Embed Size (px)
Citation preview

2.3. Analisis bayesiano para datos normales 87
2.3. Analisis bayesiano para datos normales
Otra de las situaciones mas frecuentes en la practica estadıstica es aquella enla que nos encontramos con datos que provienen de una poblacion Normal. Estasituacion tan frecuente introduce un grado de complejidad superior al que hemosvisto en las secciones anteriores pero tambien puede ser resuelto de forma inmedia-ta bajo la perspectiva bayesiana. Esta complejidad viene determinada por el hechode que podemos considerar al problema de la inferencia en poblaciones normalescomo un problema con dos parametros de interes. Por ejemplo, supongamos elcaso mas sencillo de una observacion muesral x|µ, σ2 ∼ N (µ, σ2), y por lo tanto elparametro de interes es (µ, σ2). En tal caso, la distribucion a posteriori conjuntase deduce tambien del Teorema de Bayes
π(µ, σ2|x) ∝ L(x|µ, σ2) · π(µ, σ2),
y por tanto la densidad a priori habra de ser asignada para el parametro conjunto(µ, σ2). Las densidades a posteriori de cada una de los parametros (marginales) seobtiene entonces de la a posteriori conjunta sin mas que considerar
π(µ|x) =∫ +∞
0
π(µ, σ2|x)dσ2 =∫ +∞
0
π(µ|σ2, x)π(σ2|x)dσ2, (2.25)
π(σ2|x) =∫ +∞
−∞π(µ, σ2|x)dµ =
∫ +∞
−∞π(σ2|µ, x)π(µ|x)dµ, (2.26)
Observemos que el calculo de las marginales puede por tanto hacerse directa-mente de la conjunta o bien como una mixtura de las distribuciones condicionadasa posteriori.
En general por tanto, nos encontramos con una muestra aleatoria simple deuna poblacion normal x = (x1, ..., xn) ∼ N (µ, σ2), en tal caso la verosimilitud delos datos tendra la expresion
L(x|µ, σ2) = (2π)−n/2(σ2)−n/2 exp{−1
2
∑ni=1(xi − µ)2
σ2
}. (2.27)
Frecuentemente en el analisis bayesiano suele utilizarse el parametro τ de-nominado precision en lugar de la varianza, pues interpreta de forma directa la
dispersion de una variable aleatoria ya que viene definido por τ =1σ2
, en terminosde µ y τ la verosimilitud anterior puede reescribirse como
L(x|µ, τ) = (2π)−n/2(τ)n/2 exp
{−τ
2
n∑
i=1
(xi − µ)2}
. (2.28)
Mediante diferentes situaciones que paulatinamente iran incrementando el gra-do de complejidad resolveremos este modelo.

88 Inferencia bayesiana
2.3.1. Caso de media desconocida y varianza conocida: anali-sis conjugado
Consideremos una primera situacion en la que la varianza σ2 es conocida y quepor tanto, el unico parametro desconocido sera la media µ, sobre la que deseamoshacer inferencia.
La verosimilitud (2.28) tendra ahora la expresion
L(x|µ) ∝ exp{−1
2
∑ni=1(xi − µ)2
σ2
}, (2.29)
donde hemos prescindido (en terminos de proporcionalidad) de la parte conocida(recordemos que aquı σ2 es conocida).
El unico parametro a estimar en este modelo sera la media de la distribu-cion normal. Consideremos para este caso, una densidad a priori para µ del tipoN (µ0, σ
20) con µ0, σ
20 conocidos, es decir,
π(µ) ∝ exp(−1
2(µ− µ0)2
σ20
)(2.30)
Teorema 2.3 Para el caso de verosimilitud Normal con varianza σ2 conocida,con densidad a priori π(µ) de tipo N (µ0, σ
20) se tiene que la densidad a posteriori
es tambien Normal con parametros a posteriori
E(µ|x) = µ0 ·(
(σ20)−1
(σ20)−1 + (σ2/n)−1
)+ x ·
((σ2
1)−1
(σ20)−1 + (σ2/n)−1
)(2.31)
Var(µ|x) =1
(σ20)−1 + n(σ2)−1
(2.32)
Ademas la distribucion predictiva de una futura observacion es tambien de tipoNormal.
Demostracion: En efecto realizando el producto de (2.29) con (2.30) tenemos:
π(µ|x) ∝ exp(−1
2
∑ni=1(xi − θ)2
σ2
)· exp
(−1
2(µ− µ0)2
σ20
)∝
∝ exp{−1
2
(∑ni=1 x2
i − 2µ∑n
i=1 xi + nµ2
σ2+
µ2 − 2µµ0 + µ20
σ20
)}
∝ exp{−1
2
(µ2
(n
σ2+
1σ2
0
)+ µ
(nx
σ+
µ0
σ0
))}∝ exp
{−1
2(µ− µ1)2
σ21
}.
Observemos ademas que X ∼ N (µ, σ2/n), luego para la distribucion predictivade una simple nueva observacion y solo tenemos que considerar que y = (y−µ)+µy teniendo en cuenta que ambos sumandos son independientes uno de otro y que
(y − µ) ∼ N (0, σ2),

