Embed Size (px)
Citation preview

2. Zadaci i upravljanje zadacima U ovom poglavlju razmotrićemo sa nešto više detalja kako se, kod embedded sistema, rešavaju problemi koji se odnose na planiranje izvršenja zadataka (scheduling), rasporedjivanja zadataka (dispatching), kao i tehnike koje se koriste za ostvarivanje efikasnijeg i korektnog komuniciranja izmedju zadataka (intertask communication). Diskusiju ćemo početi sagledavanjem uloge vremena i kritične uloge koje vreme ima u fazi projektovanja sistema. 2.1. Vreme, vremensko-zasnovani sistemi, reaktivni-sistemi U poglavlju "Kerneli za rad u realnom vremenu i operativni sistemi" smo već ukazali na važnu ulogu koju ima vreme kod projektovanja i izvršenja embedded aplikacija. Sagledaćemo sada ovaj problem nešto detaljnije. Kao prvo, definisaćemo dve različite mere o vremenu: apsolutno i relativno. Apsolutno-vreme se zasniva na vremenu iz realnog-sveta, dok se relativno-vreme meri u odnosu na neku referencu. Vreme se dalje kvalifikuje bilo kao interval ili kao trajanje (duration). Interval se označava (obeležava,markira) svojim početnim i krajnjim vremenom, dok je trajanje relativna vremenska mera. Jednaki intervali moraju imati ista startna vremena i ista krajnja vremena, dok nejednaki intervali mogu biti istog trajanja. Razlike su prikazane na slici 2.0.
Slika 2.0 Jednaki intervali i jednako trajanje 2. 2 Reaktivni i vremensko-bazirani sistemi Embedded sistemi se mogu klasifikovati u sledeće dve kategorije: reaktivni i vremensko-bazirani (time-based). Kao što i samo ime ukazuje, reaktivni sistemi čine zadaci koji se iniciraju od strane nekog dogadjaja pri čemu dogadjaj, u odnosu na sistem, može biti interni ili eksterni. Interni dogadjaj može biti proteklo vreme ili vremensko ograničenje koje se odnosi na obradu podataka u slučajevima kada se premaše specificirane vremenske granice. Eksterni dogadjaj se prepoznaje kao aktiviranje komutacije sa izvršenja jednog zadatka na drugi, ili kao spoljni odziv na interno generisanu komandu. Obično eksterno inicirani dogadjaji su asinhroni u odnosu na normalnu aktivnost sistema. Ilustracije radi, foreground/background sistemi su dobar primer reaktivnih sistema. Vremensko-bazirani sistemi su oni sistemi čije je ponašanje kontrolisano od strane vremena. Takav odnos može biti:
- apsolutni- akcija se mora obaviti (desiti) za specificirano vreme, - relativni- akcija se mora obaviti nakon ili pre isteka reference, i

- nakon intervala (following an interval)- akcija se mora desiti za specificirano vreme u odnosu na neku referencu.
Ponsašanje vremensko-baziranih sistema je, u opštem slučaju, sinhrono u odnosu na vremenski elemenat jedne ili druge forme. Sistemi sa vremenskom-raspodelom (time shared systems) su dobar primer vremensko-baziranih sistema. Relevantnost vremena kod embedded aplikacija postaje jasnija kada se pokuša ostvariti plan-izvršenja (schedule) zadataka ili thread-ova, tj. donošenje odluke kada će se i koliko često svaki od zadataka/thread-ova izvršavati. Zadaci ili thread-ovi koji se iniciraju na principu repetitivnog vremenskog trajanja izmedju njihovog pozivanja (invocations) na izvršenje nazivaju se periodični zadaci / thread-ovi. Repetitivno trajanje se naziva perioda. Vreme potrebno da se završi zadatak naziva se vreme-izvršenja (execution time). Kod periodičnog sistema, varijacija u prizivanju dogadjaja naziva se džiter (jitter). Vreme izmedju prizivanju dogadjaja i ostvarivanja nameravane akcije naziva se kašnjenje (delay). Kod projektovanja sistema, za svaki kontekst, za koga se predvidja da će sistem biti operativan, mora da se sagleda i odredi značaj džitera kao i iznos kašnjenja u odnosu na specificirana vremenska ograničenja. Akcija koja se mora desiti u okviru specificiranog vremena definiše se kao stroga (hard), ili se kaže da ima strogo definisan krajnji rok izvršenja (hard deadline). Propušteni krajnji rok kod ovakvih sistema (slučajeva) smatra se da dovodi do parcijalne ili totalne greške u radu sistema. Sistem se može definisati kao hard real-time, HRT, ako sadrži jedan ili veći broj zadataka koji imaju takva ograničenja. Ovakvi sistemi mogu da imaju i druge zadatke za koje ne postoje krajnji vremenski rokovi. Bez sumnje, izazovniji za projektovanje su ipak oni sitemi koji imaju stroge-krajnje-rokove (hard deadlines). Sistemi sa relaksiranim vremenskim ograničenjima se definišu kao soft real-time, SFT. Ovakvi sistemi u proseku ispunjavaju zahteve u pogledu krajnjih rokova. Za SFT se kaže da mogu biti labavi (soft) pod sledećim uslovima:
1) U principu relaksacija ograničenja koja dovode do narušavanja krajnjih rokova i izvršenja zadataka/thread-ova uzrokuje pojavu grešaka u radu RTS-ova. SFT-ovi mogu tolerisati ne-ispunjavanje (missing) krajnjih rokova pod uslovom da je neki drugi tip krajnjeg roka ili vremensko ograničenje zadovoljen, kao na primer prosečna propusnost (average throughput).
2) Evaluacijom (procenom) korektnosti ili vremenskih rokova kao gradacione vrednosti, a ne kao kriterujum da je nešto prošlo (pass) ili nije prošlo (fail).
Sistemi koji imaju zadatke sa relaksiranim ogrqničenjima, a istovremeno i stroge krajnje-rokove (hard deadlines) nazivaju se firm real time, FRT. Tipični predstavnici FRT-ova su multimedijalni sistemi za prenos slika. RTS-ovi su oni sistemi kod kojih se zahteva korektnost u izvršenju zadataka u pogledu vremena. Kod najvećeg broja RTS-ova vrši se pažljivo upravlajnje resursima u odnosu na očuvanje predvidljivosti vremenskih ograničenja. Ovakva predvidljivost pruža nam neku meru o tačnosti na osnovu koje možemo unapred da tvrdimo kada će da se desi kao i koja akcija može da se desi. Nakon toga se daje izveštaj (elaborat) u kome se komentarišu trajanja, dogadjaji, džiter, i akcije. Na slici 2.1 prikazan je periodični-sistem koji je karakterističan za vremensko-bazirani dizajn.
