Embed Size (px)
Citation preview

4
BAB II
TINJAUAN PUSTAKA DAN LANDASAN TEORI
2.1 Tinjauan Pustaka
Sebagai tinjauan pustaka, berikut beberapa contoh penelitian telapak kaki
yang sudah dilakukan oleh para peneliti yang dapat digunakan sebagai acuan dan
pengetahuan.
Fadhlillah et al, (2015), Analisis dan Implementasi Klasifikasi K-Nearest
Neighbor (K-NN) Pada Sistem Identifikasi Biometrik Telapak Kaki Manusia,
dalam penelitiannya menjelaskan bahwa pengenalan individu menjadi bagian
penting dalam banyak aspek kehidupan modern untuk mendapakan informasi atau
identitas, contohnya pada kasus identifikasi bencana alam, tidak jarang korban
masih utuh, hal ini menjadi sulit diidentifikasi, salah satu solusi ialah dengan
penenalan telapak kaki, biometrika telapak kaki dapat dimanfaatkan sebagai
pengenalan individu yang akurat dengan metode K-Nearest Neighbor (KNN),
biometrika telapak kaki memenuhi persyaratan pemilihan biometrika yaitu
universal, membedakan, dan permanen, dimana nilai K dari klasifikasi akan
disesuaikan sehingga menghasilkan akurasi terbaik. Dalam proses identifikasinya
sistem mulanya mengambil seluruh penampakan citra telapak kaki, kemudian
secara otomatis memotong citra pada bagian yang diinginkan dengan ukuran
seragam. Metode ekstraksi ciri Haar Wavelet digunakan untuk mendapatkan ciri-
ciri citra, kemudian diklasifikasikan dengan metode KNN yang akan menghasilkan
parameter kerja sistem berupa akurasi. Untuk hasil pengujian. dalam
mengidentifikasi telapak kaki manusia dengan metode K-NN mencapai hasil 98%
dengan pendekatan Euclidean Distance, dan Cosine Distance.
Rafki et al, (2016), Pengklasifikasian Tinggi dan Berat Badan Manusia
Berdasarkan Citra Telapak Kaki Dengan Metode Discrete Cosine Transform (DCT)
dan Nearest Neighbor (NN) Berbasis Android, dalam penelitiannya menjelaskan
bahwa diawali dengan proses preprocessing yang terdiri dari konversi citra ke
Grayscale, Histogram Equalization, Otsu Thresholding , dan konversi gambar ke

5
black and white sehingga didapat nilai akurasi terbaik sebesar 87,50% untuk deteksi
tinggi badan dan 87,06% untuk deteksi berat badan.
Perangin-Angin , M. A. (2016), Pengklasifikasian Tinggi Dan Berat Badan
Manusia Berdasarkan Citra Telapak Kaki Dengan Menggunakan Metode Discrete
Wavelet Transform (DWT) Dan K-Nearest Neighbor (KNN) Berbasis Android,
dalam penelitiannya menjelaskan bahwa dengan menggunakan sampel cap telapak
kaki mampu mengukur tinggi dan berat badan manusia dengan tinggi akurasi
terbaik yaitu 75%.
Sinaga, I. S. A. (2015), Implementasi Jaringan Syaraf Tiruan Self
Organizing Map Kohonen dalam pengenalan Telapak Kaki Bayi, dalam
penelitiannya menjelaskan bahwa untuk mencegah kasus bayi tertukar dapat
digunakan ciri unik untuk membedakan bayi satu dengan lainnya, teknologi
jaringan syaraf tiruan yang digunakan untuk membantu proses identifikasi bayi,
penelitiannya menggunakan citra cap telapak kaki yang berektensi *.jpg terlebih
dahulu difilter menggunakan highpass filtering untuk mempertajam detail citra, dan
terakhir dideteksi tepi Canny untuk menandai bagian yang menjadi detail citra.
