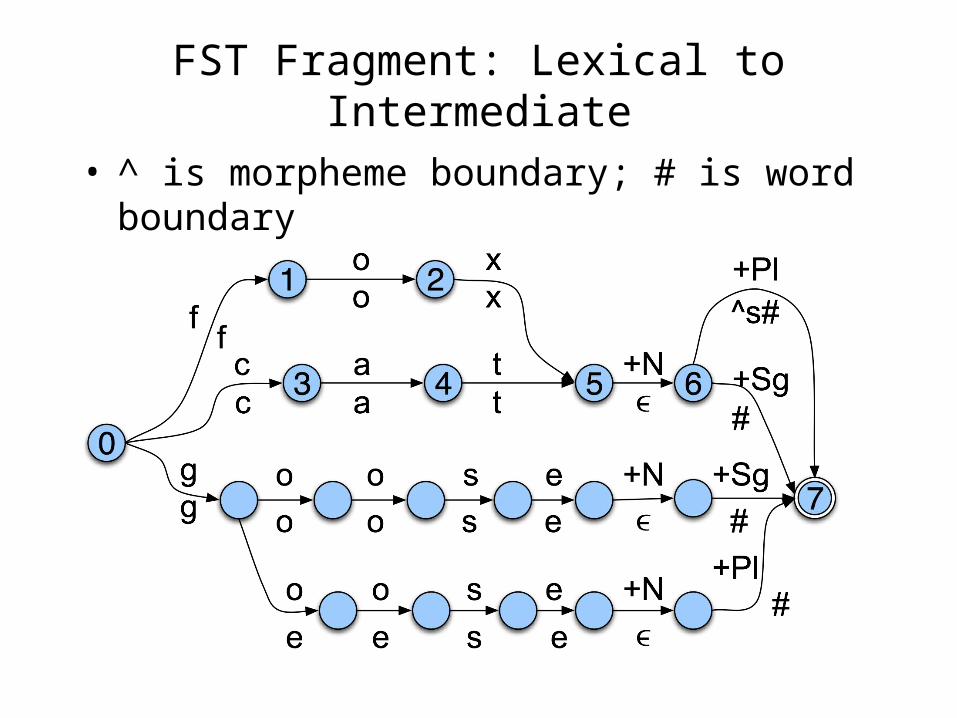
FST Fragment: Lexical to Intermediate
• ^ is morpheme boundary; # is word boundary
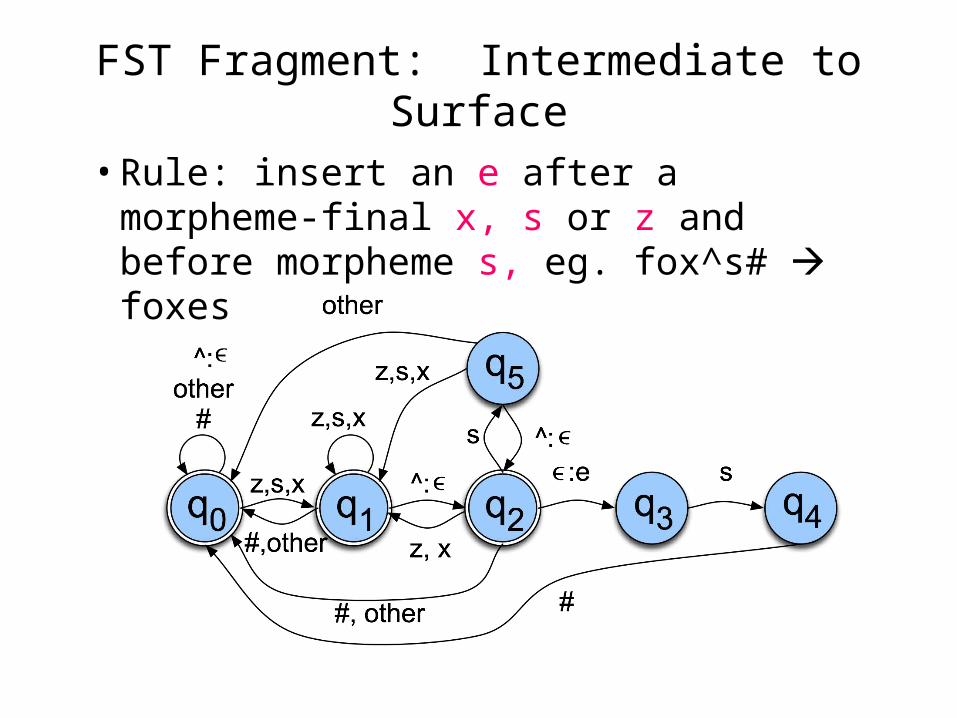
FST Fragment: Intermediate to Surface
• Rule: insert an e after a morpheme-final x, s or z and before morpheme s, eg. fox^s# foxes
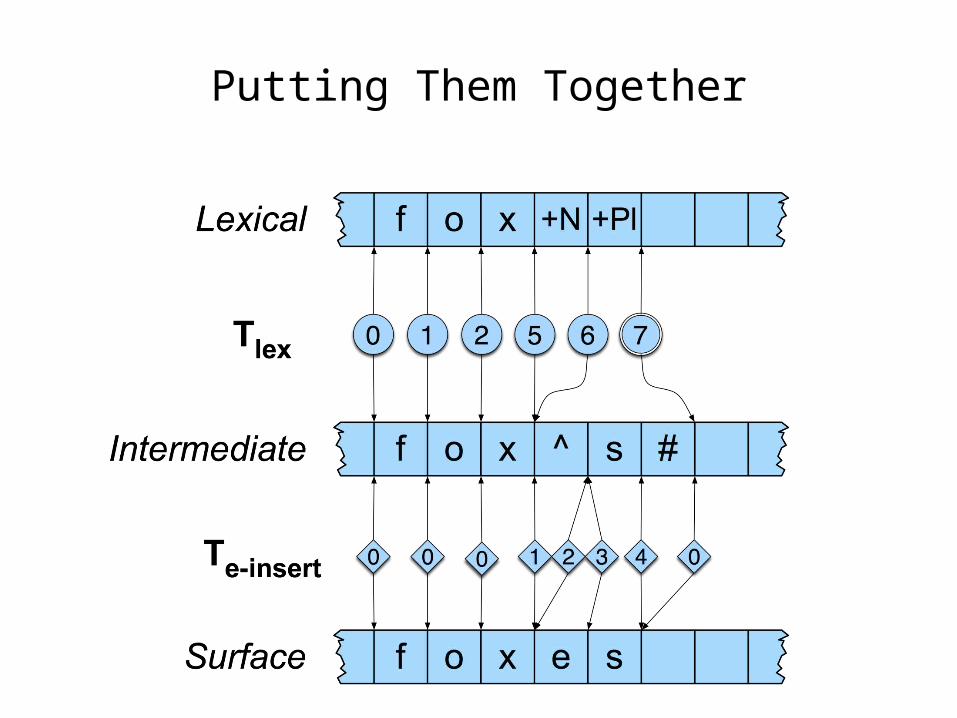
Putting Them Together

