Embed Size (px)
Citation preview
![Page 1: Automatic Large Scale Generation of Internet PoP …shavitt/pub/Globecom08.pdf · Automatic Large Scale Generation of Internet PoP Level Maps ... there was criticism [10] ... high](https://reader042.dokumen.tips/reader042/viewer/2022030921/5b793da37f8b9a31308d4d1f/html5/page/1.jpg)
Automatic Large Scale Generation of Internet PoPLevel Maps
Dima FeldmanTel-Aviv University
Yuval ShavittTel-Aviv University
Abstract—Point of presence (PoP) level Internet mapsare promising for tasks such as reasoning about theInternet evolution in time or Internet delay estimation. Wethus suggest an efficient algorithm for generating PoP levelInternet maps directly from the traceroute measurementresults. The algorithm avoids the noisy process of interfaceaggregation to routers. The PoP level maps we obtainare annotated with PoP level link delay. Both the maptopography and the link delay estimation for tens of ASeswere validated with a combination of DNS names and twogeo-IP databases, and were found satisfactory.
I. INTRODUCTION
Studying the Internet structure and evolution is arather young research thread that was initiated by thepioneering work of Faloutsos et al. [1]. The first workslooked mostly at the static characterization of the In-ternet graph at certain points in time [2], [3], but laterresearchers tried to understand how the network evolve,and suggested models to explain the network evolution[4], [5], [6]. These models were mainly evolving in theabstract Internet AS graph with no connection to the realworld, or with some naive connection with the Internetunderlaying geography. Recently, there is a growingunderstanding that the evolution of an Internet regionshould be estimated by tightly correlating the Internetstructure with its underlying geography, and the changesin the economic, social, and even political evolution ofthe region in question. For example, it is no surprisethat as the economy of a certain region grows it willresult in greater demand for Internet connectivity, whichwill manifested as growth in the Internet graph relate tothis region. There are only a few works in this researchdirection [7], [8] due to the difficulty of obtaining goodInternet maps.
Internet maps can be drawn in several levels of ab-straction, each is suitable for studying various aspectsof the network. The most commonly used abstraction isthe autonomous systems (AS) level graph which has arelatively small amount of nodes (a few tens of thousands
of ASes) and thus it is easy to handle. While it is usefulfor many purposes, the AS representation of the Internetlacks a geographic grip. There are many large- crosscountry and cross Atlantic ASes that are represented bya single node on the AS level graph, virtually connectingASes that have large physical distance between them. Inaddition, AS sizes spread over three orders of magnitudewhich makes any growth model on the AS graph unre-liable. For example, the growth of a large AS by 25%is more significant than the addition of several tiny stubASes, yet the former will not show any change in thenumber of nodes in the AS level while the latter willshow a network growth. The other extreme is to use therouter level graph, which contain too many details formost practical uses, and due to its large size it is hard toimagine a mapping system for obtaining a reliable graphat this level and track its evolution in time.
Large ASes are not spread uniformly in the area theyspan, but typically are build from a rather small numberof points of presence (PoPs). A PoP is a concentrationof router and other networking devices in a campusfrom which Internet connectivity is offered to the regionaround it, typically at least a large metropolitan area. Forsimplicity of the writing, small ISPs and customer ISPscan be treated as a single PoP ISP. Thus, by partitioninglarge and medium ISPs to their PoPs and looking atthe PoP connectivity map we have a map with twoadvantages. First, each PoP is now distinctly relatedto some metropolitan geographic area allowing us tocorrelate its characteristics (e.g., birth time, connectivity)with the characteristics of the real world of its region.Second, all the nodes in the PoP level map are roughlythe same size, whether these are PoPs or small ISPs,making growth model relevant for this abstraction.