Hasil deteksi tepi berupa citra biner yang kemudian matrik citra biner ini digunaan
untuk dilatih dan diuji menggunakan metode SOM Kohonen. Gambar yang dilatih
berupa 10 gambar cap telapak kaki bayi asli dan 20 lainnya adalah citra asli yang
telah diberi noise. Hasil akhir berupa identifikasi telapak kaki bayi berdasarkan
hasil pelatihan. Dan hasil pengujian terhadap citra yang dilatih menunjukkan
tingkat akurasi pengenalan sebesar 90% dan persentase akurasi pengenalan untuk
citra yang tidak dilatih sebesar 60%.
Tomuka, J., et all (2016), Hubungan Panjang Telapak Kaki dengan Tinggi
Badan untuk Identifikasi Forensik, dalam penelitiannya menjelaskan bahwa dalam
upaya yang bertujuan membantu penyidik dalam menentukan identitas seseorang
yang sangat penting dalam peradilan, salah satu cara identifikasi ialah dengan
antropometri forensik. Peran antropometri foreksik menjadi salah satu cabang
antropologi khususnya antropologi ragawi dalam menunjang pelayanan dokter
forensik didasarkan pada kemampuan pemeriksaan antropologis untuk menilai dan
merekontruksi gambaran biologis individu manusia. Metode dalam antropologi

6
forensik yaitu dapat digunakan untuk identifikasi ialah antropometri yaitu dengan
cara mengukur bagian-bagian tubuh, pengukuran antropometri berdasarkan tinggi
badan, panjang dan lebar kepala, sidik jari, bentuk hidung, telinga, dagu, warna
kulit, warna rambut, tanda pada tubuh, serta DNA.
2.2 Landasan Teori
2.2.1 Pengenalan Pola
Pengenalan pola (pattern recognition) adalah suatu ilmu untuk
mengklasifikasikan atau menggambarkan sesuatu berdasarkan pengukuran
kuantitatif fitur (ciri) atau sifat utama dari suatu obyek (Putra, 2010).
Pengenalan pola bertujuan menentukan kelompok atau kategori pola
berdasarkan ciri-ciri yang dimiliki oleh pola tersebut. Dengan kata lain, pengenalan
pola membedakan suatu obyek dengan obyek yang lain.
2.2.2 Citra Digital
Citra digital merupakan sebuah gambaran dua dimensi berupa matriks
berukuran tertentu yang diwakili oleh baris dan kolom. Pada sebuah citra digital
perpotongan antara baris dan kolom disebut dengan pixels, pels atau picture
elements. Pixels (picture elements atau pels) merupakan elemen terkecil dari sebuah
citra.
Suatu citra dapat didefinisikan sebagai fungsi f(x,y) berukuran M baris
dan N kolom, dengan x dan y adalah koordinat spasial, dan amplitudo f di titik
koordinat (x,y) dinamakan intensitas atau tingkat keabuan dari citra pada titik
tersebut. Apabila nilai x,y dan nilai amplitudo f secara keseluruhan berhingga
(finite) dan bernilai diskrit maka dapat dikatakan bahwa citra tersebut adalah citra
digital.
Citra digital dapat diolah dengan komputer digital, maka suatu citra harus
dipresentasikan secara numerik dengan nilai-nilai diskrit. Representasi citra dari
fungsi malar (kontinu) menjadi nilai-nilai diskrit tersebut digitalisasi (Munir, 2004).
Terdapat 3 jenis format warna citra, antara lain:
a. Citra biner/Citra hitam putih

7
Citra biner merupakan citra yang berwarna hitam dan putih. Dibutuhkan 1
bit untuk menyimpan kedua warna tersebut didalam memori, dimana bit 0
menyatakan warna hitam dan bit 1 menyatakan warna putih.
Gambar 2.1 Citra Biner
b. Citra Grayscale
Citra grayscale adalah citra satu kanal dengan fungsi f(x,y) yang
menyatakan tingkat keabuan suatu citra dari gambar hitam ke putih. Setiap piksel
dari citra grayscale terdiri dari 256 gradasi warna yang diwakili oleh 1 byte yaitu
dari 0-255 atau 8 bit level.