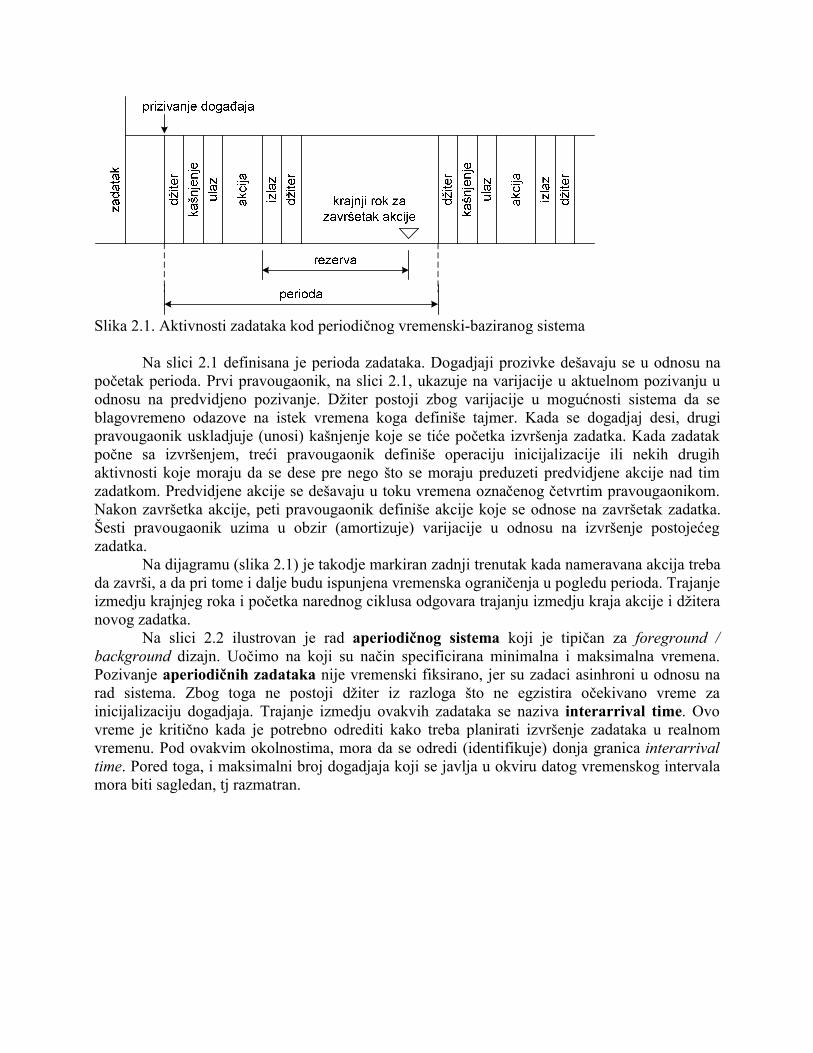
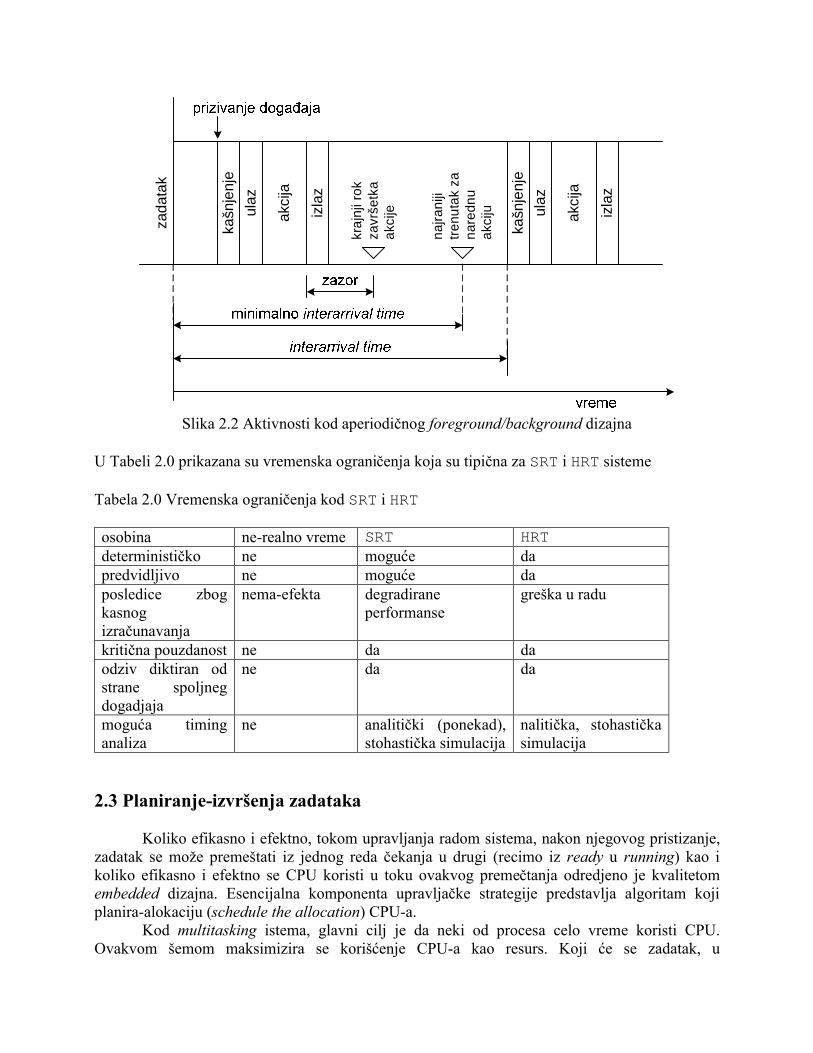
Slika 2.1. Aktivnosti zadataka kod periodičnog vremenski-baziranog sistema Na slici 2.1 definisana je perioda zadataka. Dogadjaji prozivke dešavaju se u odnosu na početak perioda. Prvi pravougaonik, na slici 2.1, ukazuje na varijacije u aktuelnom pozivanju u odnosu na predvidjeno pozivanje. Džiter postoji zbog varijacije u mogućnosti sistema da se blagovremeno odazove na istek vremena koga definiše tajmer. Kada se dogadjaj desi, drugi pravougaonik uskladjuje (unosi) kašnjenje koje se tiće početka izvršenja zadatka. Kada zadatak počne sa izvršenjem, treći pravougaonik definiše operaciju inicijalizacije ili nekih drugih aktivnosti koje moraju da se dese pre nego što se moraju preduzeti predvidjene akcije nad tim zadatkom. Predvidjene akcije se dešavaju u toku vremena označenog četvrtim pravougaonikom. Nakon završetka akcije, peti pravougaonik definiše akcije koje se odnose na završetak zadatka. Šesti pravougaonik uzima u obzir (amortizuje) varijacije u odnosu na izvršenje postojećeg zadatka. Na dijagramu (slika 2.1) je takodje markiran zadnji trenutak kada nameravana akcija treba da završi, a da pri tome i dalje budu ispunjena vremenska ograničenja u pogledu perioda. Trajanje izmedju krajnjeg roka i početka narednog ciklusa odgovara trajanju izmedju kraja akcije i džitera novog zadatka. Na slici 2.2 ilustrovan je rad aperiodičnog sistema koji je tipičan za foreground / background dizajn. Uočimo na koji su način specificirana minimalna i maksimalna vremena. Pozivanje aperiodičnih zadataka nije vremenski fiksirano, jer su zadaci asinhroni u odnosu na rad sistema. Zbog toga ne postoji džiter iz razloga što ne egzistira očekivano vreme za inicijalizaciju dogadjaja. Trajanje izmedju ovakvih zadataka se naziva interarrival time. Ovo vreme je kritično kada je potrebno odrediti kako treba planirati izvršenje zadataka u realnom vremenu. Pod ovakvim okolnostima, mora da se odredi (identifikuje) donja granica interarrival time. Pored toga, i maksimalni broj dogadjaja koji se javlja u okviru datog vremenskog intervala mora biti sagledan, tj razmatran.