2.3. Analisis bayesiano para datos normales 89
µ ∼ N (µ1, σ21)
se tiene que y ∼ N (µ1, σ2 + σ2
1).Observemos que en terminos de precision hemos obtenido que la precision a
posteriori cumple la relacionτ1 = τ0 + nτ, (2.33)
es decir, que la precision a posteriori es la suma de las precisiones a priori y lasuma n veces de la precision de los datos (que se supone conocida). Para la mediaa posteriori tambien podemos deducir que,
E(θ|x) = µ1 = µ0 · τ0
τ0 + nτ+ x · τ1
τ0 + nτ
es decir, la esperanza a posteriori se puede expresar como una media ponderadade la media a priori y la media muestral. Vemos de nuevo que la familia de dis-tribuciones a priori Normal bajo muestre tambien Normal (en el caso de varianzaconocida) es una familia conjugada.
Ejemplo 2.21 Una de las cantidades de interes en la estadıstica actuarial juntocon el numero de reclamaciones que se reciben, es la cantidad reclamada (o tam-bien denominada cuantıa de la reclamacion). Veamos un ejemplo simplificado paraesta situacion. Supongamos que tratamos de estudiar la cuantıa de las reclama-ciones en una determinada poliza de un asegurado para una determinada cartera.El investigador asume que dicha cantidad se distribuye de forma normal, con me-dia µ y varianza conocida e igual a 200 euros. Realizar la inferencia bayesianaconsiderando como densidad a priori para µ ∼ N (500, 200), conocidas las ultimas5 reclamaciones de un determinado cliente: 450, 500, 650, 600 y 550 euros, cadauna.
Solucion: Puesto que estamos en las condiciones del teorema 2.3 basta con queidentifiquemos cada elemento para obtener de forma inmediata la densidad a pos-teriori. En este caso, n = 5, µ0 = 500, σ2 = 200 = σ2
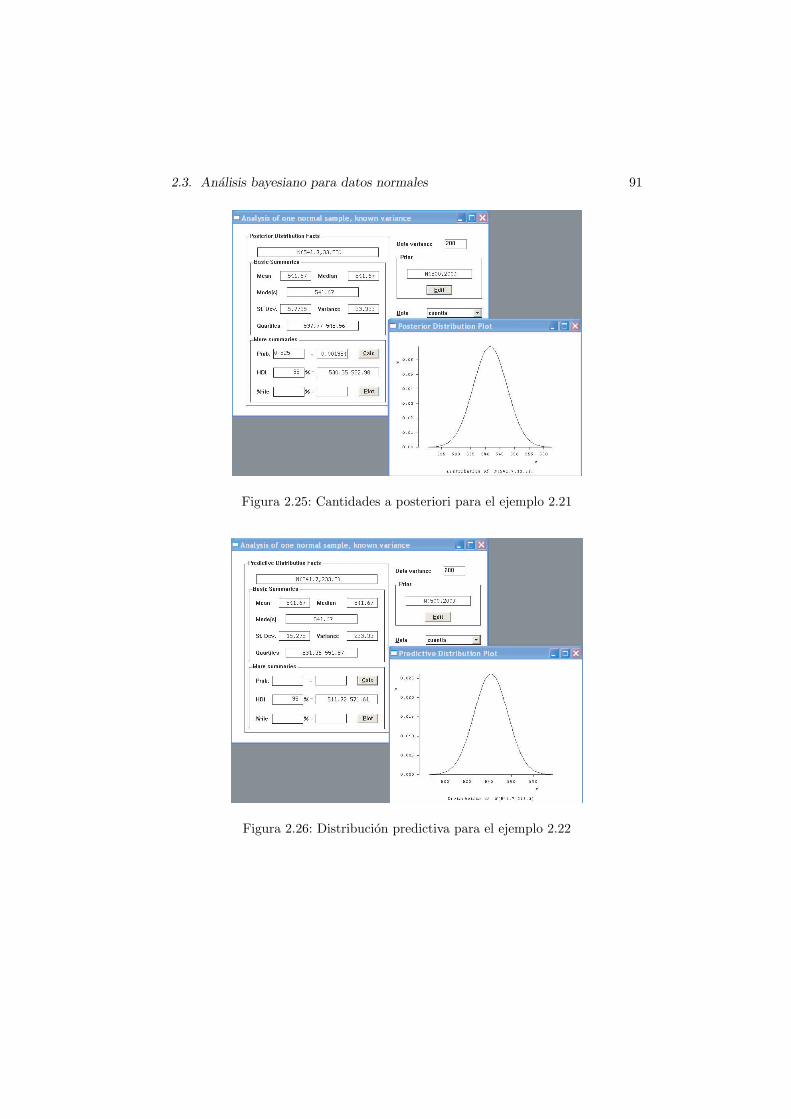
0 , x = 550, de donde se deduceque la densidad a posteriori de µ es N (541,7; 33,33). Con esta densidad a poste-riori podemos desarrollar toda la inferencia sobre µ. El caso Normal-Normal esespecialmente bien comportado para la estimacion puntual puesto que al ser unadistribucion simetrica y unimodal, tanto media como mediana y moda coinciden.En este caso valen 541,7 (es decir, un estimador bayesiano puntual de la cuantıamedia de una reclamacion para esta cartera es 541,7 euros). Un intervalo bayesianode credibilidad al 95% se obtiene facilmente de cualquier tabla de la distribucionNormal o bien, utilizando FirstBayes. En la figura 2.24 puede verse el caso deeste ejemplo. Solo debemos considerar ahora que el analisis que haremos es convarianza conocida (Normal sample, known variance en la pestana de Analysesde FirstBayes) y que en la opcion Data variance (esquina superior derecha)debemos indicar 200. Los resultados obtenidos pueden verse en la figura 2.25, de