Gambar 2.2 Representasi Tingkat Keabuan
c. Citra Warna/Citra RGB
Citra warna adalah citra yang memiliki tiga komponen, yaitu merah (red),
hijau (green) dan biru (blue). Pada citra warna sebuah piksel diwakili 3 byte, dimana
masing-masing byte tersebut merepresentasikan warna merah (red), hijau (green)
dan biru (blue). Setiap warna dasar menggunakan penyimpanan 8 bit = 1 byte, yang
berarti setiap warna mempunyai gradasi sebanyak 255 warna. Berarti setiap piksel
mempunyai kombinasi warna sebanyak 224 = 16 juta warna lebih.

8
Gambar 2.3 Citra Warna
2.2.3 Akuisisi Data
Akuisisi data adalah tahap dalam mendapatkan citra dengan tujuan untuk
menentukan data yang dibutuhkan dan memilih metode dalam perekaman citra
digital. Langkah-langkah yang dilakukan dalam tahap ini secara umum dimulai dari
persiapan obyek yang akan diambil citranya, alat-alat sampai pada pencitraan.
Pencitraan yaitu kegiatan transformasi dari citra tampak (foto, gambar,
lukisan, patung, dan lain-lain) menjadi citra digital. Beberapa alat yang dapat
digunakan untuk pencitraan adalah: kamera vidio, kamera digital, scanner, foto
sinar-x/infra merah.
2.2.4 Preprocessing
Preprocessing adalah proses pengolahan data asli sebelum data tersebut di
ekstraksi ciri.
a. Cropping
Cropping adalah proses memotong citra pada koordinat tertentu dalam citra.
Proses ini sangat penting dilakukan sebelum citra diproses untuk diambil cirinya,
agar mendapatkan bagian citra yang dianggap penting dan memiliki banyak
informasi.
b. Resize
Resize adalah proses mengubah atau mengurangi ukuran citra menjadi
ukuran tertentu. Proses ini adalah proses pelengkap dari cropping citra, yang
bertujuan agar proses komputasi menjadi lebih cepat.

9
c. Grayscale
Grayscale adalah citra satu kanal dengan fungsi f(x,y) yang menyatakan
tingkat keabuan suatu citra dari gambar hitam ke putih. Untuk mendapatkan citra
grayscale (aras keabuan) digunakan rumus:
𝐼(𝑥, 𝑦) = 𝛼. 𝑅 + 𝛽. 𝐺 + 𝛾. 𝐵............................................................................. (2.1)
Dengan I(x,y) adalah level keabuan pada suatu koordinat yang diperoleh dengan
mengatur komposisi warna R (merah), G (hijau), B (biru) yang ditunjukkan oleh
nilai parameter α, β, dan γ. Nilai yang lain juga dapat diberikan untuk ketiga
parameter tersebut asalkan total nilai keseluruhannya adalah 1 (Putra, 2010).