In this work, we suggest a novel algorithm for theautomatic construction of PoP level maps. Rocketfuel[9] is the only work we’re aware of to suggest suchan algorithm, but despite its reported success by theauthors, there was criticism [10] about some of the
![Page 2: Automatic Large Scale Generation of Internet PoP …shavitt/pub/Globecom08.pdf · Automatic Large Scale Generation of Internet PoP Level Maps ... there was criticism [10] ... high](https://reader042.dokumen.tips/reader042/viewer/2022030921/5b793da37f8b9a31308d4d1f/html5/page/2.jpg)
2
techniques they used, in particular their reliance onDNS. We have shown [11] that, indeed, DNS introducesnoise to the PoP partition. Rocketfuel partition an ISPby first aggregating IP interfaces into routers and thenaggregating routers into PoPs. The first stage is theone where the DNS resolution noise is injected. Wesuggest, instead, to skip the IP to router aggregationphase and use a novel partitioning algorithm on the IPinterface graph. At the end of the process, we generate alist of interfaces per PoP without the internal divisionof the PoP to routers. For the Internet modeling wetarget, and for many other tasks this is sufficient. Weargue that the partitioning of IP interfaces to routers isnot functionally important: for most practical matters, asingle huge router functions similarly to a small groupof routers in the same room which are inter-connectedby a high speed network. In particular, for the Internetevolution models and for Internet distance maps, whichare the two prime motivations of this work, the partitionof IP interfaces to routers is certainly of little value.
We have been using the DIMES project [12], [13]measurement database for testing our PoP level mapextraction. The main advantage of using DIMES is itsenormous amounts of measurement and vantage points.DIMES is using a significantly higher amount of mea-surement agents from over two hundred vantage points,which measure at a higher rate than Rocketfuel (up to4 traceroute a minute vs. one every 1.5 minutes in theRocketfuel case).
There is one major difference between Rocketfuelgoal and ours. While they attempted to discover asmuch as possible of the PoP level topology of a fewISPs, we attempt to periodically reveal the PoP leveltopology of the entire Internet. However, due to theyet limited capacity of our collection system, we donot have sufficient capacity to obtain the entire InternetPoP level graph. Instead, we concentrate on correctnessand efficiency. In correctness we mean that we do notintroduce wrong PoPs or PoP to PoP links. Due tothe vast number of traceroute our system generates andperiodic nature of the application, efficiency is an im-portant feature of our algorithm: we can easily partitionhundreds of ASes to PoPs directly from the DIMEStraceroute database. Currently, we do not direct DIMESto measure in directions that will help the PoP topologyconstruction, but this is certainly a future goal.
A typical PoP consists of two or more backbone/-core routers and a number of client/access routers. Theclient/access routers are connected redundantly to morethan one core router, while core routers are connected
to other PoPs of the ISP [14], [9]. The typical PoPhas a clear bi-partite structure. However, we observethat when one uses traceroute probing from multiplesources to multiple destinations even simpler inter routerconnections create ‘bi-fans’1. We will use this type ofstructure to identify PoPs.
Beyond the topology, link delays can be calculatedefficiently out of traceroute measurements [17]. Intra-PoP delays are in the order of a few milliseconds whileinter-PoP delays grows linearly with distance (roughly1ms RTT for 100km). We use the link delay in the bi-partite graphs we find to distinguish between intra andinter PoP interconnections.
We run our algorithm on the one hundred top degreeASes, and for most cases got reasonable partition. Weclosely examined the partition for a few US-wide andworld wide providers, and compared the results with twogeo-IP databases and the DNS names of the interfaces.The PoP partition results appear to be in agreement withgeographic distances.
II. THE POP EXTRACTION ALGORITHM
As described in the introduction, network graphs col-lected by DIMES agents has specific structures that aretypical to the IP level internet graph. Alon et al. [15]showed that many complex networks has repetitivepatterns of interconnections, called ‘network motifs’,which became a standard term in the networks analysiscommunity. Their work showed that real-world networksoutside the communication field are not purely random,but have a higher than (or lower than) expected numberof specific motifs. In order to show the significance of aspecific motif, their mfinder [16] software package usesthe Z-score measure, which is calculated by
Z =X − µ
σ(1)
Where X is the number of occurrences of a motif ina specific network, and µ and σ is mean and standarddeviation of the motif occurrences within a randomnetwork with the same parameters. The Z-score revealshow many units of the standard deviation a specific caseis above or below the mean. Unsurprisingly, we havefound (using mfinder [16]) a number of motifs with ahigh Z-score across all the IP interface interconnectionnetworks of various ASes. For example, Table I showthe clear dominance of the ‘bi-fun’ motif (number 204)
1‘Bi-fan’ is a four node, specific network structure that was termedin [15]. In Section II the discussion about network motifs is extendedand the bi-fan motif is defined by id 204 in a Table I.