zada
tak
kašn
jenj
eul
az
izla
z
akci
ja
kašn
jenj
eul
az
izla
z
akci
ja
kraj
nji r
ok
zavr
šetk
a ak
cije
najra
niji
trenu
tak
za
nare
dnu
akci
ju
Slika 2.2 Aktivnosti kod aperiodičnog foreground/background dizajna
U Tabeli 2.0 prikazana su vremenska ograničenja koja su tipična za SRT i HRT sisteme Tabela 2.0 Vremenska ograničenja kod SRT i HRT osobina ne-realno vreme SRT HRT determinističko ne moguće da predvidljivo ne moguće da posledice zbog kasnog izračunavanja
nema-efekta degradirane performanse
greška u radu
kritična pouzdanost ne da da odziv diktiran od strane spoljneg dogadjaja
ne da da
moguća timing analiza
ne analitički (ponekad), stohastička simulacija
nalitička, stohastička simulacija
2.3 Planiranje-izvršenja zadataka Koliko efikasno i efektno, tokom upravljanja radom sistema, nakon njegovog pristizanje, zadatak se može premeštati iz jednog reda čekanja u drugi (recimo iz ready u running) kao i koliko efikasno i efektno se CPU koristi u toku ovakvog premečtanja odredjeno je kvalitetom embedded dizajna. Esencijalna komponenta upravljačke strategije predstavlja algoritam koji planira-alokaciju (schedule the allocation) CPU-a. Kod multitasking istema, glavni cilj je da neki od procesa celo vreme koristi CPU. Ovakvom šemom maksimizira se korišćenje CPU-a kao resurs. Koji će se zadatak, u

specificiranom trenutku, izvršavati zavisi od većeg broja kriterijuma, a pri tome scheduler ima odgovornost da obezbedi da će CPU biti efikasno iskorišćen i da će se različiti poslovi izvršavati u takvom redosledu koji garantuje de će biti zadovoljeni (ispunjeni) zahtevi u pogledu vremenskih ograničenja. Kada koristimo scheduling algoritam, mora da se razmotri (uzme u obzir) i prioritet zadatka. Prioritet se dodeljuje od strane projektanta sistema i zasniva se na raznolikosti različitih kriterijuma. Na osnovu ovih kriterijuma se odlučuje koji će se od zadataka izvršavati u situacijama kada se više zadataka nalazi u stanje waiting (čekanje) ili ready (spreman) za izvršenje. Zadaci čiji je prioritet višlji izvršavaju se pre u odnosu na one čiji je prioritet niži. Kod RTS-ova, zadatku za koga se može proceniti da uvek ispunjava (zadovoljava) vremenska ograničenja kažemo da je schedulable (planirljiv za izvršenje). Zadatku za koga se može garantovati da će uvek ispuniti sve krajnje rokove kažemo da je deterministically schedulable. Ovakva situacija se javlja kada vreme odziva, u najgorem slučaju, za neki dogadjaj je manje ili jednako krajnjem roku izvršenja za taj dogadjaj. Kada svi zadaci mogu biti scheduled, tada za ceo sistem kažemo da može biti scheduled. Scheduling odluke se donose u fazi projektovanja sistema, jer se na osnovu ovakvih odluka prave kompromisi (trade-offs) koji imaju uticaj na ukupne performanse sistema. Kada se specifikacijom sistema definišu hard krajnji-rokovi izvršenja, tada projektanti moraju biti sigurni de će implementacijom zadatka i odgovarajućih pridruženih akcija svi krajnji rokovi biti zadovoljeni. Soft karjnji rokovi izvrešenja prirodno je da pružaju veću fleksibilnost. 2.3.1 Iskorišćenost CPU-a Pored toga što treba zadovoljiti zahteve u pogledu vremenskih ograničenja, cilj kod formulisanja task-schedule-a je da se postigne što je moguća veća zauzetost CPU-a. Idealna zauzetost bi bila 100 %. Ovakva metrika naziva se CPU utilization (iskorišćenost CPU-). Kod praktičnih sistema iskorišćenost je 40 % za slabo opterećene (lightly loaded) sisteme, a 90 % za jako opterećene (heavily loaded) sisteme. Za single-periodični zadatak, iskorišćenost CPU-a je data relacijom ui = ei / pi gde je : ui- deo vremena za koga zadatak drži CPU zauzet (busy); ei- vreme izvršenja; pi- perioda periodičnog zadatka Moguće je izvesti slični odnos za aperiodične zadatke. 2.3.2 Scheduling odluke Dva ključna elementa kod RT dizajna, repetitivnost i predvidljivost, su apsolutno esencijalni parametri u pogledu ispunjenja hard krajnjih rokova. Da bi ostvarili predvidljivost moraju se u potpunosti razumeti i definisati timing karakteristike svakog zadatka i korektno isplanirati izvršenje ovih zadataka korišćenjem predvidljivih scheduling algoritmi. Prvi korak u razvoji robustnog plana-izvršenja (schedule) se odnosi na dobrom poznavanju scheduling odluka kojih treba doneti. Scheduling odlike se donose na osnovu sledeća četiri uslova:

1. proces komutira iz stanja running u stanje waiting- inicira se od strane U/I zahteva, 2. proces komutira iz stanja running u stanje ready- dešava se kada se javi prekid, 3. proces komutira iz stanja waiting u stanje ready-tipično je za završetak U/I aktivnosti, 4. proces završava sa izvršenjem.