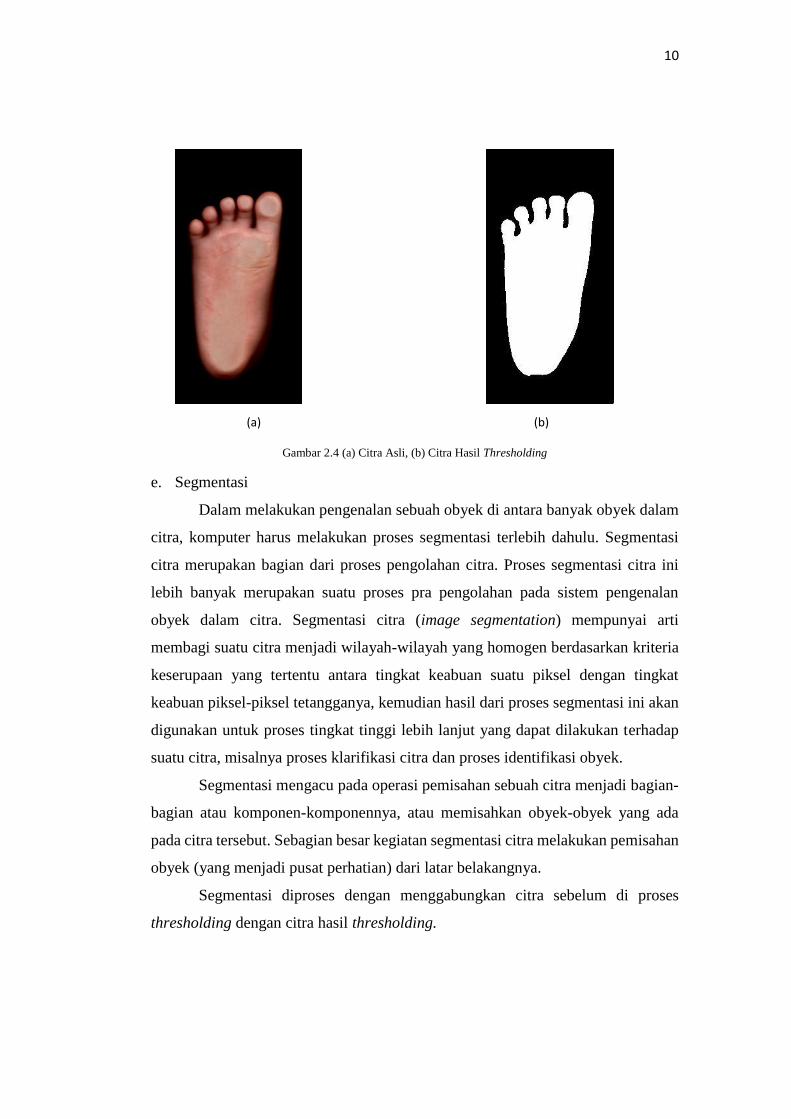
d. Thresholding
Thresholding adalah proses mengubah citra berderajat keabuan menjadi
citra biner atau hitam putih sehingga dapat diketahui daerah mana yang termasuk
obyek dan latar belakang dari citra secara jelas.
Hal yang perlu diperhatikan pada proses threshold adalah memilih sebuah
nilai threshold (T) dimana piksel yang bernilai dibawah nilai threshold akan diset
menjadi hitam dan piksel yang bernilai diatas nilai threshold akan diset menjadi
putih. Atau dinyatakan,
𝑦 = {𝑝𝑢𝑡𝑖ℎ 𝑗𝑖𝑘𝑎 𝑥 > 𝑇
ℎ𝑖𝑡𝑎𝑚 𝑗𝑖𝑘𝑎 𝑥 ≤ 𝑇 .............................................................................(2.2)
Dengan x adalah nilai aras keabuan dari citra input (asli), T adalah nilai ambang
yang dipilih, dan y adalah keluaran. Thresholding merupakan bagian yang penting
dalam segmentasi citra, misalnya saat dikehendaki untuk mengisolasi suatu obyek
tertentu dari latar belakangnya. Dewasa ini juga digunakan sebagai bagian dari
penglihatan robot (robot vision).
