Embed Size (px)
Citation preview

Attractor neural networks
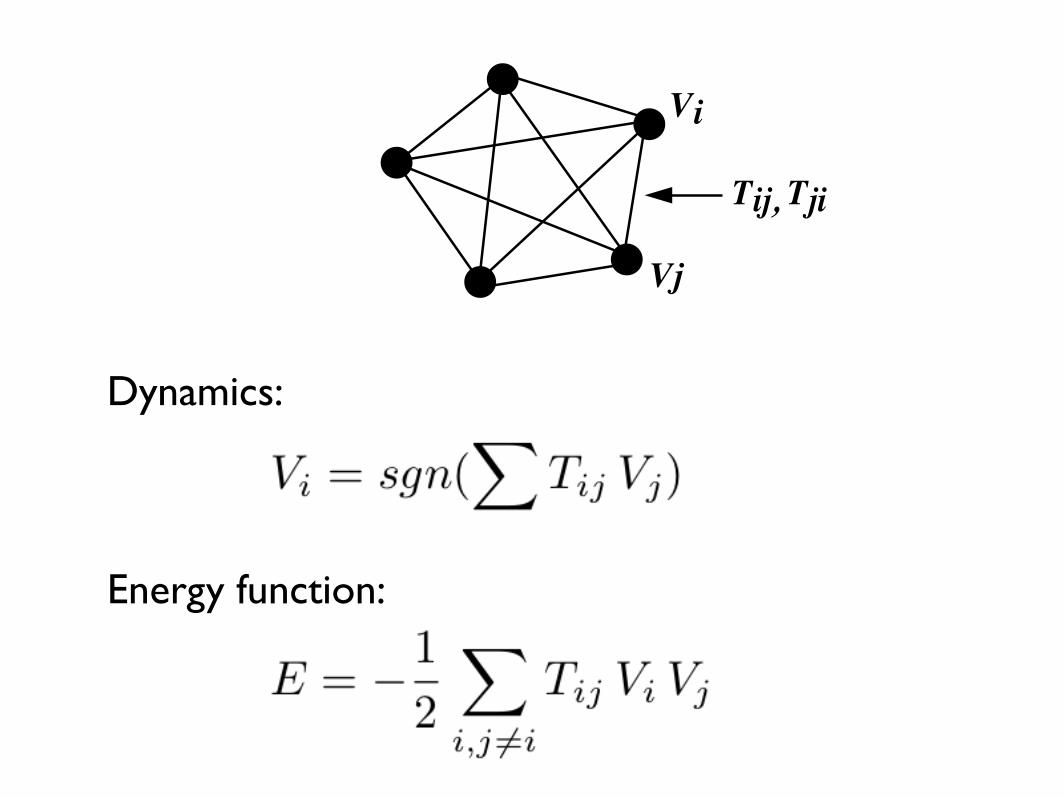
Vi
Vj
Tij, Tji
Dynamics:
Energy function:
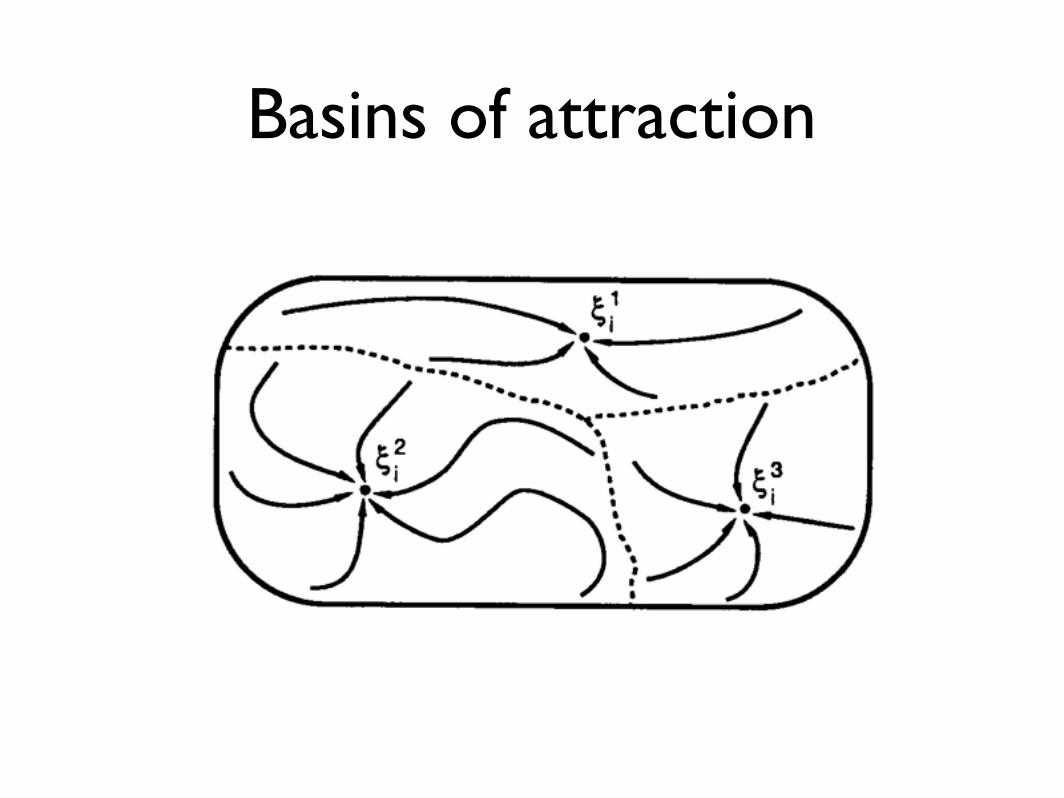
Basins of attraction

input recall

Outer-product rule