Ako se za donošenje scheduling odluke koriste samo uslovi 1 i 4 takav scheduling se naziva nonpreemtive. Pod ovakvim scheduling kriterijumima, proces zadržava CPU sve dok ne odluči da ga oslobodi, a to znači, do trenutka kada se njegovo izvršenje završi ili se ne obavlja komutacija na stanje waiting. Inače, za schedule kažemo da je preemtive. 2.3.3 Kriterijumi scheduling-a Danas postoji veći broj scheduling algoritama. Kada se pravi izbor nekog algoritma moraju se sagledati kako njegove osobine tako i to koji su su esencijalni zahtevi koji prate specifičnu aplikaciju. U tekstu koji sledi ukazaćemo na neke standardne metrike koje se koriste kod izbora scheduling algoritama za embedded sisteme. 2.3.3.1 Prioritet Kod dizajna koji koristi prioritet kao deo scheduling kriterijum projektant mora kritički da sagleda svaki zadatak u sistemu i dodeli mu odgovarajući prioritet. Scheduler koristi ovu informaciju u nekoliko različitih trenutaka. Ako nema zadatka u stanju running ili ako nema zadatka koji je završio sa izvršenjem, tada zadatak sa najvišim prioritetom je medju onim zadacima koji su u stanju ready i on će biti selektovan za izvršenje (najčešće prvi zadatak u redu čekanja ready procesa). Za slučaj da postoji preemptive scheduling politika, ako se izvršava zadatak sa nižim nivoom prioriteta u trenutku kada pristigne zadatak sa višim prioritetom, tada dolazeći zadatak istiskuje zadatak koji se izvršava. Zadatak sa nižim prioritetom se suspenduje. Suspendovani zadatak nastavlja sa daljim radom kada zadatak sa višim prioritetom završi sa izvršenjem ili dodje do njegovog blokiranja zbog čekanja na neki resurs. Ako zadatak sa višim prioritetom nikad ne pristigne, izvršenje zadatka sa nižim prioritetom se nastavlja do njegovog završetka. I pored toga što šema bazirana na prioritetima izgleda da obezbedjuje mehanizam da će se izvršenje zadatka uvek obavljati do njihovog kompletiranja (završetka) nije baš sve uvek tako. Kada postoji istiskivanje (preemption) može da se javi problem blokiranja. Do blokiranja dolazi kada je zadataku potreban resurs koji je vlasništvo drugog zadatka. Posmatrajmo sada nekoliko primera: Slučaj_1
1. Zadatak A ima viši prioritet u odnosu na zadatak B. 2. Zadatak B startuje i rezerviše Resurs R1. 3. Zadatak A istiskuje zadatak B. 4. Zadatak A počinje sa izvršenjem i blokira se u tačku gde mu je potreban resurs 5. Zadatak A se mora suspendovati i dozvoliti zadatku B da se kompletira kako bi ovaj
oslobodio resurs R1.

Drugi slučaj koga ćemo razmotriti karakterističan je po tome što uvodi problem nazvan priority inversion. Slučaj_2 Neka postoje tri zadatka: Zadatak A, Zadatak B, i Zadatak C. Zadatak A ima najviši prioritet a zadatak C najniži.
1. Zadatak C startuje i rezerviše Resurs R1. 2. Zadatak A ulazi i istiskuje Zadatak C. 3. Zadatak A počinje sa izvršenjem i blokira se u tački kada mu je potreban resurs R1. 4. Zadatak A mora da se suspenduje i dozvoli zadatku C da produži, nadajući se da će se
osloboditi Resurs R1. 5. Zadatak B istiskuje Zadatak C i njemu nije potreban Resurs R1. 6. Zadatak B završava i omogućava Zadatku C da nastavi.
Lako je kreirati situacije kod kojih će zadatak sa najvišim prioritetom biti zauvek blokiran. 2.3.4 Turnaround vreme Turnaround vreme specificira interval od trenutka ulaska (pristizanja) zadatka u sistem pa sve do njegovog završetka. U ovo vreme je uključeno vreme na koje on čeka da bude unet (zapamćen) u memoriji, vreme na koje zadatak provede čekajuči u redu čekanja spremnih procesa (ready queue), i vreme koje je potrebno da se zadatak izvrši od strane CPU-a ili da se obavi neka U/I aktivnost. 2.3.5 Propusnost U uskoj vezi sa turnaround time je propusnost (throughput), tj. broj procesa koji se završava za jedinstveno vreme. Treba pri ovome imati u vidu da throughput zavisi od kompleksnosti zadatka, pa zbog toga treba biti obazriv kada se manipuliše sa metrikom propusnost. Tako na primer, sistem može da ima visoku propusnost ali da ne zadovoljava zahteve u pogledu turnaround time ili vremenskih rokova (recimo krajnjioh rokova izvršenja). 2.3.6 Vreme čekanja Kod embedded sistema koji imaju ugrađen kernel ili ceo OS, put koji prođu zadaci prolazi kroz veći broj različitih redova čekanja. Kada korisnik ili sistemski zadatak uđe u sistem on se smešta u ulazni red čekanja (entry queue). Kada su svi njegovi uslovi zadovoljleni tako da on može da se izvršava, ako je CPU slobodan, zadatak se smešta u ready queue. Zadaci mogu takođe da pristignu u ready queue drugim putevima - kao na primer, ako je njihovo izvršenje bilo prekinuto od strane zadatka višeg prioriteta ili je zadatak bio blokiran zbog U/I operacije koja je trebalo da se kompletira. Kada se proces smešta u ready queue, on čeka sve dok se ne izabere za izvršenje. U trenutku kada se izabere za izvršenje za njega se kaže da je dispatched, tj. predat CPU-u na izvršenje.