90 Inferencia bayesiana
donde vemos que el intervalo bayesiano de credibilidad con probabilidad 0,95 es[530,35; 552,98], lo que podemos interpretar como que con probabilidad 0,95 lacuantıa media de una reclamacion de dicha cartera esta comprendida entre 530,35y 552,98 euros.
Figura 2.24: Informacion a priori para el ejemplo 2.21
♦
Ejemplo 2.22 (Continuacion ejemplo 2.21) Obtener la distribucion predicti-va de la cuantıa de una nueva reclamacion.
Solucion: Los resultados del Teorema 2.3 nos determinan directamente que ladistribucion predictiva de una nueva cantidad sera N (541,7; 233,33). En la figura2.26 pueden verse los mismos resultados obtenidos en FirstBayes donde se haincorporado tambien un intervalo bayesiano con probabilidad 0,95 para esta futuraobservacion. En este caso, obtenemos que dicho intervalo vale [511,72, 571,61],que interpretaremos de la siguiente manera: con probabilidad 0,95 la cantidadreclamada en una nueva observacion estara comprendida entre 511,72 y 571,61euros.
♦Los contrastes bayesianos para esta situacion tambien se realizan de forma
sencilla siguiendo los pasos de la seccion 10.7.3. Para el caso hipotesis nula simplefrente alternativa simple H0 : µ = µ0 vs H1 : µ = µ1, bastara con obtener el
2.3. Analisis bayesiano para datos normales 91
Figura 2.25: Cantidades a posteriori para el ejemplo 2.21
Figura 2.26: Distribucion predictiva para el ejemplo 2.22