Practical Uses
• This kind of parsing is normally called morphological analysis
• Can be • An important stand-alone component of an
application (spelling correction, information retrieval, part-of-speech tagging,…)
• Or simply a link in a chain of processing (machine translation, parsing,…)

Porter Stemmer (1980)
• Standard, very popular and usable stemmer (IR, IE) – identify a word’s stem
• Sequence of cascaded rewrite rules, e.g.– IZE ε (e.g. unionize union)– CY T (e.g. frequency frequent)– ING ε , if stem contains vowel (motoring
motor)• Can be implemented as a lexicon-free FST (many
implementations available on the web)

Important Note: Morphology Differs by Language
• Languages differ in how they encode morphological information– Isolating languages (e.g. Cantonese) have no
affixes: each word usually has 1 morpheme– Agglutinative languages (e.g. Finnish, Turkish)
are composed of prefixes and suffixes added to a stem (like beads on a string) – each feature realized by a single affix, e.g. Finnishepäjärjestelmällistyttämättömyydellänsäkäänköhän ‘Wonder if he can also ... with his capability of not
causing things to be unsystematic’

– Polysynthetic languages (e.g. Inuit languages) express much of their syntax in their morphology, incorporating a verb’s arguments into the verb, e.g. Western Greenlandic
Aliikusersuillammassuaanerartassagaluarpaalli.aliiku-sersu-i-llammas-sua-a-nerar-ta-ssa-galuar-paal-lientertainment-provide-SEMITRANS-one.good.at-COP-say.that-REP-FUT-sure.but-3.PL.SUBJ/3SG.OBJ-but'However, they will say that he is a great entertainer, but ...'
– So….different languages may require very different morphological analyzers

Concatenative vs. Non-concatenative Morphology
• Semitic root-and-pattern morphology– Root (2-4 consonants) conveys basic semantics
(e.g. Arabic /ktb/)– Vowel pattern conveys voice and aspect– Derivational template (binyan) identifies word
class

Template Vowel Pattern
active passive
CVCVC katab kutib write
CVCCVC kattab kuttib cause to write
CVVCVC ka:tab ku:tib correspond
tVCVVCVC taka:tab tuku:tib write each other
nCVVCVC nka:tab nku:tib subscribe
CtVCVC ktatab ktutib write
stVCCVC staktab stuktib dictate

Morphological Representations: Evidence from Human Performance
• Hypotheses:– Full listing hypothesis: words listed – Minimum redundancy hypothesis:
morphemes listed• Experimental evidence:
– Priming experiments (Does seeing/hearing one word facilitate recognition of another?) suggest something in between
• Regularly inflected forms (e.g. cars) prime stem (car) but not derived forms (e.g. management, manage)

• But spoken derived words can prime stems if they are semantically close (e.g. government/govern but not department/depart)
• Speech errors suggest affixes must be represented separately in the mental lexicon– ‘easy enoughly’ for ‘easily enough’
• Importance of morphological family size– Larger families faster recognition

Summing Up
• Regular expressions and FSAs can represent subsets of natural language as well as regular languages– Both representations may be difficult for humans to
understand for any real subset of a language
– Can be hard to scale up: e.g., when many choices at any point (e.g. surnames)
– But quick, powerful and easy to use for small problems
– AT&T Finite State Toolkit does scale
• Next class: – Read Ch 4 on Ngrams
– HW1 will be due at midnight on Oct 1





