or
Thus

Capacity vs. error rate
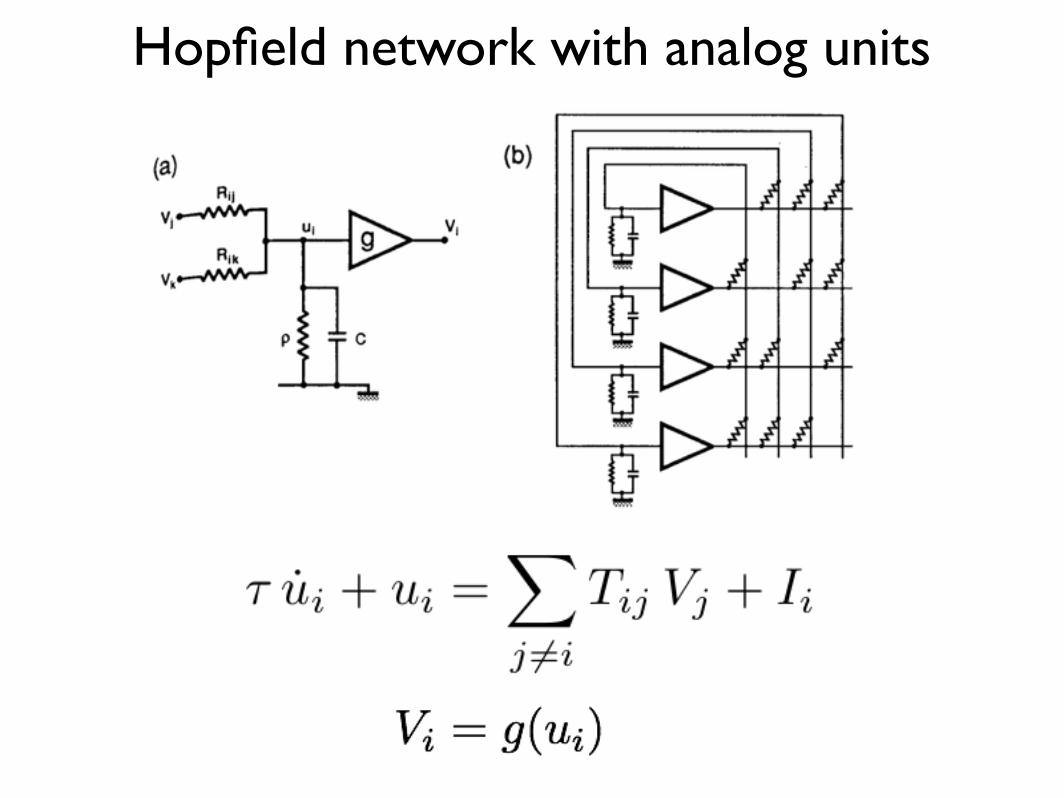
Hopfield network with analog units
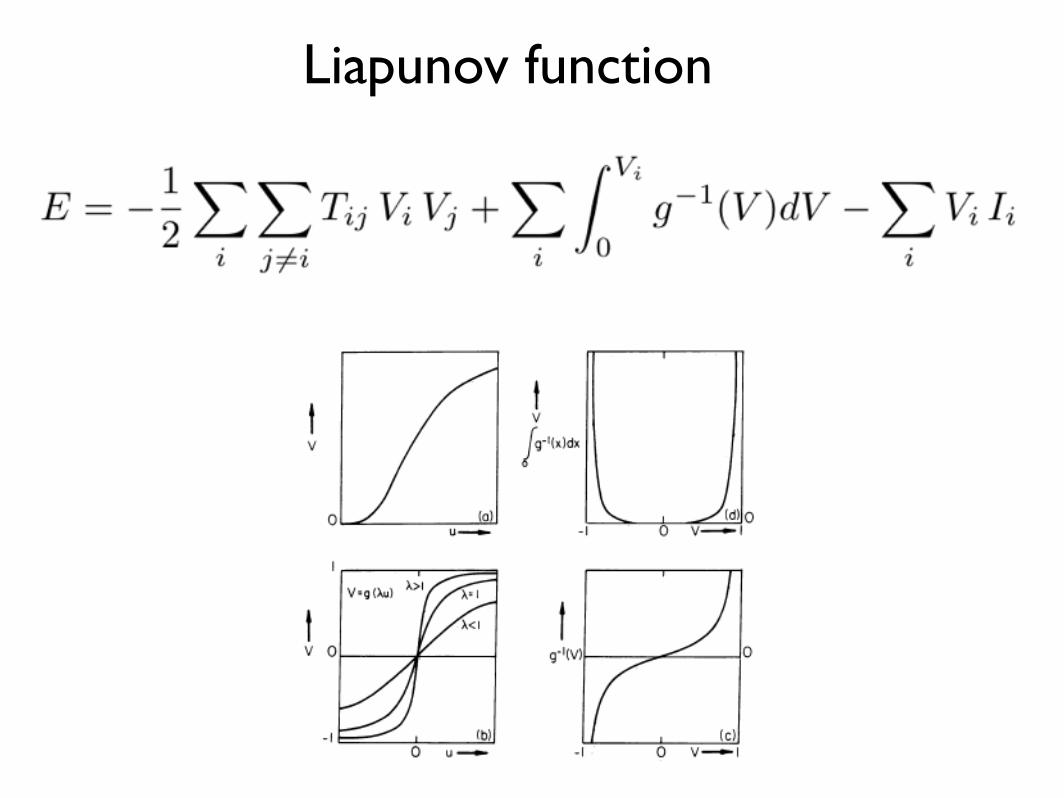
Liapunov function

From Liapunov function to dynamics
Thus
Let u̇i ∝ −
∂E
∂Vi
=!