10
(a) (b)
Gambar 2.4 (a) Citra Asli, (b) Citra Hasil Thresholding
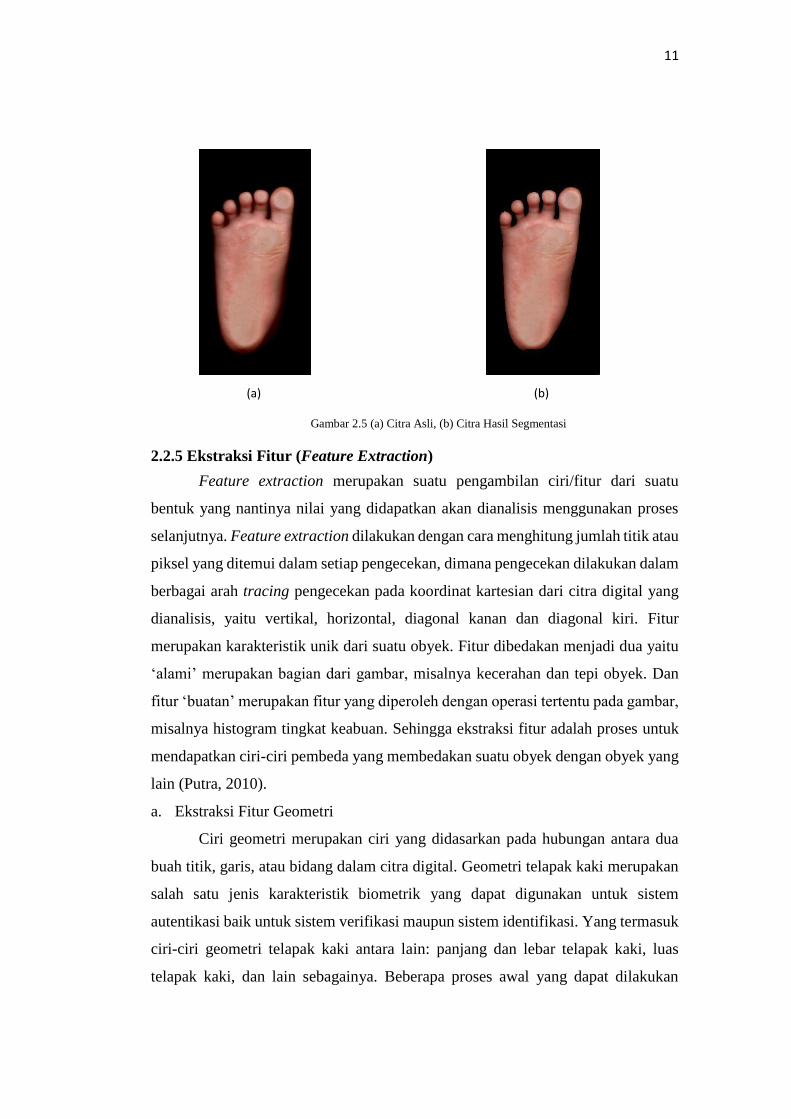
e. Segmentasi
Dalam melakukan pengenalan sebuah obyek di antara banyak obyek dalam
citra, komputer harus melakukan proses segmentasi terlebih dahulu. Segmentasi
citra merupakan bagian dari proses pengolahan citra. Proses segmentasi citra ini
lebih banyak merupakan suatu proses pra pengolahan pada sistem pengenalan
obyek dalam citra. Segmentasi citra (image segmentation) mempunyai arti
membagi suatu citra menjadi wilayah-wilayah yang homogen berdasarkan kriteria
keserupaan yang tertentu antara tingkat keabuan suatu piksel dengan tingkat
keabuan piksel-piksel tetangganya, kemudian hasil dari proses segmentasi ini akan
digunakan untuk proses tingkat tinggi lebih lanjut yang dapat dilakukan terhadap
suatu citra, misalnya proses klarifikasi citra dan proses identifikasi obyek.
Segmentasi mengacu pada operasi pemisahan sebuah citra menjadi bagian-
bagian atau komponen-komponennya, atau memisahkan obyek-obyek yang ada
pada citra tersebut. Sebagian besar kegiatan segmentasi citra melakukan pemisahan
obyek (yang menjadi pusat perhatian) dari latar belakangnya.
Segmentasi diproses dengan menggabungkan citra sebelum di proses
thresholding dengan citra hasil thresholding.