![Page 3: Automatic Large Scale Generation of Internet PoP …shavitt/pub/Globecom08.pdf · Automatic Large Scale Generation of Internet PoP Level Maps ... there was criticism [10] ... high](https://reader042.dokumen.tips/reader042/viewer/2022030921/5b793da37f8b9a31308d4d1f/html5/page/3.jpg)
3
TABLE ICOMMON NETWORK MOTIFS IN IP INTERCONNECTIONS NETWORKS OF THREE ASES.
Z-Score
AS NumberAS6395 377 - 9.51 43.84 148.39AS5111 329.29 36.42 - 74.63 73.57AS3549 154.8 5.38 37.87 19.51 -
in three large ISPs, Global Crossing, France Telecom,and Broadwind.
Although mfinder is a very useful tool for identifica-tion of important motifs, it is not designed to be usedfor network clustering. In our work we do not look fora specific motif in the network, but for highly connectedclusters. However, we do search for ‘bi-fun’s (id204)repetitions under a certain weight constrains as cores ofthe PoPs.
The algorithm works on the IP interface graph of asingle AS. We use the following steps to reduce the IPlevel graph G(V,E) to a PoP level network.
Initial Partition. We remove all edges with delayhigher than 5ms (namely 500km) and edges with ashorter delay but with a small number of measurements2.As a result, a non-connected graph G′ is obtained. Then,for each connected component of G′ we build an inducedsub graph3 of G. In cases when two or more sub graphsare connected by a few 5ms or less edges in G, they arealso connected to a single induced sub graph. Now, eachconnected group is a candidate to become one or morePoPs.
There are two reasons for a connected group to includemore than a single PoP. The first and most obviousreason is geographically adjacent PoPs, e.g., New York,NY and Newark, NJ. The other is caused by wrong delayestimation of a small amount of links. For instance asingle incorrectly estimated link between Los Angeles,CA and Dallas, TX might unify the groups obtained bysuch a naive method.
Refined Partition.
2Since, at this stage, we are trying to avoid false indication of PoPS,we take into account only links with a reliable delay estimation. Thus,we selected to use links with at least 10 traceroute measurements [17].
3A subgraph S of a graph G is said to be induced if, for any pairof vertices u and v of S, uv is an edge of S if and only if uv is anedge of G. In other words, induced subgraph is one that consists ofsome of the vertices of the original graph and all of the edges thatconnect them in the original graph.
(a) Parent-Child classification. Next, we checkwhether each connected group has more than one PoP.We note that each suspected partition looks like acollection of highly connected bipartite graphs withrich connectivity between them. Then we divide thewhole partition to parents and children according to themeasurement direction (each node or group of nodes si-multaneously can be parents of one bipartite and childrenof another) in the bipartite graph, in this operation weignore the weights of the edges. The minimal size ofeach group is two nodes, the process is described inSection II-A and the example of such a classificationis shown in Fig. 1.
(b) localization. Using the high connectivity of thebipartite graph, for each group (parents or children) wedivide the group to the physical collocations using thelocalization algorithm defined in Section II-B.
(c) Unification. Unifying parent/child group to thesame PoP. If parent pair and child pair groups are con-nected4, then we calculate the weighted distance betweenthe groups; if it is smaller than a certain threshold thepair of groups is declared as belonging to the same PoP.