j ̸=i
Tij Vj + Ii − ui
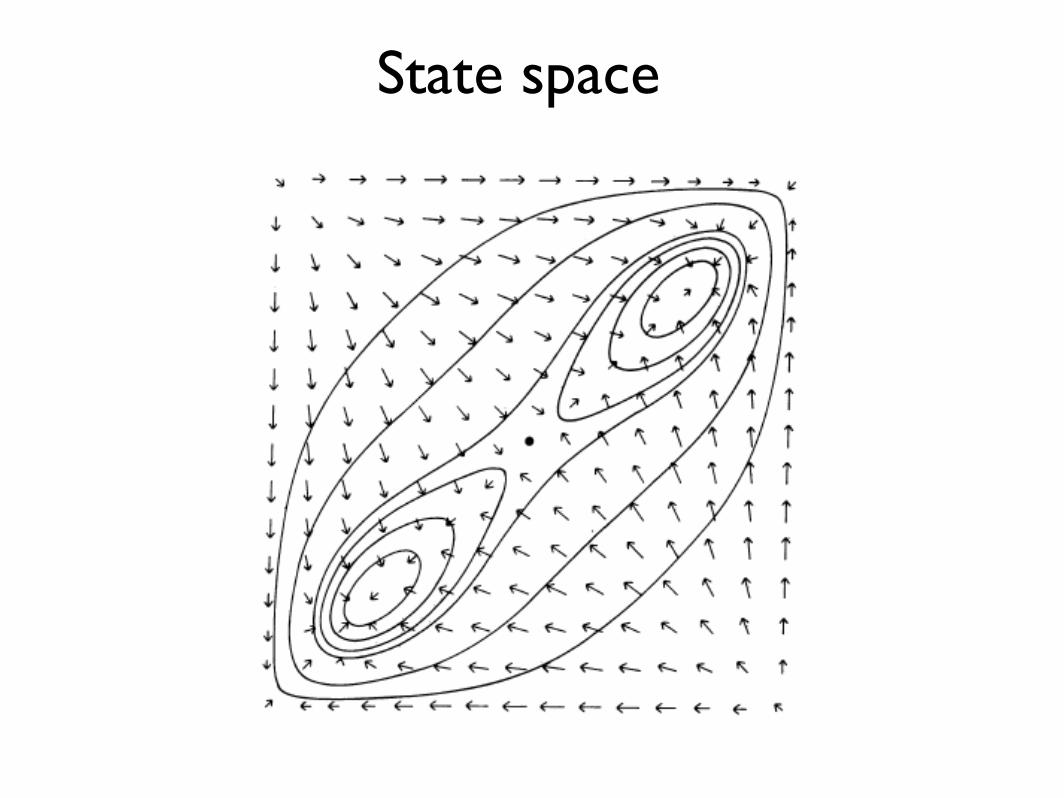
State space
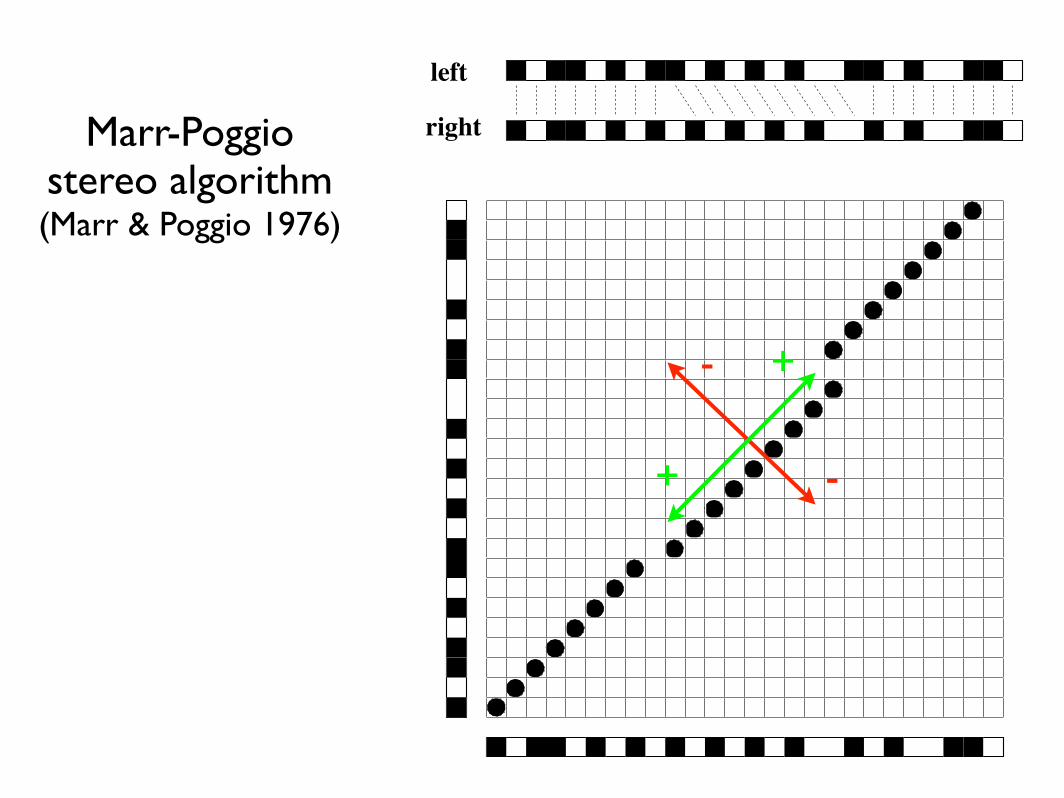
Marr-Poggio stereo algorithm(Marr & Poggio 1976)
left
right
+
+
-
-

‘Bump circuits’ and ring attractors(Zhang, Sompolinsky, Seung and others)
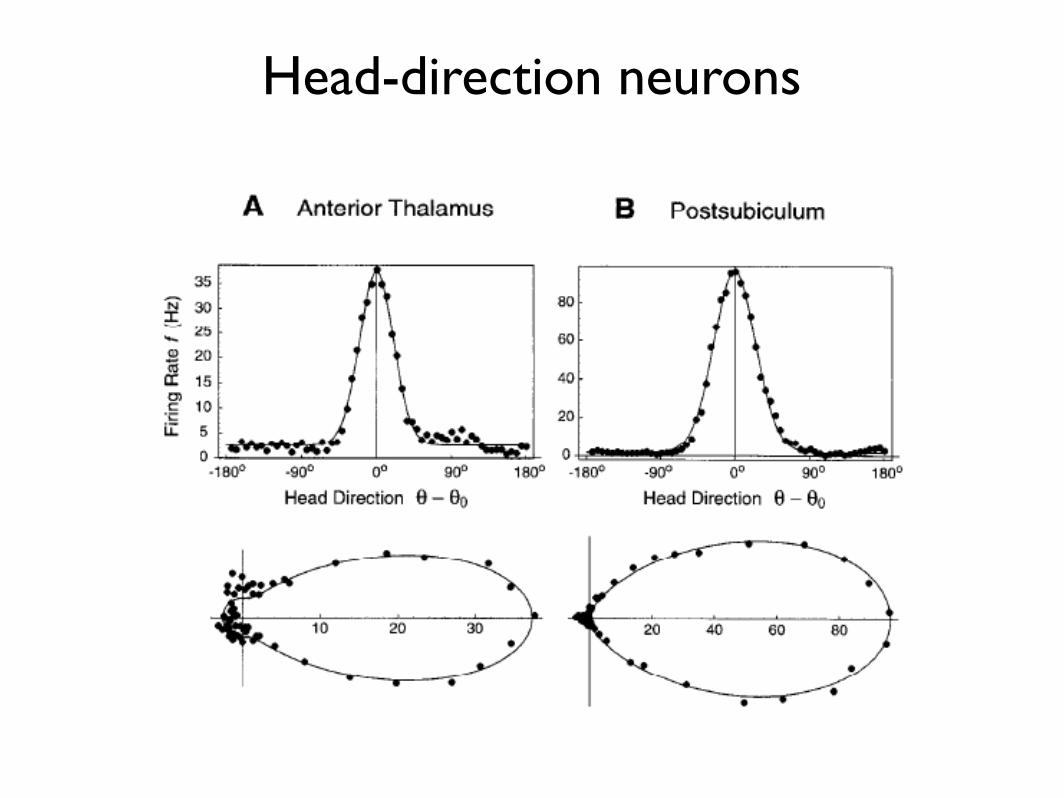
Head-direction neurons
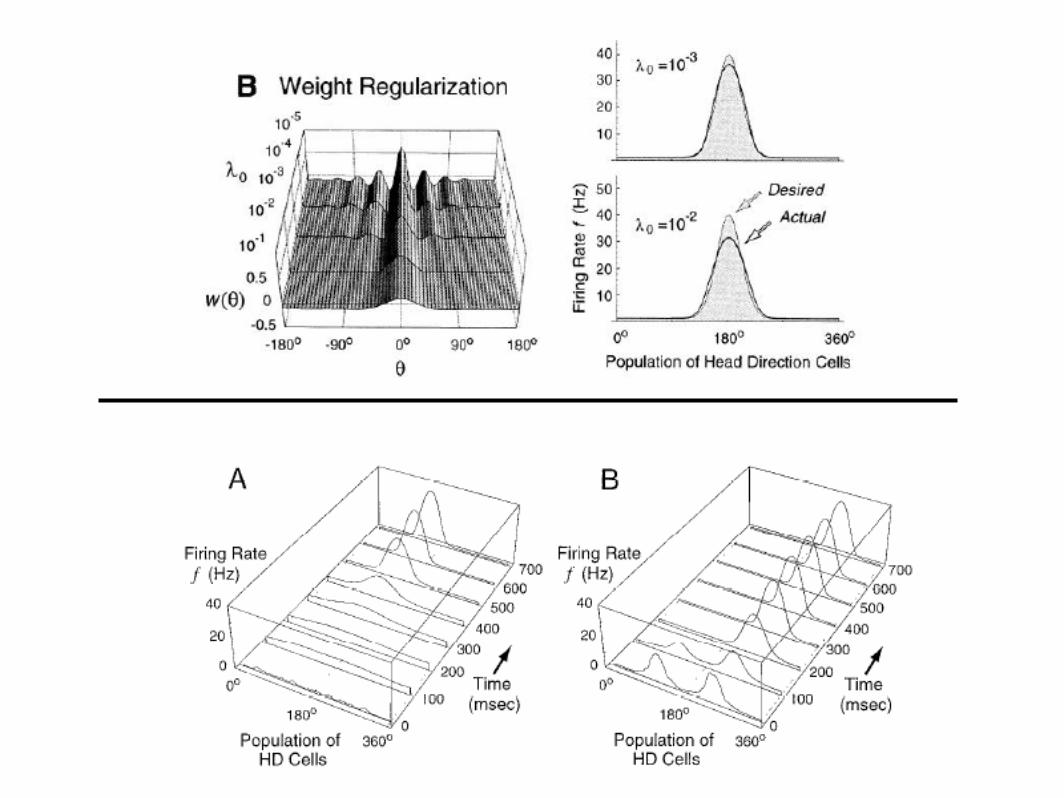
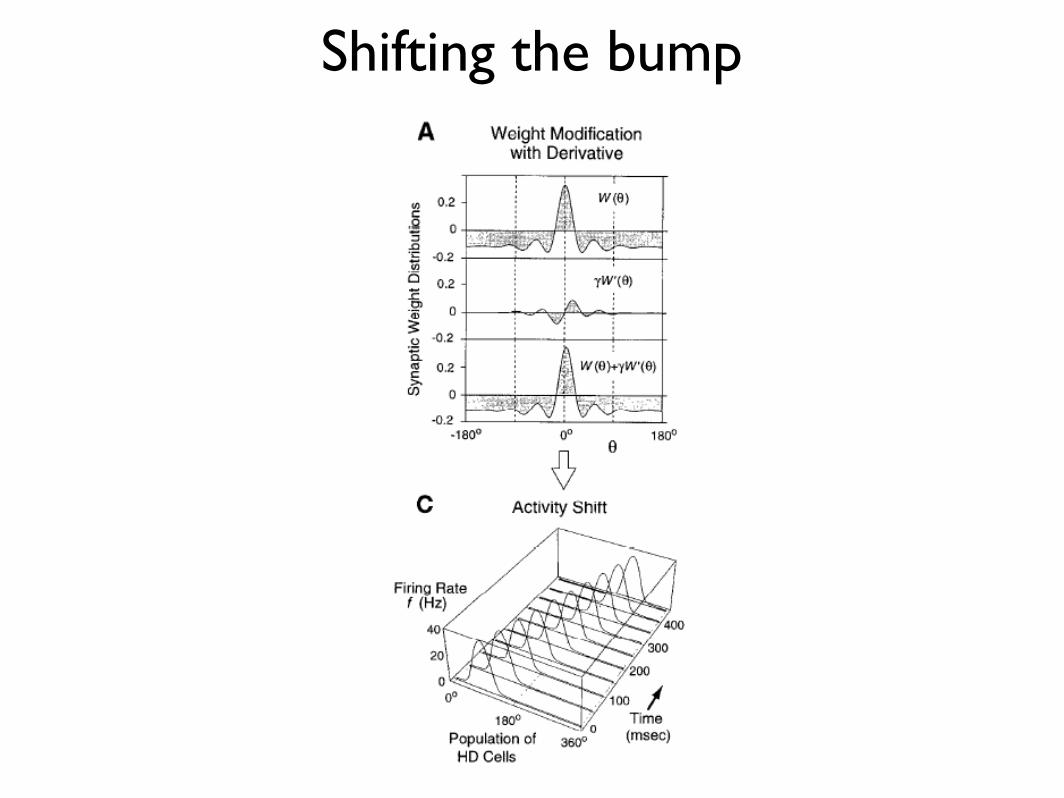
Shifting the bump

2D bumps

Three-way connections
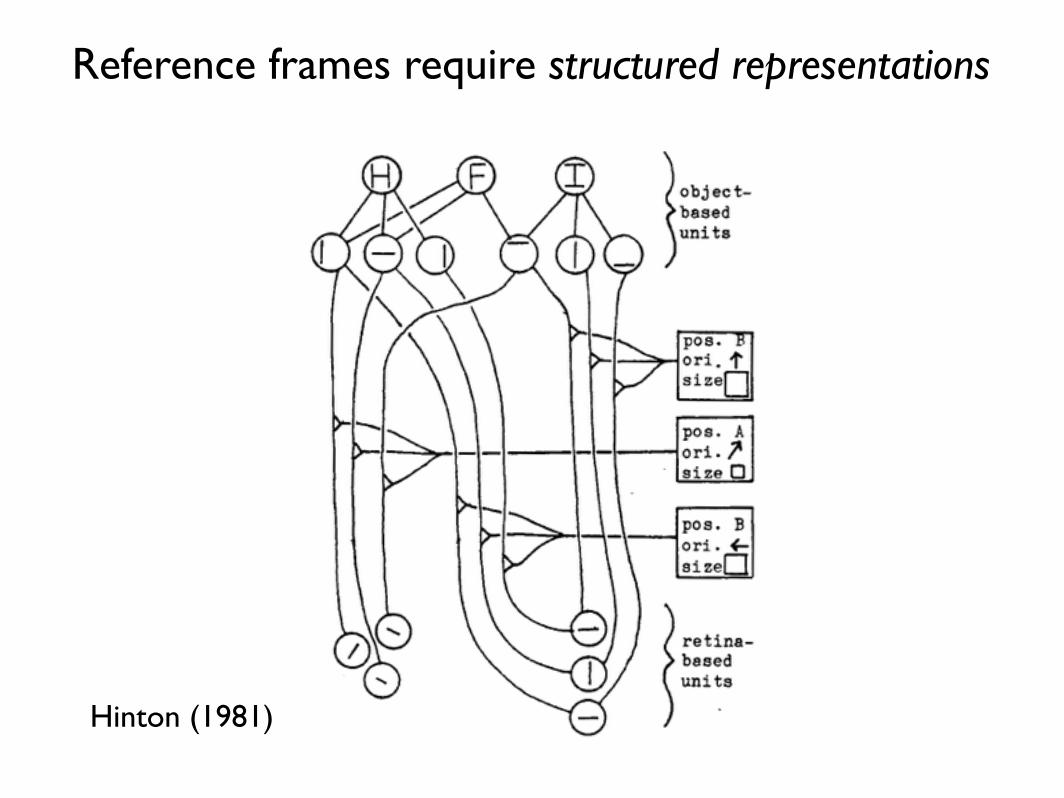
Reference frames require structured representations
Hinton (1981)

Which way are the triangles pointing?
From Attneave
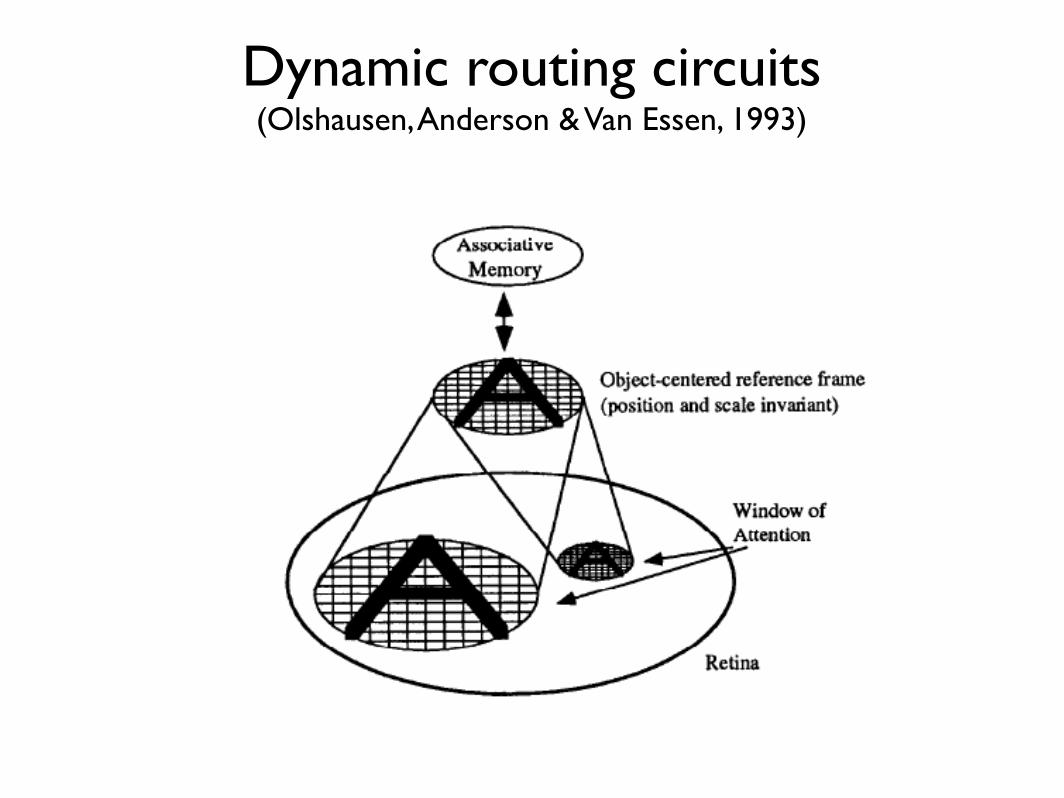