11
(a) (b)
Gambar 2.5 (a) Citra Asli, (b) Citra Hasil Segmentasi
2.2.5 Ekstraksi Fitur (Feature Extraction)
Feature extraction merupakan suatu pengambilan ciri/fitur dari suatu
bentuk yang nantinya nilai yang didapatkan akan dianalisis menggunakan proses
selanjutnya. Feature extraction dilakukan dengan cara menghitung jumlah titik atau
piksel yang ditemui dalam setiap pengecekan, dimana pengecekan dilakukan dalam
berbagai arah tracing pengecekan pada koordinat kartesian dari citra digital yang
dianalisis, yaitu vertikal, horizontal, diagonal kanan dan diagonal kiri. Fitur
merupakan karakteristik unik dari suatu obyek. Fitur dibedakan menjadi dua yaitu
‘alami’ merupakan bagian dari gambar, misalnya kecerahan dan tepi obyek. Dan
fitur ‘buatan’ merupakan fitur yang diperoleh dengan operasi tertentu pada gambar,
misalnya histogram tingkat keabuan. Sehingga ekstraksi fitur adalah proses untuk
mendapatkan ciri-ciri pembeda yang membedakan suatu obyek dengan obyek yang
lain (Putra, 2010).
a. Ekstraksi Fitur Geometri
Ciri geometri merupakan ciri yang didasarkan pada hubungan antara dua
buah titik, garis, atau bidang dalam citra digital. Geometri telapak kaki merupakan
salah satu jenis karakteristik biometrik yang dapat digunakan untuk sistem
autentikasi baik untuk sistem verifikasi maupun sistem identifikasi. Yang termasuk
ciri-ciri geometri telapak kaki antara lain: panjang dan lebar telapak kaki, luas
telapak kaki, dan lain sebagainya. Beberapa proses awal yang dapat dilakukan
12
untuk mempermudah mendapatkan ciri-ciri geometri telapak kaki adalah binerisasi.
Proses binerisasi menghasilkan citra biner dengan memiliki dua nilai tingkat
keabuan yaitu hitam dan putih.
b. Ekstraksi Fitur Warna Aras Keabuan
Pada citra berskala keabuan, jumlah aras keabuan (biasa disimbolkan
dengan L) sebanyak 256. Misalkan citra digital memiliki L derajat keabuan, yaitu
dari nilai 0 sampai L – 1 (misalnya pada citra dengan kuantisasi derajat keabuan 8-
bit, nilai derajat keabuan dari 0 sampai 255). Secara matematis histogram citra
dihitung dengan rumus:
ℎ𝑖 =𝑛𝑖
𝑛 , i = 0, 1, … , L − 1 ...............................................................(2.3)
Yang dalam hal ini,
𝑛𝑖 = jumlah piksel yang memiliki derajat keabuan i
𝑛 = jumlah seluruh piksel di dalam citra
Plot ℎ𝑖 versus 𝑓𝑖 dinamakan histrogram. Gambar 2.6 adalah contoh sebuah
histogram citra. Secara grafis histogram ditampilkan dengan diagram batang.
Gambar 2.6 Histogram Citra
Rumus rata-rata atau mean aras keabuan:
�̅� =∑ 𝑥𝑖
𝑛𝑖=1
𝑛 .................................................................................................. (2.4)
Keterangan:
�̅� = rata-rata

13
𝑥𝑖 = nilai piksel ke-i
𝑛 = jumlah piksel
Rumus standar deviasi aras keabuan:
𝑠 = √∑ (𝑥𝑖− �̅�)2𝑛
𝑖=1
𝑛−1 ....................................................................................... (2.5)
Keterangan:
�̅� = rata-rata
𝑥𝑖 = nilai piksel ke-i
𝑛 = jumlah piksel
2.2.6 K-Nearest Neighbor
Metode klasifikasi algoritma KNN merupakan salah satu metode
pengklasifikasian data yang memiliki konsistensi yang kuat, dengan cara mencari
kasus dengan menghitung kedekatan antara kasus baru dengan kasus lama
berdasarkan pencocokan bobot (Lutfhi & Kusrini, 2009). KNN termasuk algoritma
supervised learning dimana hasil dari query instance yang baru diklasifikasikan
berdasarkan mayoritas dari kategori pada KNN. Kelas yang paling banyak muncul
yang akan menjadi kelas hasil klasifikasi.