Final Refinements.(a) Unification of loosely connected components. In
some cases, e.g., due to insufficient measurements, dif-ferent parts of a PoP are only loosely connected in away that does not form a bi-fan motif, in the extremecase only a single link connects two parts of a PoP.This will not allow the unification process, which isdescribed above, to identify the parts as belonging to thesame PoP. Thus, we look for connected components (PoPcandidates) that are connected by links whose mediandistance is very short (we chose 1mSec). Note that at thispoint, due to the unification process, the graph shrankconsiderably, and thus the search for ’close’ componentsis easy.
4If they are connected, by definition more than one edge connectthe two groups
![Page 4: Automatic Large Scale Generation of Internet PoP …shavitt/pub/Globecom08.pdf · Automatic Large Scale Generation of Internet PoP Level Maps ... there was criticism [10] ... high](https://reader042.dokumen.tips/reader042/viewer/2022030921/5b793da37f8b9a31308d4d1f/html5/page/4.jpg)
4
Fig. 1. Parent-Child classification: blue nodes - parent pair, rednodes - child, blue and red nodes - both parent and child, gray nodes- not classified
(b) Singleton TreatmentAt the end of the process, the ISP graph has evolved
through the multiple node unifications described aboveinto a graph that is comprised of several multi-nodes(the PoPs) and a larger number of nodes (IP interfaces)that were not assigned to any PoP. Typically, these nodeshave only one or two links connecting them to the rest ofthe graph, and the path from a node to the closest PoP isin most cases one hop and sometimes two. We connecta singleton to the closest PoP, providing the distance (inmiliSec) is shorter than a small threshold.
A. Parent-Child classification
A pair of nodes is marked as parent pair if bothof them points to two or more nodes. We combine allthe parent pair nodes into groups by pairwise unifyingparent pair nodes. For example in Fig. 2, nodes {1,2},{2,5} and {3,4} are defined as parent pairs, and areunited to two parent pair groups {1,2,5} and {3,4}. In asimilar way, two nodes are marked as child pair if bothof them are pointed by at least two nodes, and child pairgroups are defined like wise. Some nodes may belong toboth categories and it is allowable for a node to belongto one parent pair group and to one child pair group.By definition, if a node belongs to two or more groupsof the same kind, these groups are unified. Fig. 1 showsan example of parent/child classification.
B. Localization algorithm
The localization algorithm input is a highly connectedbipartite graph G(V,E) with a weight function W :E → R representing the estimated physical link delay,as shown in Fig. 2. The other input to the algorithmis a partition of the graph to the parent/child groupsas described in section II-A. The localization algorithmchecks whether nodes of the same type (parent/child )
Fig. 2. Bipartite graph example, on the right side dark and brightnodes belongs to different collocation
belong to the same physical collocation. For this task thealgorithm takes advantage of the topological structure ofthe group, for instance if we check the parent group Pwe note that each child node of the group is pointed by atleast two parent nodes. Comparing the delays from thechild pair nodes we can partition nodes of the parentpair group to one or more geographic collocations.
Formally, we represent each member of a group of twoor more nodes (either parent pair or child pair group) ina coordinate space of the nodes that points to them usingthe weight of the edges. Next, we check the distancebetween each pair of nodes in that coordinate space.We assume that the link delay estimation errors [17]are caused mainly by an impulse noise, i.e., most of themeasurements are fairly precise or have only small noise,while a small portion of the measurements may havelarge errors. Therefore, unlike the Gaussian noise case,where Euclidean distance is used as a representation ofthe distance between nodes, we compare the similarityover the coordinates. An example is shown in Fig. 2:nodes 6 and 10 are pointed by nodes 1,2,3, and 5. Takinginto account the delays, one might assume that nodes 1,2,and 3 are at the same location while node 5 is locatedelsewhere. Nevertheless, nodes 9 and 11 imply that node5 is collocated with nodes 1,2, and 3. In addition, usingthe weights we can conclude that the dark nodes (6,7,8)are located on a different location than the bright nodes(9,10,11).