Dynamic routing circuits(Olshausen, Anderson & Van Essen, 1993)

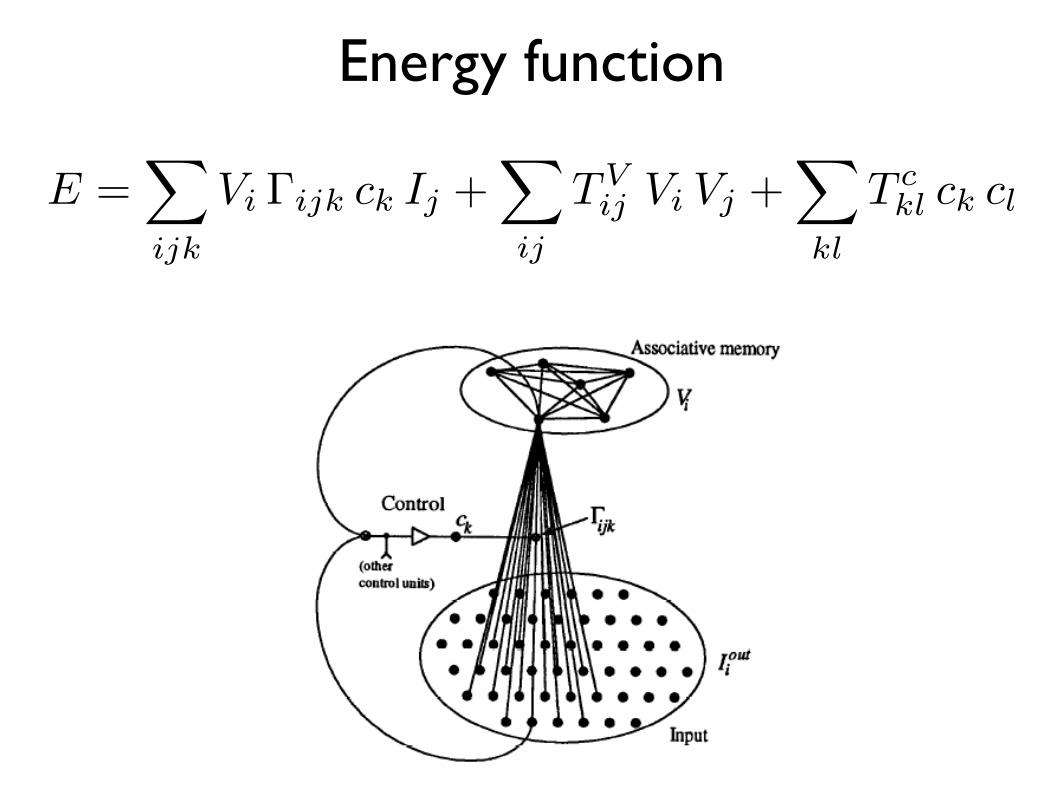
Energy function
E =X
ijk
Vi �ijk ck Ij +X
ij
TVij Vi Vj +
X
kl
T ckl ck cl
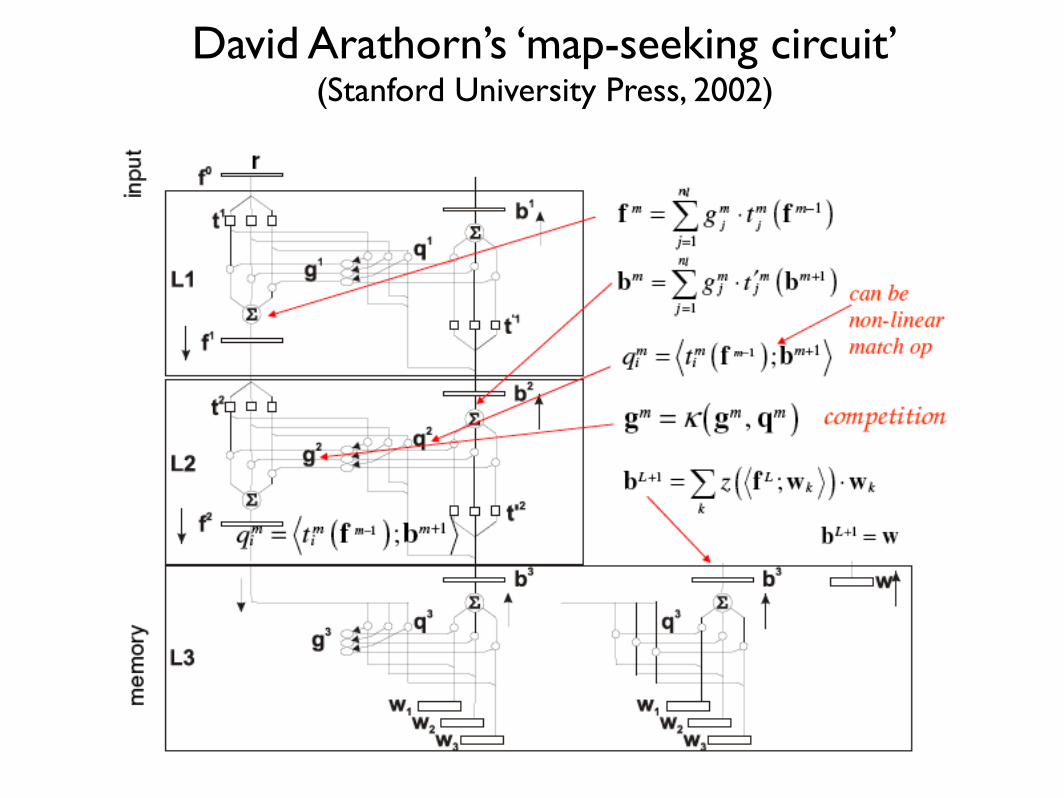
David Arathorn’s ‘map-seeking circuit’(Stanford University Press, 2002)

Recurrent networks for sequence learning
Harnessing Nonlinearity: PredictingChaotic Systems and Saving Energyin Wireless Communication
Herbert Jaeger* and Harald Haas
We present a method for learning nonlinear systems, echo state networks(ESNs). ESNs employ artificial recurrent neural networks in a way that hasrecently been proposed independently as a learning mechanism in biologicalbrains. The learning method is computationally efficient and easy to use. Ona benchmark task of predicting a chaotic time series, accuracy is improved bya factor of 2400 over previous techniques. The potential for engineering ap-plications is illustrated by equalizing a communication channel, where the signalerror rate is improved by two orders of magnitude.
Nonlinear dynamical systems abound in thesciences and in engineering. If one wishes tosimulate, predict, filter, classify, or control sucha system, one needs an executable system mod-el. However, it is often infeasible to obtainanalytical models. In such cases, one has toresort to black-box models, which ignore theinternal physical mechanisms and instead re-produce only the outwardly observable input-output behavior of the target system.
If the target system is linear, efficientmethods for black-box modeling are avail-able. Most technical systems, however, be-come nonlinear if operated at higher opera-tional points (that is, closer to saturation).Although this might lead to cheaper and moreenergy-efficient designs, it is not done be-cause the resulting nonlinearities cannot beharnessed. Many biomechanical systems usetheir full dynamic range (up to saturation)and thereby become lightweight, energy effi-cient, and thoroughly nonlinear.
