Embed Size (px)
Citation preview

ARM for Wireless Applications
ARM11 Microarchitecture
On the ARMv6
Connie Wang

Advanced RISC Machines
• >75% of market for 32-bit RISC microprocessors
• ARM11 Design led by Ian Devereux

Demands of Wireless Applications
• High performance
• Low power
• Small size
• Cost

RISC for Wireless
• Strengths:– Clock rate
– Pipelining
• Weaknesses:– High code density
– Power consumption

ARM11 for Wireless
• Strengths Enhanced:– Clock rate
• Optimized interrupt and exception handling
• Minimized context switch cost
• Instruction set for media
– Pipelining• Decoupled for high
bandwidth• Retire before execution
• Weaknesses Reduced:– High code density
• ISA extensions
• Optional application specific and/or VFP coprocessors
– Power consumption• Architecture and
instructions reduce clock rate
• Clock gate control

ARM11 Microarchitecture
• First implementation of ARMv6 architecture• 8-stage pipeline• 64-bit datapaths• Frequency: up to 750 MHz, 350 – 500+ MHz
worst case. 400 – 1,200 Dhrystone MIPS• Power: 0.4 mW/MHz worst case: 0.13µm 1.2V• Will be released to licensees in Q4 2002

ARMv6
• Media support: SIMD extensions
• Improved interrupt latency
• ISA extensions THUMB, DSP, Jazelle
• 100% backwards compatibility to ARMv5

THUMB Instruction Set
• 32-bit performance for 16-bit systems• 32-bit instructions re-coded to 16-bit op-
codes• 32-bit ROM stores 2 THUMB instructions
per word• Decompressed in pipeline to ARM
instruction equivalents• Improves code density by 35%

DSP Instruction Set
• Application accelerator for Digital Signal Processor performance
• Can load/store registers by pairs
• 16x16 or 32x16 MAC in one cycle
• Utilized in MAC pipeline

Jazelle Instruction Set
• Support for entering/exiting Java applications
• Fetches/decodes Java bytecodes, maintains a Java operand stack
• Creates a state that imitates a Java processor
• OS controls low-cost switch between Java and ARM/THUMB states

SIMD Instruction Set
• Parallel processing of 2x16-bit or 4x8-bit operands
• Four new Greater than or Equal to status bits (GE[3:0]) for MAC calculations
• Eliminates need for very high clock frequencies and hardware accelerators
• 2 – 4 x performance improvement for multimedia applications

Synchronization and Sharing Data
• Load-/store- Exclusive instructions (LDREX/STREX) support semaphores– Consolidates old Swap instruction and
necessary semaphore implementation
• Virtual Memory System Architecture v6 ID’s separate caches– Cache hierarchy and ordering rules

Bit/Byte Order Support
• E-bit for current endian setting of core– Set/cleared with SETEND instruction
• REV* instructions reverse bytes for unaligned data support– REV – reverses a word– REV16 – reverses both halfwords– REVSH – reverses high order halfword + sign
extend halfword

Exception and Interrupt Improvement
• Imperative for real-time tasks wherein low latency is critical
• F1 bit in CP15 register 1 designates: 0: Max performance mode, or1: Low interrupt latency mode to allow interrupts
• VE bit enables vectored interrupts to core– Direct vs. external-> system -> vector address
• A-bit aborts all unaligned accesses• U-bit (with clear A-bit) allows unaligned hardware
access

Mode Changing and Stack Improvements
• CPSID/CPSIE instructions allow changing between modes with interrupt disable/enable
• Save Return State (SRS) saves registers and state of current mode onto stack of target mode
• Return From Exception (RFE) loads registers and state of saved mode
• Reduces exception handling overhead