Tujuan dari algoritma ini adalah mengklasifikasikan obyek baru
berdasarkan atribut dan training sample. Classifier tidak menggunakan model
apapun untuk dicocokkan dan hanya berdasarkan pada memori. Diberikan titik
query, akan ditemukan sejumlah k obyek atau (titik training) yang paling dekat
dangan titik query. Klasifikasi menggunakan voting terbanyak diantara klasifikasi
dari k obyek. Algoritma k-nearest neighbor (KNN) menggunakan klasifikasi
ketetanggaan sebagai nilai prediksi dari query instance yang baru.
Algoritma metode KNN sangatlah sederhana, bekerja berdasarkan jarak
terpendek dari query instance ke training sample untuk menentukan KNN-nya.
Training sample diproyeksikan ke ruang berdimensi banyak, dimana masing-

14
masing dimensi merepresentasikan fitur dari data. Ruang ini dibagi menjadi bagian-
bagian berdasarkann klasifikasi training sample. Sebuah titik pada ruang ini
ditandai kelas c jika kelas c merupakan klasifikasi yang paling banyak ditemui pada
k buah tetangga terdekat dari titik tersebut. Dekat atau jauhnya tetangga biasanya
dihitung berdasarkan Euclidean Distance.
Eucledian distance paling sering digunakan dalam menghitung dekat atau
jauhnya tetangga. Eucledian Distance berfungsi menguji ukuran yang bisa
digunakan sebagai interpretasi kedekatan jarak antara dua obyek. Yang
dipresentasikan pada Persamaan 2.5.
𝐷𝑖𝑗 = [ (𝑥𝑖 − 𝑥𝑗)2 + (𝑦𝑖 − 𝑦𝑗)2 ] ................................................................... (2.6)
Dimana D(i,j) adalah jarak skalar dari kedua vektor i dan j dari matriks dengan
ukuran D dimensi.
Semakin besar nilai D akan semakin jauh tingkat keserupaan antara kedua
individu dan sebaliknya jika nilai D semakin kecil maka akan semakin dekat tingkat
keserupaan antara individu tersebut. Nikai k yang terbaik untuk algoritma ini
tergantung pada data. Secara umum, nilai k yang tinggi akan mengurangi efek noise
pada klasifikasi, tetapi membuat batasan antara setiap klasifikasi menjadi semakin
kabur.
Nilai k yang bagus dapat dipilih dengan optimasi parameter, misalnya
dengan menggunakan cross-validation. Kasus khusus dimana klasifikasi
diprediksikan berdasarkan training data yang paling dekat (dengan kata lain, k=1)
disebut algoritma nearest neighbor.
Ketetapan algoritma K-NN sangat dipengaruhi oleh ada atau tidaknya fitur-
fitur yang tidak relevan atau jika bobot fitur tersebut tidak setara dengan
relevansinya terhadap klasifikasi. Riset terhadap algoritma ini sebagian besar
membahas bagaimana memilih dan memberi bobot terhadap fitur agar performa
klasifikasi menjadi lebih baik. Langkah-langkah untuk menghitung algoritma K-
NN.
1. Menentukan nilai k.

15
2. Menghitung kuadrat Eucledian Distance masing-masing obyek terhadap data
training yang diberikan.
3. Mengurutkan obyek-obyek tersebut ke dalam kelompok yang mempunyai
Eucledian Distance terkecil.
4. Mengumpulkan label kelas Y (klasifikasi Nearest Neighbor).
Dengan menggunkan kategori Nearest Neighbor yang paling mayoritas maka dapat
diprediksikan nilai query instance yang telah dihitung.





