Here, we present an approach to learn-ing black-box models of nonlinear systems,echo state networks (ESNs). An ESN is anartificial recurrent neural network (RNN).RNNs are characterized by feedback (“re-current”) loops in their synaptic connectionpathways. They can maintain an ongoingactivation even in the absence of input andthus exhibit dynamic memory. Biologicalneural networks are typically recurrent.Like biological neural networks, an artifi-cial RNN can learn to mimic a targetsystem—in principle, with arbitrary accu-racy (1). Several learning algorithms areknown (2!4) that incrementally adapt thesynaptic weights of an RNN in order totune it toward the target system. Thesealgorithms have not been widely employedin technical applications because of slow
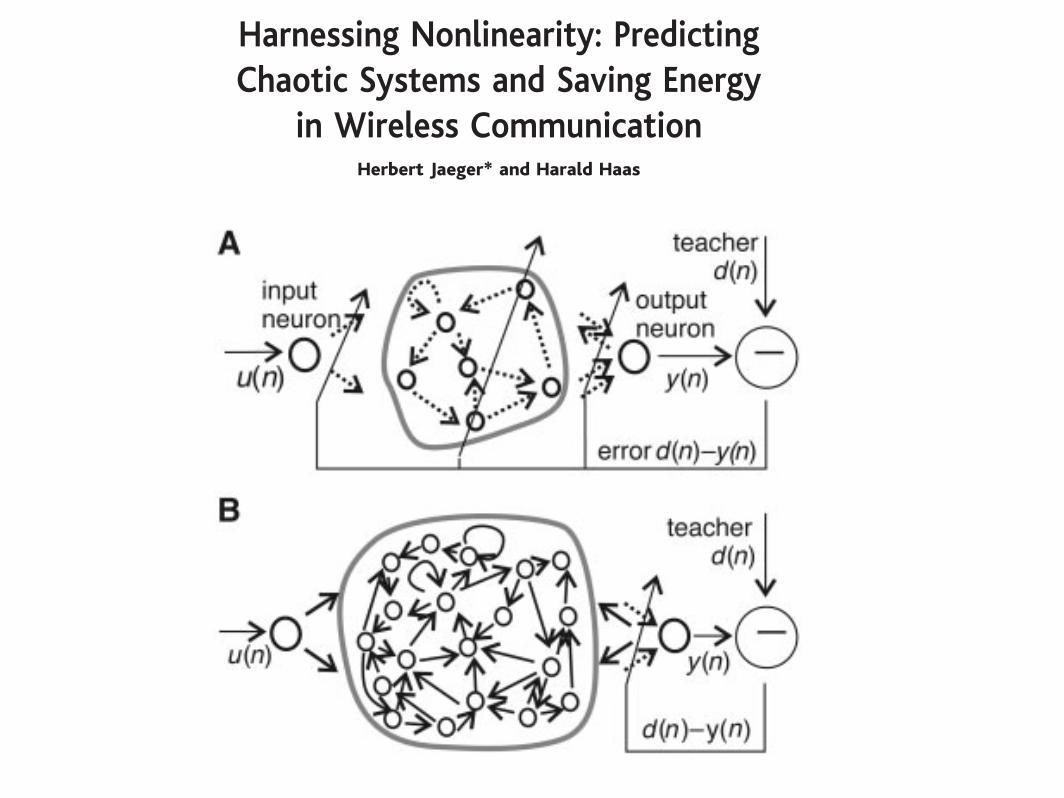
convergence and suboptimal solutions (5,6). The ESN approach differs from thesemethods in that a large RNN is used (on theorder of 50 to 1000 neurons; previous tech-niques typically use 5 to 30 neurons) and inthat only the synaptic connections from theRNN to the output readout neurons aremodified by learning; previous techniquestune all synaptic connections (Fig. 1). Be-cause there are no cyclic dependencies be-tween the trained readout connections,training an ESN becomes a simple linearregression task.
We illustrate the ESN approach on atask of chaotic time series prediction (Fig.2) (7). The Mackey-Glass system (MGS)(8) is a standard benchmark system for timeseries prediction studies. It generates a sub-tly irregular time series (Fig. 2A). Theprediction task has two steps: (i) using aninitial teacher sequence generated by theoriginal MGS to learn a black-box model Mof the generating system, and (ii) using Mto predict the value of the sequence somesteps ahead.
First, we created a random RNN with1000 neurons (called the “reservoir”) and oneoutput neuron. The output neuron wasequipped with random connections thatproject back into the reservoir (Fig. 2B). A3000-step teacher sequence d(1), . . .,d(3000) was generated from the MGS equa-tion and fed into the output neuron. Thisexcited the internal neurons through the out-put feedback connections. After an initialtransient period, they started to exhibit sys-tematic individual variations of the teachersequence (Fig. 2B).
The fact that the internal neurons displaysystematic variants of the exciting externalsignal is constitutional for ESNs: The internalneurons must work as “echo functions” forthe driving signal. Not every randomly gen-erated RNN has this property, but it caneffectively be built into a reservoir (support-ing online text).
It is important that the echo signals berichly varied. This was ensured by a sparseinterconnectivity of 1% within the reservoir.This condition lets the reservoir decomposeinto many loosely coupled subsystems, estab-lishing a richly structured reservoir of excit-able dynamics.
After time n " 3000, output connectionweights wi (i " 1, . . . , 1000) were computed(dashed arrows in Fig. 2B) from the last 2000steps n " 1001, . . . , 3000 of the training runsuch that the training error
MSEtrain"1/2000!n"1001
3000 "d(n)!!i ! 1
1000
w i xi(n)#2
was minimized [xi(n), activation of the ithinternal neuron at time n]. This is a simplelinear regression.
With the new wi in place, the ESN wasdisconnected from the teacher after step 3000and left running freely. A bidirectional dy-namical interplay of the network-generatedoutput signal with the internal signals xi(n)unfolded. The output signal y(n) was createdfrom the internal neuron activation signalsxi(n) through the trained connections wi, by
y(n)"#i"1
1000wixi$n). Conversely, the internal
signals were echoed from that output signalthrough the fixed output feedback connec-tions (supporting online text).
For testing, an 84-step continuationd(3001), . . . , d(3084) of the original signalwas computed for reference. The networkoutput y(3084) was compared with the cor-rect continuation d(3084). Averaged over 100independent trials, a normalized root meansquare error
NRMSE " "!j"1
100
(dj(3084) ! yj$3084))2/100%2/2
'10!4.2
was obtained (dj and yj teacher and network
International University Bremen, Bremen D-28759,Germany.