8-Stage Pipeline
• Single-issue• Dynamic branch prediction is 64-entry directly
mapped BTB• 64-bit data paths: read 2 registers in 1 clock• Loads/stores done in background• Out-of-order completion: can retire instructions
before execution• ALU processed in parallel with data cache access• MAC processed in lock-step with ALU
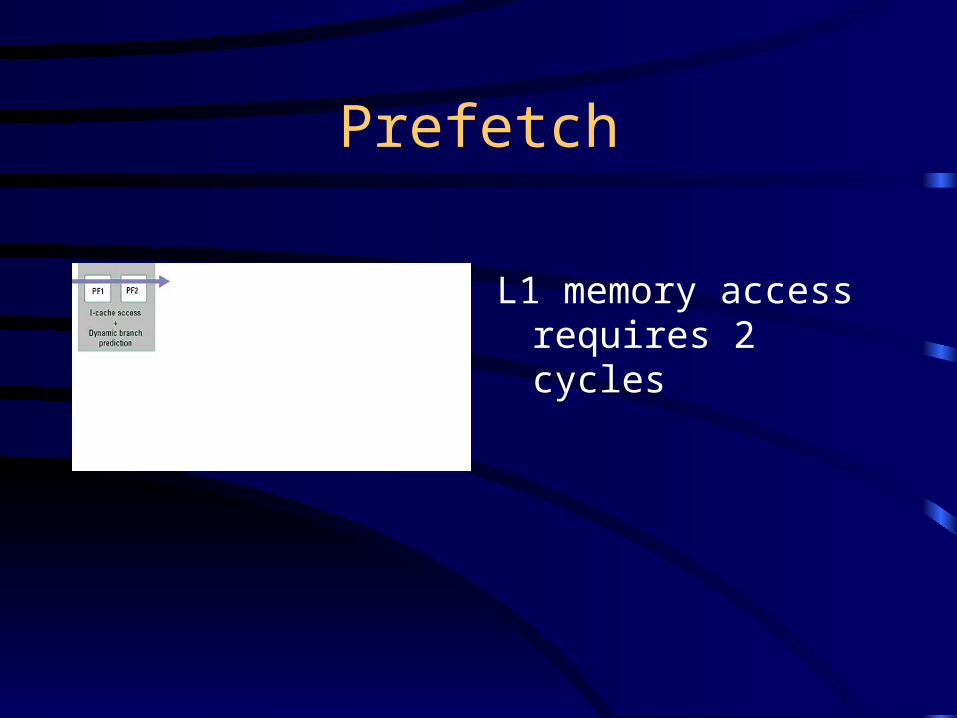
Prefetch
L1 memory access requires 2 cycles

Decode
Decode instruction bits and allocate stack

Issue Instruction
Load operands from registers
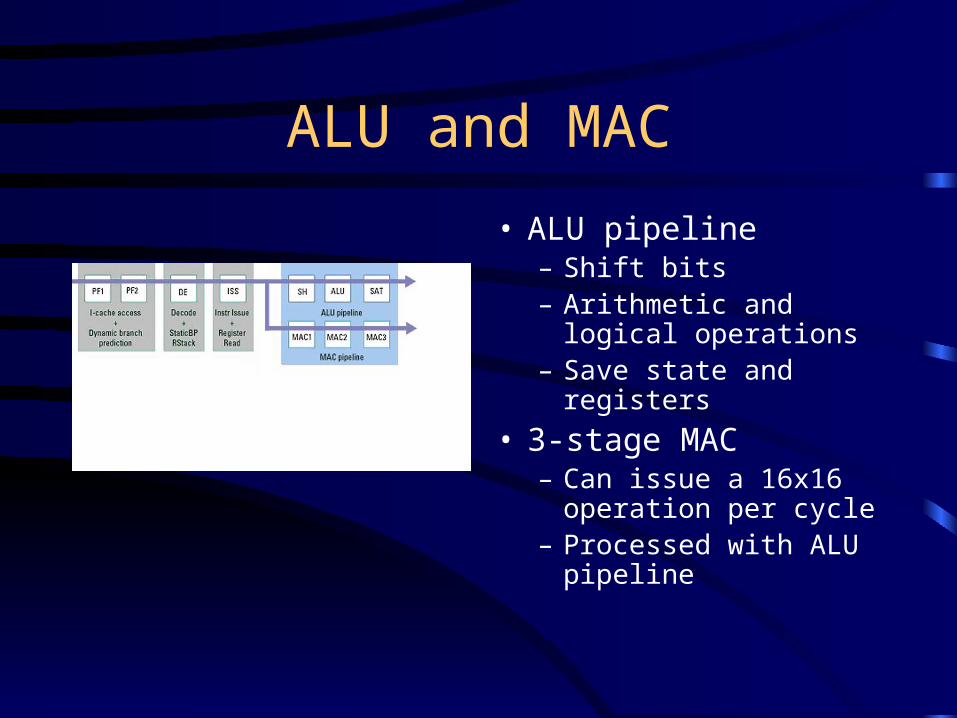
ALU and MAC
• ALU pipeline– Shift bits– Arithmetic and logical
operations– Save state and registers
• 3-stage MAC – Can issue a 16x16
operation per cycle– Processed with ALU
pipeline
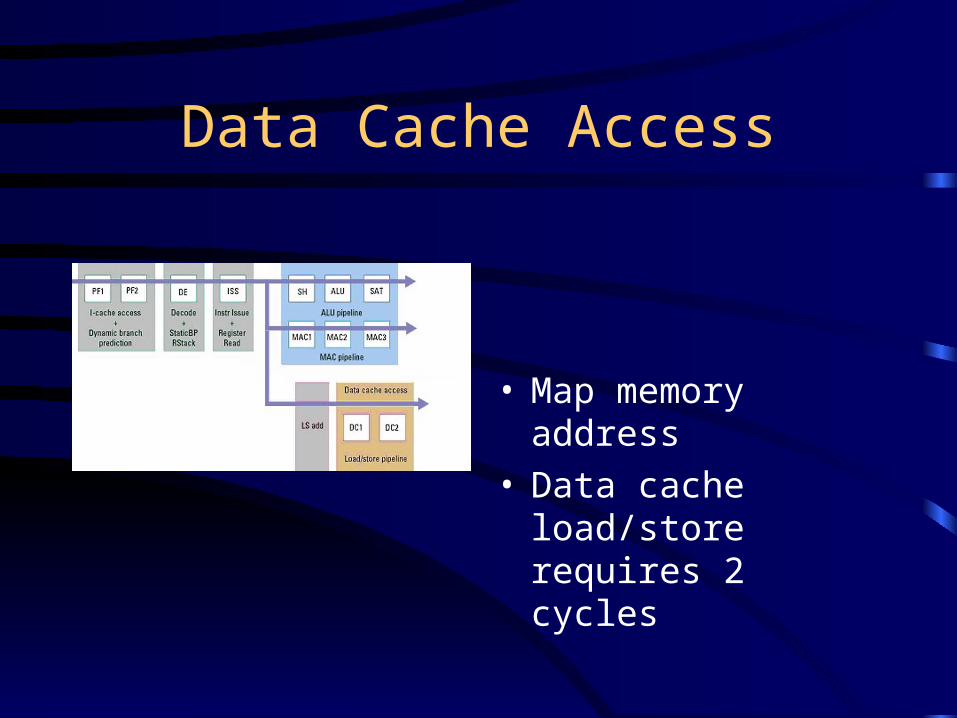
Data Cache Access
• Map memory address• Data cache load/store
requires 2 cycles