We propose the following deterministic algorithm toclassify the locations of nodes in the bipartite graph. Foreach pair of parent nodes (u, v) ∈ P, u 6= v, we definethe ‘common children’ group, CC by
CC(u, v) ={
w ∈ G|(u, w) ∈ E⋂
(v, w) ∈ E}
(2)
![Page 5: Automatic Large Scale Generation of Internet PoP …shavitt/pub/Globecom08.pdf · Automatic Large Scale Generation of Internet PoP Level Maps ... there was criticism [10] ... high](https://reader042.dokumen.tips/reader042/viewer/2022030921/5b793da37f8b9a31308d4d1f/html5/page/5.jpg)
5
We denote the members of CC(u, v) as{cc1, cc2, . . . , ccm}. Using the weights of the edgesfrom the pair of parent nodes to the ‘common children’,W (u, cci) and W (v, cci), we calculate the ‘Error Ratio’vector, ER:
ER(u, v) =[W (u, cc1)W (v, cc1)
,W (u, cc2)W (v, cc2)
, . . . ,W (u, ccm)W (v, ccm)
]The important property of | log(ER(u, v))| is that for
coordinates with a small relative error the values ofthe elements in ER(u, v) will be rather small, and willincrease with a loss of the accuracy. Therefore compar-ing er(u, v) = median(| log(ER(u, v))|) to a certainthreshold gives a proper indication for the accuracy inthe majority of the measurements.
We use the er values for the parents, to partitionparents group to smaller parent groups which are ge-ographically collocated. For this end, we produce aweighted clique of all the parent nodes in a group,where the weight of the edge (u, v) is er(u, v). Weremove all the links with a weight below a certain smallthreshold. Each connected component in the remaininggraph becomes a parent group for the next step. Tosummarize, we partitioned the parent group to severalparent groups that are geographically co-located.
The same process is repeated for child groups, wherethe error vectors are calculated by the distances to thecommon parents.
This kind of localization helps us to overcome a rela-tively large number of errors. However, if more than halfof the measurements to a certain node are incorrect, thealgorithm may fail to determine its location. Otherwise,there is no impact on the overall performance. Those‘badly’ measured nodes might not became a part of thecorrect PoP, but the PoP map will be formed correctlyin spite of them, i.e., no new PoPs will be created.
III. RESULTS
We have run the algorithm described above for thehundred AS networks with the highest degree (Fig. 3). In17 of them, the algorithm failed to identify even a singlePoP. An examination of their identity revealed that 3were exchange points (LIE, DE-CIX, and AMS-IX) andone was an experimental peering point, all four shouldnot have PoPs; 5 were ASes in East Europe. However, afew of these ASes were networks where DIMES failedto supply a reasonable number of IP level measurements.For example, DIMES measured only 25 IP level links inAS 7911 that belongs to Level 3 Communications andonly 10 of them had more than 10 measurements in the
Fig. 3. The number of PoPs found (Y-axis) for the 100 top degreeASes (X-axis shows the AS degree).
two day sample, hardly enough data for the algorithmto run. The algorithm found more PoPs for high degreeASes, which is a positive sign.
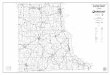
We selected a few networks for a detailed evaluationof the algorithm performance. We report results forBroadwing, a US wide ISP that publishes its networkstructure on the web [18]. Visually, there is a greataffinity of the obtained map (Fig. 4(a)) and the publishednetworks (Fig. 4(b)), note that the published network haslayer 2 nodes that cannot be detected with traceroute.Out of the 8 IP core sites we identified 6 (Hayward,Salt Lake City, Ft. Worth, Atlanta, Washington, and NewYork City) and missed Indianapolis and Seattle, for thelatter we simply did not have measurements passingthrough. From the additional IP edge aggregate sites(Broadwing terminology) we have detected 4. We missedMiami (for which we had just a few measurements),Dallas (which we failed to distinguish from Ft. Worth),failed to distinguish Silicon Valley PoPs from Hayward,and failed to distinguish the smaller New England PoPsfrom NYC and Washington. It is not clear to us if closelylocated and highly interconnected PoPs can be separatedusing an automated algorithm.