*To whom correspondence should be addressed. E-mail: [email protected]
Fig. 1. (A) Schema of previous approaches toRNN learning. (B) Schema of ESN approach.Solid bold arrows, fixed synaptic connections;dotted arrows, adjustable connections. Bothapproaches aim at minimizing the error d(n) –y(n), where y(n) is the network output and d(n)is the teacher time series observed from thetarget system.
R E P O R T S
2 APRIL 2004 VOL 304 SCIENCE www.sciencemag.org78
Harnessing Nonlinearity: PredictingChaotic Systems and Saving Energyin Wireless Communication
Herbert Jaeger* and Harald Haas
We present a method for learning nonlinear systems, echo state networks(ESNs). ESNs employ artificial recurrent neural networks in a way that hasrecently been proposed independently as a learning mechanism in biologicalbrains. The learning method is computationally efficient and easy to use. Ona benchmark task of predicting a chaotic time series, accuracy is improved bya factor of 2400 over previous techniques. The potential for engineering ap-plications is illustrated by equalizing a communication channel, where the signalerror rate is improved by two orders of magnitude.
Nonlinear dynamical systems abound in thesciences and in engineering. If one wishes tosimulate, predict, filter, classify, or control sucha system, one needs an executable system mod-el. However, it is often infeasible to obtainanalytical models. In such cases, one has toresort to black-box models, which ignore theinternal physical mechanisms and instead re-produce only the outwardly observable input-output behavior of the target system.
If the target system is linear, efficientmethods for black-box modeling are avail-able. Most technical systems, however, be-come nonlinear if operated at higher opera-tional points (that is, closer to saturation).Although this might lead to cheaper and moreenergy-efficient designs, it is not done be-cause the resulting nonlinearities cannot beharnessed. Many biomechanical systems usetheir full dynamic range (up to saturation)and thereby become lightweight, energy effi-cient, and thoroughly nonlinear.
Here, we present an approach to learn-ing black-box models of nonlinear systems,echo state networks (ESNs). An ESN is anartificial recurrent neural network (RNN).RNNs are characterized by feedback (“re-current”) loops in their synaptic connectionpathways. They can maintain an ongoingactivation even in the absence of input andthus exhibit dynamic memory. Biologicalneural networks are typically recurrent.Like biological neural networks, an artifi-cial RNN can learn to mimic a targetsystem—in principle, with arbitrary accu-racy (1). Several learning algorithms areknown (2!4) that incrementally adapt thesynaptic weights of an RNN in order totune it toward the target system. Thesealgorithms have not been widely employedin technical applications because of slow
convergence and suboptimal solutions (5,6). The ESN approach differs from thesemethods in that a large RNN is used (on theorder of 50 to 1000 neurons; previous tech-niques typically use 5 to 30 neurons) and inthat only the synaptic connections from theRNN to the output readout neurons aremodified by learning; previous techniquestune all synaptic connections (Fig. 1). Be-cause there are no cyclic dependencies be-tween the trained readout connections,training an ESN becomes a simple linearregression task.
We illustrate the ESN approach on atask of chaotic time series prediction (Fig.2) (7). The Mackey-Glass system (MGS)(8) is a standard benchmark system for timeseries prediction studies. It generates a sub-tly irregular time series (Fig. 2A). Theprediction task has two steps: (i) using aninitial teacher sequence generated by theoriginal MGS to learn a black-box model Mof the generating system, and (ii) using Mto predict the value of the sequence somesteps ahead.
First, we created a random RNN with1000 neurons (called the “reservoir”) and oneoutput neuron. The output neuron wasequipped with random connections thatproject back into the reservoir (Fig. 2B). A3000-step teacher sequence d(1), . . .,d(3000) was generated from the MGS equa-tion and fed into the output neuron. Thisexcited the internal neurons through the out-put feedback connections. After an initialtransient period, they started to exhibit sys-tematic individual variations of the teachersequence (Fig. 2B).
The fact that the internal neurons displaysystematic variants of the exciting externalsignal is constitutional for ESNs: The internalneurons must work as “echo functions” forthe driving signal. Not every randomly gen-erated RNN has this property, but it caneffectively be built into a reservoir (support-ing online text).
It is important that the echo signals berichly varied. This was ensured by a sparseinterconnectivity of 1% within the reservoir.This condition lets the reservoir decomposeinto many loosely coupled subsystems, estab-lishing a richly structured reservoir of excit-able dynamics.
After time n " 3000, output connectionweights wi (i " 1, . . . , 1000) were computed(dashed arrows in Fig. 2B) from the last 2000steps n " 1001, . . . , 3000 of the training runsuch that the training error
MSEtrain"1/2000!n"1001
3000 "d(n)!!i ! 1
1000
w i xi(n)#2
was minimized [xi(n), activation of the ithinternal neuron at time n]. This is a simplelinear regression.
With the new wi in place, the ESN wasdisconnected from the teacher after step 3000and left running freely. A bidirectional dy-namical interplay of the network-generatedoutput signal with the internal signals xi(n)unfolded. The output signal y(n) was createdfrom the internal neuron activation signalsxi(n) through the trained connections wi, by
y(n)"#i"1
1000wixi$n). Conversely, the internal
signals were echoed from that output signalthrough the fixed output feedback connec-tions (supporting online text).
For testing, an 84-step continuationd(3001), . . . , d(3084) of the original signalwas computed for reference. The networkoutput y(3084) was compared with the cor-rect continuation d(3084). Averaged over 100independent trials, a normalized root meansquare error
NRMSE " "!j"1
100
(dj(3084) ! yj$3084))2/100%2/2
'10!4.2
was obtained (dj and yj teacher and network
International University Bremen, Bremen D-28759,Germany.
*To whom correspondence should be addressed. E-mail: [email protected]
Fig. 1. (A) Schema of previous approaches toRNN learning. (B) Schema of ESN approach.Solid bold arrows, fixed synaptic connections;dotted arrows, adjustable connections. Bothapproaches aim at minimizing the error d(n) –y(n), where y(n) is the network output and d(n)is the teacher time series observed from thetarget system.
R E P O R T S
2 APRIL 2004 VOL 304 SCIENCE www.sciencemag.org78





