U toku izvršenja, proces može inicirati U/I zahtev i smestiti ga u I/O queue, zahtevati resurs koji može biti odmah dostupan ili kreirati novi(e) podproces(i) i čekati na njihov završetak. Procesi koji čekaju na dostupnost pojedinog resursa mogu biti smešteni u redu čekanja za taj resurs. Ovaj red čekanja se često naziva device queue. Kada proces završi, on se uklanja iz svih redova čekanja. Njegova TCB i svi resursi se dealociraju. Minimizirano waiting time (vreme čekanja) kao kriterijum scheduling-a o izvršenju algoritma kao i vreme koje se provede na čekanju da se obave U/I aktivnosti imaju uticaj na ukupno vreme koje zadatak provede čekajući u redovima čekanja. U suštini, sva vremena koja se provedu u čekanju u redovima čekanja moraju biti uzeta u obzir kod evaluacije (procene) waiting time-a. 2.3.7 Vreme odziva Response time (vreme odziva) je još jedan parametar koga treba razmotriti kod rada RT embedded sistema. Kod interaktivnih sistema, turnaround time često ne predstavlja dobru meru za procenu performansi. Umesto toga bolje je uzeti u obzir (razmatrati) vreme od trenutka iniciranja (submission) zadatka do njegovog prvog odzive (first response). Pri ovome treba naglasiti da vreme prvog odziva nije vreme koje odgoovara generisanju prvog izlaza. 2.4 Scheduling algoritmi Izučavanje svih scheduling algoritama predstavlja jedan obiman posao. Mi ćemo se ograničiti samo na jedan informativan pogled koncepata i tehnika koje se koriste u ovoj oblasti. Konkretnije, ukazaćemo na jednostavne algoritme tipa asynchronous interrupt event driven, polled, i polled with timing event. Pre nego što analiziramo tipove scheduling algoritama sagledajmo prvo na koji način se embedded sistemi odazivaju na ulaze ili događaje. U zavisnosti od načina odazivanja sisteme delimo na:
1. Sistemi koji se okidaju na događaje (event triggered systems) - okidanje se ostvaruje od strane prekida koji signalizira procesoru da se događaj desio i da je potrebno (hitno) opsluživanje. Prekid se obrađuje od strane ISR-a. Event triggered system arhitekture u najvećem broju slučajeva podržavaju rad većeg broja ISR-ova.
2. Sistemi koji se okidaju vremenski (time triggered systems) - procesor analizira potencijalne izvore događaja po određenom redosledu. Ako izvorište zahteva opsluživanje, tada kažemo da se desio događaj i on se opslužuje. Postoji nekoliko varijanti ovog pristupa koji se baziraju na tehnici time-slicing. Ovakav pristup garantuje da će svako izvorište imati šansu da pristupi procesoru.
2.4.1 Asinhroni događaj iniciran prekidom Jedna od najjednostavnijih scheduling šema je asynchronous interrupt event driven (asinhroni događaj iniciran prekidom). Kod ovog pristupa sistem radi tako što izvršava jednu beskonačnu petlju sve dok se ne javi događaj tipa prekid, kako je to prikazano kôdnim fragmentom datim na slici 2.3.

global variable deklaracije isr setup function prototipovi void main(void) { local variable deklaracije while(1) // petlja zadatka } ISR-ovi function definicije
Slika 2.3. Događajno iniciran schedule algoritam
Ovaj dizajn je specijalan slučaj foreground/background modela. U ovom slučaju, dizajn ne poseduje background zadatke. Dizajn se takođe može smatrati kao da je reaktivan. Kada se desi događaj tipa prekid, tok upravljanja se prebacuje na odgovarajuću ISR čime se izvršava predviđena rutina; nakon toga upravljanje se obavlja (vraća) u beskoonačnoj petlji. U opštem slučaju događaj se inicira od strane eksternog izvora. Može se smatrati da se događaj može inicirati i od strane sistemskog tajmera. Sveobuhvatno ponašanje ovakvog sistema je teško analizirati zbog nedetermiinističke prirode asinhronih prekida. U suštini je relativno lako odrediti ponašanje sistema sa jednim (single) izvorištem prekida, a mnogo teško ponašanje sistema sa više (multiple) prekida kada su prekidima dodeljeni različiti nivoi prioriteta. 2.4.2 Polled i Polled with Timing Element Bazični polled algoritam je među najjednostavnijim i najbržim algoritmima. Sistem se kontinualno izvršava u petlji, čekajući da se desi događaj. Razlika između polled algoritma i event driven algoritma ogleda se u tome što polled algoritam kontinualno (neprekidno) testira vrednost polled signala tražeći (gledajući da dođe do) promenu stanja. Sa druge strane, kod interrupt driven dizajna ne obavlja se nikakva aktivnost sve dok se ne javi (desi) događaj. Samo u tom slučaju sistem se odaziva. Šematski polling based algoritam je prikazan na slici 2.4. global variable deklaracije function prototipovi void main(void) { local variable deklaracije while(1) // petlja zadatka { // testira se stanje svakog signala u polled setu if then construct ili switch iskaz }

} function definicije
Slika 2.4. Polling zasnovani schedule algoritam Ova šema radi dobro ako postoji samo jedan (single) zadatak. Ona je u potpunosti deterministička. Vreme odziva na događaj se može izračunati i ograničeno je. U najgorem slučaju neka se događaj javio odmah nakon izvršenja instrukcije testiranja. Pod ovakvim uslovom, vreme odziva odgovara vremenu izvršenja petlje. Polled with Timing Event predstavlja jednostavno proširenje polled based algoritma. Ova šema koristi timing element da ostvari (obezbedi) akciju kašnjenja nakon što polled event postane true. Ova tehnika poravnjava dolazeće signale. Polled model je takođe specijalan slučaj foreground/background modela. Nasuprot event driven schedule-u kod polled modela postoje samo foreground zadaci. Ovaj dizajn implementira reaktivni sistem. 2.4.3 Prednosti i nedostaci polling i preemptive scheduling pristupa I pored toga što upravljačka petlja kod polling pristupa (slika 2.5) je jednostavna za implementaciju, ona ima nekoliko ozbiljnih nedostataka. Tako na primer, čeka se dosta dugo jer procesor analizira stanje procesa/therad-ova koji ne treba da budu anallizirani, dok proces/thread koji zahteva opsluživanje mora da čeka da mu dođe red da bude analiziran, tj. dok procesor ne završi analizu ostalih procesa/thread-ova. Šta više, polling pristup ne pravi razliku između relativne važnosti koje postoje između procesa/thread-ova. Zbog toga je veoma teško procesima/thread-ovima koji postavljaju kritične zahteve u pogledu brzog pristupa procesoru da obezbede blagovremeno opsluživanje.