All the edges we found (see Fig. 4(a)) were correct,besides two that we believe are layer 2 tunneled connec-tions, thus true from the IP level aspects. To understandthis, we note that in the network shown in Fig. 4(a) thereare two triangles in which the sum of the delays alongtwo edges approximately equals the delay on the thirdedge (nywk → chcg + chcg → cncn ≈ nywk → cncnand dlls → lax + lax → hywr ≈ dlls → hywr). The‘triangle equality’ implies that the long edges do notexist at the physical level, but that the nwyk → cncnlink passes through Chicago in the example above, and
![Page 6: Automatic Large Scale Generation of Internet PoP …shavitt/pub/Globecom08.pdf · Automatic Large Scale Generation of Internet PoP Level Maps ... there was criticism [10] ... high](https://reader042.dokumen.tips/reader042/viewer/2022030921/5b793da37f8b9a31308d4d1f/html5/page/6.jpg)
6
(a) Broadwing network PoP level representation from twodays measurements in August 2006.
© 2005, ®™Broadwing Communications, LLC
Approved for general use. Information subject to change without notice.Comprehensive Network
BRW Planned
BRW Network Route
BRW POP
DSL Access
Ethernet Access
Media Presence
Media Partner
LEGEND
IP Core SiteJuniper & Cisco Routers
IP Edge SiteCisco Router
IP Edge/Aggregate SiteJuniper & Cisco Routers
Public IP Peering Site
Private IP Peering Site
Public/Private IP Peering Site
Voice Switch - DMS 250
Voice Switch - DMS 500
Frame Relay/ATMAlcatel 7470
Frame Relay/ATMAlcatel 7470 & 7670
Voice Network Operations Center
Portland
Boise
Sacramento
Hayward
San JoseFresno
Bakersfield
San Diego
Las Vegas
Marketplace
Phoenix
Tucson
Salt LakeCity
Denver
ColoradoSprings
Amarillo
Lubbock
Dallas
Waco
AustinHouston
CorpusChristi
McAllen
Harlingen
Midland
Abilene
Oklahoma City
Kansas City
St. Louis
Indianapolis
Milwaukee
Madison
Minneapolis
Baton Rouge
Miami
Greensboro
Raleigh
Washington DC
Newark DE
Newark NJStamfordNew Haven
Providence
Albany
Syracuse
RochesterBuffalo
Birmingham
Richmond
Joplin
Cincinnati
DaytonColumbus
Akron
New Orleans
Detroit
Pontiac
Midland
Kalamazoo
Grand Rapids
Ann ArborJackson
FlintSaginaw
Bay City
Birmingham
Toledo
Battle Creek
El Paso
Cheyenne
Lansing
SouthBend
Cleveland
Hudson
TallahasseeJacksonville
OrlandoTampa
San Antonio
Fort Worth
Nashville
Albuquerque Memphis
White Plains
HartfordPoughkeepsie
New YorkLaramie
Rock Springs
Mountain View
Trenton
Louisville
Shreveport
Aurora
Pittsburgh
TulsaCharlotte
Jackson
College Park
Santa Barbara
Norfolk
Harrisburg
Miami
Baltimore
N. New Jersey
Philadelphia
Boston
Chicago
Atlanta
Dayton
Seattle
SanFrancisco
Los Angeles
Orange County
Palmdale
(b) Published Broadwing network.
Fig. 4. Broadwing network, the PoP detection algorithm result anddata provided by the operator on its web site. [18]
the dlls → hywr link passes through L.A.. This maybe an important finding for network redundancy andsurvivability analysis.
Another validation we conducted was to compare ournodes’ PoP partition with their DNS aliases and theirgeo-IP location. The comparisons table for Broadwingnetwork as well as other networks are very large andcan be found in the appendices of [11]. The results thereclearly show that our method is superior to usage ofeither DNS aliases or geo-IP databases.