92 Inferencia bayesiana
“odds” a posteriori mediante
p0
p1=
π0
π1· L(x|µ0)L(x|µ1)
=π0
π1·exp
{− 1
2
∑n
i=1x2
i−2nxµ0+nµ20
σ2
}
exp{− 1
2
∑n
i=1x2
i−2nxµ1+nµ2
1
σ2
} , (2.34)
siendo π0 y π1 las probabilidades a priori de cada hıpotesis. De donde deducimosque el factor Bayes vale
B01 = exp{−1
2n(µ2
0 − µ21)− 2nx(µ0 − µ1)
σ2
}. (2.35)
El siguiente ejemplo ilustra el caso de hipotesis nula y alternativa compuesta.
Ejemplo 2.23 (Continuacion ejemplo 2.21) Supongamos que en el caso delejemplo 2.21 estamos tambien interesados en realizar el contraste
H0 : µ ≤ 525 vs µ > 525.
Solucion: El contraste propuesto pasa por calcular los “odds” a priori y posterioriası como el factor Bayes asociados. Cada una de estas cantidades se obtienendirectamente de las densidades a priori y a posteriori utilizadas que en este caso sonN (500, 200) y N (541,7, 33,33), respectivamente. La figura 2.25 tiene las cantidadesnecesarias:
π0
π1=
0,9610,339
≈ 2,835,p0
p1=
0,0020,998
≈ 0,002, B01 ≈ 0,0007,
de donde deducimos que los datos no aportan ninguna evidencia en favor de H0.♦
2.3.2. Caso de media conocida y varianza desconocida: anali-sis conjugado
Analizamos ahora el caso en que la media µ = µ0 es conocida y σ2 es elparametro desconocido de esta situacion sobre el que necesitamos hacer inferencia.
La verosimilitud sera la siguiente:
L(x|σ2) ∝ (σ2)−n/2 exp(−1
2
∑ni=1(xi − θ)2
σ2
)
∝ (σ2)−n/2 exp(−1
2
∑ni=1(xi − x)2 + n(x− θ)2
σ2
)
∝ (σ2)−n/2 exp(−1
2(S + n(x− θ)2)
σ2
)

2.3. Analisis bayesiano para datos normales 93
donde S =n∑
i=1
(xi − x)2.
Como distribucion a priori del parametro σ2 suponemos una distribucion chi–cuadrado inversa de parametro S0 y ν0 grados de libertad, en notacion χ−2(S0, ν0),cuya densidad puede ser escrita en la forma:
π(σ2) ∝ (σ2)−ν0/2−1 exp(−1
2S0/σ2
).
Sus medidas descriptiva mas usuales son:
E[σ2] =S0
ν0 − 2para ν0 > 2,
Var[σ2] =2S2
0
(ν0 − 2)2(ν0 − 4)para ν0 > 4,
Moda[σ2] =S0
ν0 + 2.
La obtencion de la distribucion a posteriori para σ2 se realiza teniendo encuenta que
π(σ2|x) ∝ (σ2)−(ν0+n)/2−1 exp{−1
2S0 + S
σ2
}, (2.36)
y por tanto nuevamente tenemos una chi–cuadrado inversa de parametro (S0 +S)y ν0 +n grados de libertad. Nuevamente la propiedad de conjugacion aparece eneste caso para facilitarnos el calculo de las distribuciones a posteriori.
2.3.3. Caso de media y varianza desconocida: analisis con-jugado
Generalizamos ahora las situaciones anteriores al caso mas complejo posible enel que ambos parametros se consideran desconocidos. La expresion de la verosimil-itud es analoga a las anteriores,
L(x|µ, σ2) ∝ (σ2)−n/2 exp(−1
2(S + n(x− µ)2)
σ2
)
siendo S =n∑
i=1
(xi − x)2.
La especificacion de las distribuciones a priori es la siguiente:
µ|σ2 ∼ N (µ0, σ2/n0),