Slika 2.5. Upravljačka petlja kod polling pristupa RT kerneli koji koriste preemptive scheduling svakom procesu/thread-u dodeljuju prioritet, dok kernel planira (schedule) CPU-a da pristupi procesu/thread-u čiji je prioritet najviši. Postoji nekoliko varijanti kod ovog pristupa uključujući i tehnike koje procesima/thread-ovima
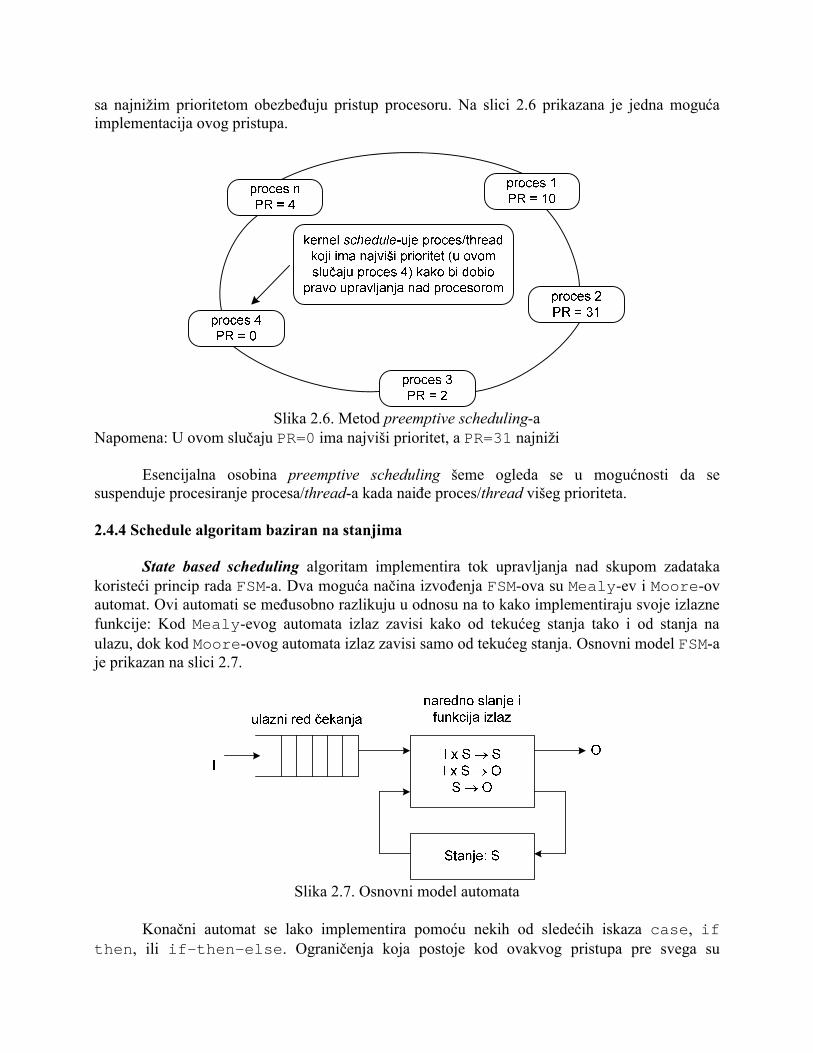
sa najnižim prioritetom obezbeđuju pristup procesoru. Na slici 2.6 prikazana je jedna moguća implementacija ovog pristupa.
Slika 2.6. Metod preemptive scheduling-a
Napomena: U ovom slučaju PR=0 ima najviši prioritet, a PR=31 najniži Esencijalna osobina preemptive scheduling šeme ogleda se u mogućnosti da se suspenduje procesiranje procesa/thread-a kada naiđe proces/thread višeg prioriteta. 2.4.4 Schedule algoritam baziran na stanjima State based scheduling algoritam implementira tok upravljanja nad skupom zadataka koristeći princip rada FSM-a. Dva moguća načina izvođenja FSM-ova su Mealy-ev i Moore-ov automat. Ovi automati se međusobno razlikuju u odnosu na to kako implementiraju svoje izlazne funkcije: Kod Mealy-evog automata izlaz zavisi kako od tekućeg stanja tako i od stanja na ulazu, dok kod Moore-ovog automata izlaz zavisi samo od tekućeg stanja. Osnovni model FSM-a je prikazan na slici 2.7.
Slika 2.7. Osnovni model automata
Konačni automat se lako implementira pomoću nekih od sledećih iskaza case, if then, ili if-then-else. Ograničenja koja postoje kod ovakvog pristupa pre svega su

posledica teoretske granice moći izračunavanja FSM-a. Pristup koji se bazira na korišćenju stanja nije tako efikasan, posebno kod sistema sa velikim brojem stanja i velikim brojem ulaza. State based dizajn po svojoj prirodi je reaktivan. 2.4.5 Sinhroni prekidno iniciran događaj Kod ovih sistema iniciranje događaja je sinhrono u odnosu na rad tajmera. Naime, sistem kontinualno izvršava petlju sve dok ga ne prekine timing signal (obično interno generisan). Timing/prekidno generisan događaj trigeruje kontekst komutaciju na ISR koja upravlja tim događajem. Schedule u ovom slučaju se bazira na periodičnom događaju kome je definisana učestanost pojavljivanja. Nasuprot periodičnom, aperiodični schedule se definiše kao sporadični. Sinhrona prekidno bazirana šema može raditi sa većim brojem zadataka i predstavljla osnovu za time-sharing sisteme. 2.4.6 Kombinovani prekidno inicirani događaj Kombinovano prekidno-inicirani događaj (combined interrupt event driven) predstavlja varijaciju dvaju dizajna koji koriste prekidno inicirane događaje kako bi dozvolili rad sinhronim i asinhronim prekidima. Kod ovakvih sistema, u trenutku kada se javi timing prekid koristi se selekcija ready zadataka zasnovana na prioritetu. Ako je većem broju zadataka dozvoljeno da imaju isti nivo prioriteta, tada se selekcija ready zadataka vrši korišćenjem šeme round robin. 2.4.7 Foregrond/background Sistem koji koristi foreground/backgroound strategiju upravljanja implementira kombinaciju prekidno i ne-prekidno iniciranih zadataka. Prekidno inicirani zadaci su predviđeni za foreground zadatke, a neprekidno za background zadatke. Background zadaci se mogu prekinuti u bilo koje vreme od strane foreground zadataka, što znači da je prioritet background zadataka najniži. Prekidno inicirani procesi, za datu aplikaciju, implementiraju aspekte rada u realnom vremenu, pri čemu prekidni događaji mogu biti sinhroni ili asinhroni. Svi prethodni algoritmi su specijalni slučajevi foregrond/background dizajna kod kojih su bilo foreground (polled sistemi) ili background (prekidno bazirani) komponente izostavljene. 2.4.8 Time shared sistemi Kod sistema sa vremenskom raspodelom (time shared systems), zadacima se može dodeliti, ali i ne mora dodeliti ista važnost. Kada se svim zadacima dodeli isti iznos vremena, schedule je periodičan, a u slučaju kada se alokacija zasniva na prioritetu, schedule je aperiodičan. Analiziraćemo sada nekoliko tipičnih algoritama koji pripadaju ovoj grupi. 2.4.8.1 Prvi-naišao prvi-opslužen Algoritam prvi-naišao prvi-se-opslužuje (first-come first-served) se može lako upravljati pomoću FIFO reda čekanja. Kada proces uđe u ready red čekanja, TCB se povezuje na repu reda čekanja. Kada CPU postane slobodan on se dodeljuje procesu sa zaglavlja reda čekanja. Proces

koji se tekuće izvršava izbacuje se (remove) iz reda čekanja. Ovakav pristup je non-preemptive i može biti uzročnik problema u radu sistema koji imaju postavljana neka RT ograničenja. 2.4.8.2 Najkraći posao prvi Schedule tipa najkraći posao prvi (schortest job first) pretpostavlja da se CPU koristi u paketnoj (burst) aktivnosti. Svakom zadatku je pridružena procena o tome koliko mu je vremena potrebno za izvršenje pre nego što se preda CPU-u. Procena se bazira na merenju dužine izvršenja tokom prethodnog korišćenja CPU-a od njegove strane. Sam algoritam može biti preemptive ili non-preemptive. Kod preemptive schedule-a proces koji se tekuće izvršava se može prekinuti od strane onog procesa čije je procenjeno vreme izvršenja kraće u odnosu na ostalo vreme izvršenja do kraja tekućeg procesa. 