Writeback
Write results of instructions to designated memory, cache, or register
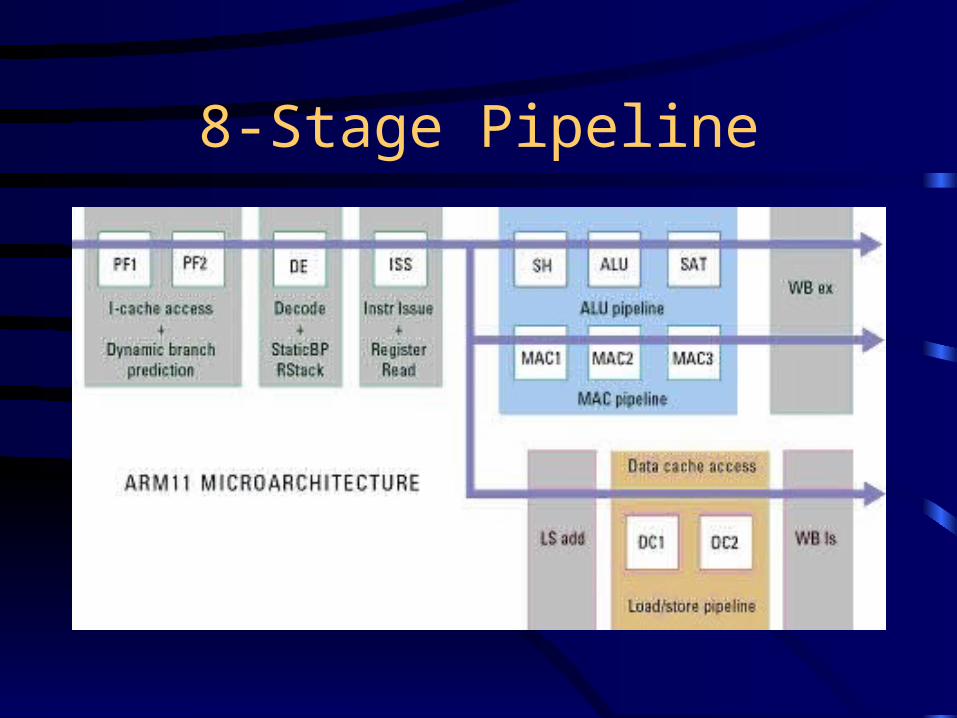
8-Stage Pipeline
Diagram by Devereau:7

Power-saving features
• >95% of registers clock gated
• WFI instruction: wait for interrupt: can disable entire clock network
• Reduced clock cycles and use of transistors

Conclusions
• ARM11 will be implemented as a family of cores – Designed for maximum performance in
wireless multimedia – A new standard in efficiency and power for
embedded applications





