94 Inferencia bayesiana
σ2 ∼ χ−2(S0, ν0).
Los casos anteriores pueden considerarse casos particulares de esta situacionpuesto que coinciden con ella bajo el supuesto (en muchas ocasiones practicas uti-lizado) de que ambos parametros son independientes y cada uno de ellos conocido,en cada caso.
La distribucion a priori conjunta sera del tipo Normal– chi–cuadrado inversa.
π(µ, σ2) ∝ (σ2)−(ν0+1)/2−1 exp{−1
2(S0 + n0(µ− µ0)
2)/σ2
}=
∝ (σ2)−(ν0+1)/2−1 exp(−1
2Q0(µ)/σ2
)
donde Q0(µ) es la forma cuadratica
Q0(µ) = n0µ2 − 2(n0µ0)µ + (n0µ
20 + S0).
La distribucion a posteriori conjunta se obtiene como combinacion de la dis-tribucion a priori y la verosimilitud normal
π(µ, σ2|x) ∝ π(µ, σ2) · L(x|µ, σ2) ∝ (σ2)−(ν1+1)/2−1 exp(−1
2Q1(µ)/σ2
), (2.37)
donde ν1 = ν0 + n y la expresion cuadratica Q1(µ) es:
Q1(µ) = S1 + n1(µ− µ1)2 = n1µ2 − 2(n1µ1)µ + (n1µ
21 + S1)
donden1 = n0 + n,
µ1 =n0µ0 + nx
n1,
S1 = S0 + S + n0µ20 + nx− n1µ
21.
De la distribucion conjunta a posteriori podemos ahora deducir las distribu-ciones marginales a posteriori.
La distribucion condicional a posteriori π(µ|σ2,x)
La densidad a posteriori de µ dados σ2 y x es proporcional a la a posterioriconjunta dada en (2.37) con σ2 constante,
µ|σ2,x ∼ N (µ1, σ2/n).

2.3. Analisis bayesiano para datos normales 95
La distribucion marginal a posteriori, π(σ2|x)
La densidad marginal a posteriori de σ2 dados x se obtiene analıticamente de
π(σ2|x) =∫ ∞
−∞π(µ, σ2|x)dµ,
siendo π(µ, σ2|x) la densidad a posteriori conjunta dada en (2.37). Ahora bien sepa-rando los terminos en los que no estan implicados directamente terminos en µ se de-duce trivialmente que dicha distribucion (marginal) a posteriori es χ−2(S1, ν0+n).Justamente lo deducido en la seccion anterior para el caso de media conocida.
La distribucion marginal a posteriori, π(µ|x)
Para la obtencion de la densidad marginal a posteriori de µ dado x debemosintegrar la densidad conjunta con respecto a σ2. Acudiendo a la expresion (2.37)observamos que la marginal sera proporcional a
π(µ|x) ∝ {S1 + n1(µ− µ1)2
}−(ν1+1)/2, (2.38)
que corresponde a una distribucion t–Student con parametro de localizacion x,parametro de escala s y ν1 grados de libertad.
En general, una variable aleatoria tendra una distribucion t–Student con parametrode localizacion µ, parametro de escala σ y ν grados de libertad, en notacionθ ∼ tν(µ, σ2), cuando su densidad tenga la expresion
π(θ) =Γ((ν + 1)/2)Γ(ν/2)σ
√νπ
(1 +
1ν
(θ − µ
σ
)2)−(ν+1)/2
. (2.39)
La medidas descriptivas mas habituales de esta variable son
E(θ) = µ, para µ > 1,
Var(θ) =ν
ν − 2· σ2, para ν > 2,
Moda (θ) = µ.
Esta distribucion puede transformarse a la habitual t–Student con ν1 gradosde libertad considerando la transformacion
µ− µ1
s1/√
n1,
siendo s21 =
S1
ν1y n1 = n0 + n.