2.4.8.3 Round robin Round robin algoritam je specijalno projektovan za time schared sisteme. Po svom konceptu je sličan first come first served, sa izuzetkom što postoji dodatna mogućnost za istiskivanje radi komutacije između procesa. Definiše se kratka vremenska jedinica nazvana time quantum ili slice, a ready red čekanja se tretira kao kružni (cirkularni) red čekanja. Scheduler prolazi kroz red čekanja, alocirajući CPU svakom od procesa za po jedan time slice. Ako proces završi za kraće vreme od njemu dodeljenog, on oslobađa CPU, inače proces se prekida kada mu vvreme istekne i smešta se na kraju reda čekanja. Novi procesi se dodaju na repu reda čekanja. Naglasimo da ako se time slice poveća do beskonačnosti, round robin postaje first come first served scheduler. 2.4.9 Schedule zasnovan na prioritetu Shortest job first predstavlja specijalan slučaj opšte scheduling klase algoritama zasnovanih na prioritetu. Prioritet, u principu, se dodeljuje svakom procesu, a CPU se alocira procesu čiji je prioritet najviši. Poslovi sa jednakim prioritetima se planiraju radi izvršenja koristeći šemu first come first served ili round robin. Glavni problem sa priority scheduler-om ogleda se u postojanju nedefinisanog blokiranja ili od starving-priority inverzije. Algoritmi ovog tipa mogu biti preemptive i nonpreemptive. 2.4.9.1 Rate-monotonic Kod preemptive schedule tekuće aktivni proces se može prekinuti od strane drugog čiji je prioritet viši. Specijalna klasa prioritetno iniciranih algoritama naziva se rate-monotonic. Prioritet kod ovog algoritma se zasniva na periodu izvršenja procesa, što je kraći period to je prioritet viši. Za osobine koje su određene i dodeljene u toku vremena projektovanja, a nakon toga ostaju nepromenljive (fiksne) u toku vremena izvršenja, kažemo da koriste statičku ili fiksnu scheduling politiku. Mogućnost planiranja izvršenja skupa zadataka se izračunava kao granična vrednost u korišćenju CPU-a i data je relacijom.
−≤∑
−
=12
11
0
nn
i i
i npe
(1)

gde je: e - vreme izvršenja zadatka; p - perioda zadatka Kod ovog pristupa učinjene su sledeće pretpostavke:
- krajnji rok svakog zadatka odgovara njegovoj periodi - bilo koji zadatak se može istisnuti u bilo koje vreme.
Izraz na desnoj strani određuje graničnu vrednost iskorišćenja CPU-a; granična vrednost je ekstremna i ona je najgori slučaj. Ako se ne može ispuniti, mora se sprovesti detaljna analiza koja će pokazati da li se planiranje izvršenja zadatka može ostvariti. Jednačina (1) postavlja uslov da granica iskorišćenosti CPU-a bude 69%. U principu, granicu možemo relaksirati do približno 88%, a da se i dalje zadatak može planirati za izvršenje. Osnovni algoritam koji smo prethodno pomenuli pojednostavljuje analizu sistema. Scheduling je statički, a najgori slučaj se javlja kada svi poslovi treba da startuju istovremeno. Formalna analiza, koju nećemo razmatrati, ukazuje nam da rate-monotonic schedule se alternativno naziva critical zone theorem - ako je izračunata iskorišćenost CPU-a manja od iskorišćene granične vrednosti, tada se za sistem garantuje da zadovoljava sve krajnje rokove za sva moguća uređenja zadataka -. Kod nonpreemptive schedule, zadatak koji tekuće pristigne a ima najviši prioritet smešta se u zaglavlje reda čekanja spremnih procesa. 2.4.9.2 Najraniji krajnji rok Dinamička verzija rate-monotonic algoritma se naziva earliest deadline (najraniji krajnji rok). Ovaj schedule koristi dinamički algoritam kod koga se prioritet zasniva na zadatku sa najkraćim krajnjim rokom. Schedule se uspostavlja i modifikuje u toku vremena izvršenja, jer se jedino tada mogu odrediti krajnji rokovi. Za skup zadataka se kaže da je schedulable ako je suma task loading manja od 100%. Za schedule se smatra da je optimalan kada se izvršenje zadataka može isplanirati od strane algoritma. Kod ovog algoritma kad god se donosi odluka scheduler mora kontinualno da određuje koji zadatak treba da se izvrši kao naredni. Implementacija ovakvih analitičkih metoda je mnogo složenija u odnosu na slučajeve koji koriste fiksni prioritet. 2.4.9.3 Najmanja labavost Algoritam tipa least laxity (najmanja labavost) je sličan algoritmu earliest deadline sa nešto blažim čvrstim ograničenjima. Pored krajnjeg roka, uzima se u obzir i vreme izvršenja zadatka. Prioritet se bazira na sledećem odnosu. (Jasno je da zadatak čija labavost ima negativnu vrednost ne može da ispuni zahteve u pogledu krajnjeg roka.) labavost = krajnji_rok - vreme_izvršenja Least laxity algoritam se može koristiti kod sistema koji imaju implementirano hard i soft krajnje rokove. 2.4.9.4 Maksimalna urgentnost

Algoritam maximal urgency first poseduje osobine rate-monotonic i least laxity algoritama. Kao prvo, prioritet se dodeljuje na osnovu periode zadatka, kakav je slučaj kod rate monotonic algoritma. Nakon toga, dodaje se binarno-kritični parametar zadatka. Na osnovu parametra, zadatke delimo na dva skupa: kritični i nekritični. Nakon ovoga least laxity algoritam se primenjuje nad zadacima iz kritičnog skupa. Parametar kritičnosti i dodela prioriteta se određuju u toku izvršenja (runtime). Ako nema kritičnih zadataka koji čekaju na izvršenje tada zadaci iz nekritičnog skupa se planiraju za izvršenje. S obzirom da se kritični skup bazira na rate monotonic algoritmu, schedule se može struktuirati tako da ne postoje kritični zadaci koji neće ispuniti svoje krajnje rokove. 