IV. SUMMARY
We presented an efficient algorithm for building anInternet wide PoP level map from raw traceroute mea-surements with no additional input. While our algorithmrequires a highly distributed measurement infrastructurelike DIMES, its execution is efficient and thus canbe made on a weekly basis for tracking the Internetevolution and for distance estimation. In the future, weenvision the algorithm to be able to direct DIMES tomeasure areas where there is lack of data, or to design
an entire experiment that will efficiently construct suchmaps.
REFERENCES
[1] M. Faloutsos, P. Faloutsos, and C. Faloutsos, “On power-lawrelationships of the internet topology,” in ACM SIGCOMM1999, Boston, MA, USA, Aug./Sep. 1999.
[2] Q. Chen, H. Chang, R. Govindan, S. Jamin, S. Shenker, andW. Willinger, “The origin of power-laws in internet topologiesrevisited,” in IEEE Infocom 2002, New-York, NY, USA, Apr.2002.
[3] A. Medina, I. Matta, and J. Byers, “On the origin of powerlaws in internet topologies,” ACM Computer CommunicationsReview, vol. 30, no. 2, pp. 18–28, 2000.
[4] A.-L. Barabasi and R. Albert, “Emergence of scaling in randomnetworks,” SCIENCE, vol. 286, pp. 509 – 512, 15 Oct. 1999.
[5] H. Chang, S. Jamin, and W. Willinger, “Internet connectivityat the as-level: An optimization-driven modeling approach,”in ACM SIGCOMM Workshop on Models, Methods and Toolsfor Reproducible Network Research, Karlsruhe, Germany, Aug.2003.
[6] S. Bar, M. Gonen, and A. Wool, “An incremental super-linearpreferential internet topology model,” in PAM ’04, AntibesJuan-les-Pins, France, Apr. 2004.
[7] S.-H. Yook, H. Jeong, and A.-L. Barabasi, “Modeling the inter-net’s large-scale topology,” Proceedings of the Nat’l Academyof Sciences USA, vol. 99, pp. 13 382–13 386, 2002.
[8] A. Lakhina, J. W. Byers, M. Crovella, and I. Matta, “On thegeographic location of internet resources,” IEEE Journal onSelected Areas in Communications, vol. 21, no. 6, pp. 934 –948, Aug. 2003.
[9] N. Spring, R. Mahajan, and D. Wetherall, “Measuring ISPtopologies with rocketfuel,” in ACM SIGCOMM ’02, Pittsburgh,PA, USA, Aug. 2002.
[10] M. Zhang, Y. Ruan, V. S. Pai, and J. Rexford, “How DNSmisnaming distorts internet topology mapping,” in Proceedingsof the 2006 Usenix Annual Technical Conference, Boston, MA,USA, Jun. 2006.
[11] D. Feldman, “Automatic construction of PoP level internetdistance maps,” School of Electrical Engineering, Tel AvivUniversity, Israel, 2008.
[12] Y. Shavitt and E. Shir, “DIMES: Let the internet measure itself.”in ACM SIGCOMM Computer Communication Review, vol. 35,Oct. 2005, pp. 71–74.
[13] “DIMES, Distributed Internet MEasurement System,”http://www.netdimes.org/.
[14] G. Huston, ISP survival guide: strategies for running a com-petitive ISP. John Wiley & Sons, Inc., 1999.
[15] R. Milo, S. Shen-Orr, S. Itzkovitz, N. Kashtan, D. Chklovskii,and U. Alon, “Network motifs: simple building blocks ofcomplex networks.” Science, vol. 298, no. 5594, pp. 824–827,Oct. 2002.
[16] “Mfinder - network motifs detection tools,”http://www.weizmann.ac.il/mcb/UriAlon/.
[17] D. Feldman and Y. Shavitt, “An optimal median calculationalgorithm for estimating internet link delays from active mea-surements,” in End to end monitoring workshop (E2EMON),Munich, Germany, May 2007.
[18] “Broadwing network map,” http://www.broadwing.com/about-b4.html.