96 Inferencia bayesiana
2.3.4. Caso desinformativo
Al igual que en los modelos considerados en secciones anteriores, existe la posi-bilidad de realizar una analisis con datos normales considerando el caso en el queel experto no desea incorporar conocimiento a priori (porque no lo tenga o porquedesee dar todo el peso de su decision a la informacion de los datos, o por ambascosas al mismo tiempo). La asignacion desinformativa para este caso consiste enasumir que µ y σ2 son independientes y ambas les asignamos las siguientes den-sidades desinformativas (tmabien conocidas como de Jeffreys como veremos en laseccion 11.4.3),
π(µ) ∝ 1, π(σ2) ∝ (σ2)−1,
de donde se tiene que la densidad a priori conjunta no informativa es
π(µ, σ2) ∝ (σ2)−1. (2.40)
Todo el analisis a posteriori se puede seguir de forma paralela a como se harealizado anteriormente. Sin embargo, en este caso el calculo puede ser mucho massencillo si observamos que estamos ante una situacion como la descrita anterior-mente pero con valores lımite de las cantidades siguiente: ν0 = −1, n0 = 0, S0 = 0y Q0(µ) = 0, de donde deducimos automaticamente las densidades a posteriori delos parametros de interes.
Ejemplo 2.24 (Continuacion ejemplo 2.21: media y varianza desconocidas)Para el caso del ejemplo 2.21 realizar las mismas inferencias para el caso no in-formativo a priori.
Solucion: Los resultados obtenidos anteriormente y teniendo en cuenta que esta-mos en el caso no informativo, es decir, ν0 = −1, n0 = 0, S0 = 0 y Q0(µ) = 0, juntocon n = 5 y x = 550, nos permiten obtener analıticamente todas las distribuciones(marginales) a posteriori y en consecuencia sus medidas de interes. FirstBayesincluye tambien esta posibilidad mediante el analisis Normal sample, unknownvariance de su “pestana” Analyses. La figura 2.27 muestra los valores obtenidospara los estimadores bayesianos. Como vemos la distribucion a posteriori de µes t–Student generalizada cuya media (a posteriori) coincide con la mediana yla moda y valen 550 euros. El intervalo bayesiano de credibilidad al 95 % vale[451, ,81, 648,19] sensiblemente mayor al caso informativo obtenido anteriormente.Finalmente para el contraste de hipotesis H0 : µ ≤ 525 vs µ > 525, vemos que el“odds” a posteriori vale
p0
p1=
0,259310,75069
≈ 0,3454
de donde deducimos que a la luz de los datos, la hipotesis nula deberıa ser rechaza-da. Observemos que a diferencia con el caso informativo, la distribucion a posterioride µ da, en este caso, cierta probabilidad a valores mayor del parametro.

2.3. Analisis bayesiano para datos normales 97
Figura 2.27: Cantidades a posteriori para el ejemplo 2.21 con media y varianzadesconocidas
♦La distribucion predictiva (a posteriori) de una futura observacion, y, puede
obtenerse como la mixtura
p(y|x) =∫ ∫
f(y|µ, σ2) · π(µ, σ2|x)dµdσ2, (2.41)
donde f(y|µ, σ2) ∼ N (µ, σ2) y π(µ, σ2|x) es la densidad a posteriori conjuntaobtenida en (2.37). De donde la simulacion de esta distribucion pasa por generarvalores de µ y σ2 de la densidad π(µ, σ2|x) para luego generar valores de y de unaN (µ, σ2).
De hecho, la distribucion predictiva de y es t–Student con parametro de lo-
calizacion x, parametro de escala
√1 +
1n
s, con s2 =1
n− 1
n∑
i=1
(xi − x)2 y n − 1
grados de libertad, en notacion y ∼ tn−1
(x,
√1 + 1
ns)
. Esta distribucion se ob-
tiene integrando en (2.41) respecto a µ y σ2. Tambien podemos identificar este

98 Inferencia bayesiana
resultado facilmente mediante la factorizacion,
f(y|σ2,x) =∫
f(y|µ, σ2,x) · π(µ|σ2,x)dµ. (2.42)
De (2.42) se deduce que f(y|σ2,x) ∼ N (x, (1+ 1n )σ2), que resulta ser la identica
distribucion que la de µ dados σ2 y x (cambiando el factor de escala).
Ejemplo 2.25 (Continuacion ejemplo 2.24) Para el ejemplo 2.24, encontrarun intervalo bayesiano de credibilidad con probabilidad 0,95 para una futura obser-vacion sobre la cuantıa de una reclamacion.
Solucion: De (2.41) sabemos que la distribucion predictiva de una nueva obser-vacion para el caso de datos normales con ambos parametros desconocidos es una
t–Student con parametro de localizacion x, parametro de escala
(√1 +
1n
)s y
n − 1 grados de libertad. Para el caso que nos ocupa tenemos una distribuciont4(550, 7500) (ver figura 2.28).
Figura 2.28: Distribucion predictiva para el ejemplo 2.21 con media y varianzadesconocidas
El intervalo bayesiano al 95% es [485,88, 790,52], que nos indica que con prob-abilidad 0,95 una proxima reclamacion estara comprendida entre 485,88 y 790,52euros.
♦





