2.5 Razmatranja u vezi RT scheduling-a RTS-ovi mogu biti HRT ili SRT, dok sheduling zadataka može biti statički ili dinamički. Kod dinamičkog HRT scheduling-a procesima se pridružuje i iskaz koji se odnosi na potrebno vreme da se izvrši proces i obavi U/I aktivnost. Kada nakon procene zahteva koje postavlja zadatak, scheduler prihvati zadatak, tada scheduler je taj koji garantuje da će se zadatak izvršiti na vreme. Inače on odbacuje zadatak kao nonschedulable. Garancija da će se nešto završiti na vreme podrazumeva poziv za rezervacijom resursa (resource reservation) i iziskuje od scheduler-a da tačno zna koliko će se određena funkcija OS-a izvršavati kako bi garantovao da će se zadatak na vreme zavrvšiti. Ovakvu restrikciju je nemoguće premostiti kod sistema koji koriste sekundarnu memoriju ili kod onih koji koriste algoritme za raad sa virtuelnom memorijom. SRT schedule je manje restriktivan iz razloga što ne zahteva da je prioritet kritičnih procesa viši od nekritičnih. Implementacija SRT sistema zahteva pažljivi dizajn scheduler-a i drugih srodnih aspekata OS-a. I dalje postoje zahtevi koji se odnose na prioritetni scheduling. Pri ovome RT procesi moraju imati najviši prioritet, a prioritet ne sme biti degradiran tokom vremena. Ovakvo ograničenje je relativno lako ostvariti. Šta više, dispatch latencija mora biti mala, dook sistemski pozivi moraju biti preemptable (imati mogućnost za istiskivanje). Ovakav zahtev se može ostvariti na nekoliko načina. Jedan od načina se sastoji u insertovanju tačaka-istiskivanja (preemption points) u kojima sistem može da proveri da li postoji potreba za izvršenjem procesa čiji je prioritet viši. Alternativno, ceo kernel se može realizovati da bude preemptable. U takvoj situaciji, sve strukture podataka kernela moraju biti zaštićene, i mora da postoje metode za sinhronizaciju rada. Preemption proces čine sledeće dve komponente: konfliktna faza (conflict phase), i dispatch phase. U toku konfliktne faze dozvoljeno je istiskivanje bilo kog procesa koji se izvršava u kernelu. To znači da proces sa nižim prioritetom mora da oslobodi neophhodne resurse. Naredni korak se odnosi na kontekst komutaciju na proces sa višim prioritetom. U fazi dispatch, proces se premešta iz stanja ready u stanje run. 2.6 Evaluacija algoritma Kada postoji obilje algoritama pri čemu se svaki karakteriše svojim parametrima, izbor korektnog i odgovarajućeg algoritma može da predstavlja problem. Da bi sproveli evaluaciju (procenu) neophodno je prvo ustanoviti kriterijume za njegovo ocenjivanje. Tako na primer, iskorišćenost CPU-a, vreme odziva, i propusnost mogu biti najvažniji kritični faktori dizajna. Nakon toka kandidat algoritmi moraju se proceniti u odnosu na selekcione kriterijume. Ponovo, i u ovom slučaju, postoji veliki broj različitih metoda.

2.6.1 Determinističko modeliranje Glavna klasa metoda koja se koristi za procenu kvaliteta algoritma bazira se na konceptu analitičke evaluacije. Ovaj pristup koristi kandidat algoritam i reprezentativno sistemsko radno-opterećenje (system workload) na osnovu kojih se izvodi formula ili dobija brojna vrednost. Brojna vrednost se nakon toga koristi za procenu algoritama. Jedan od takvih metoda se naziva determinističko modeliranje. Da bi videlli kako metod determinističko modeliranje radi posmatraćemo sledeće procese i radna opterećenja. Smatraćemo da su procesi P1 do P5 svi pristigli pre početka izračunavanja, po redosledu P1 prvi, P2 drugi, ..., P5 zadnji.
proces paketno (burst) vreme izvršenja
P1 P2 P3 P4 P5
10 29 3 7 12
Na slikama 2.8a) do 2.8c) prikazani su rezultati evaluacije sledećih scheduling algoritama u odnosu na zadato radno opterećenje:
- prvi naišao prvi opslužen (first-come first-served, FCFS) - najkraći posao prvi (shortest job first, SJF) - round robin, RR
Počevši od FCFS, svaki algoritam biće evaluiran sa ciljem da se postigne najkraće prosečno vreme čekanja.
proces vreme čekanja P1 P2 P3 P4 P5
0 10 39 42 49
vreme čekanja prosečno 28
vremenskih jedinica
Slika 2.8a) Algoritam tipa FCFS
Pretpostavlja se da poslovi ulaze u sistem po prikazanom redosledu. Kod ovog algoritma prosečno vreme čekanja iznosi 28 vremenskih jedinica. Naredni schedule koga ćemo sagledati je SJF.

proces vreme čekanja P3 P4 P1 P5 P2
0 3 10 20 32
vreme čekanja u proseku 13
vremenskih jedinica
Slika 2.8b) Algoritam SJF
U ovom slučaju prosečno vreme čekanja za početak izračunavanja iznosi 13 vremenskih jedinica. U odnosu na FIFO schedule kod ovog algoritma vreme čekanja je skraćeno skoro za dva puta. Kod RR algoritma, time-slice je postavljen na 10 vremenskih jedinica. Pod ovakvim uslovima poslovi P1, P3 i P4 kompletiraće se (izvršiti do kraja) u njima dodeljenim vremenima, dok će P2 i P5 biti istisnuti (preempted) i vraćeni u red čekanja.
proces vreme čekanja P1 P2 P3 P4 P5
0 34 20 23 40
vreme čekanja u proseku 23.4
vremenskih jedinica
Slika 2.8c) Algoritam RR
Na osnovu prethodne analize jasno je da će SJF algoritam biti najbolji izbor iz razloga što je kod njega specifična metrika prosečno-vreme-čekanja najkraće. Kao što se vidi determinističko modeliranje je jednostavno i brzo, ali ne zahteva tačno poznavanje vremena procesa, što ponekad može da stvara poteškoće. Jedno bolje rešenje ogleda se u merenju vremena procesa kada se izvršenja ponavljaju. 2.6.2 Modeli redova čekanja Ako kod projektovanog sistema broj procesa koji se izvršava varira iz dana u dan, tj. globalno u vremenu posmatrano ne postoji statički skup procesa, tada se deterministički model ne može efikasno koristiti. Statističke analize pokazuju da izvršenje zadatka u opštem slučaju čine sledeća dva ciklusa: a) ciklus CPU-ovog izvršenja; i b) ciklus U/I aktivnosti. Vremena trajanja
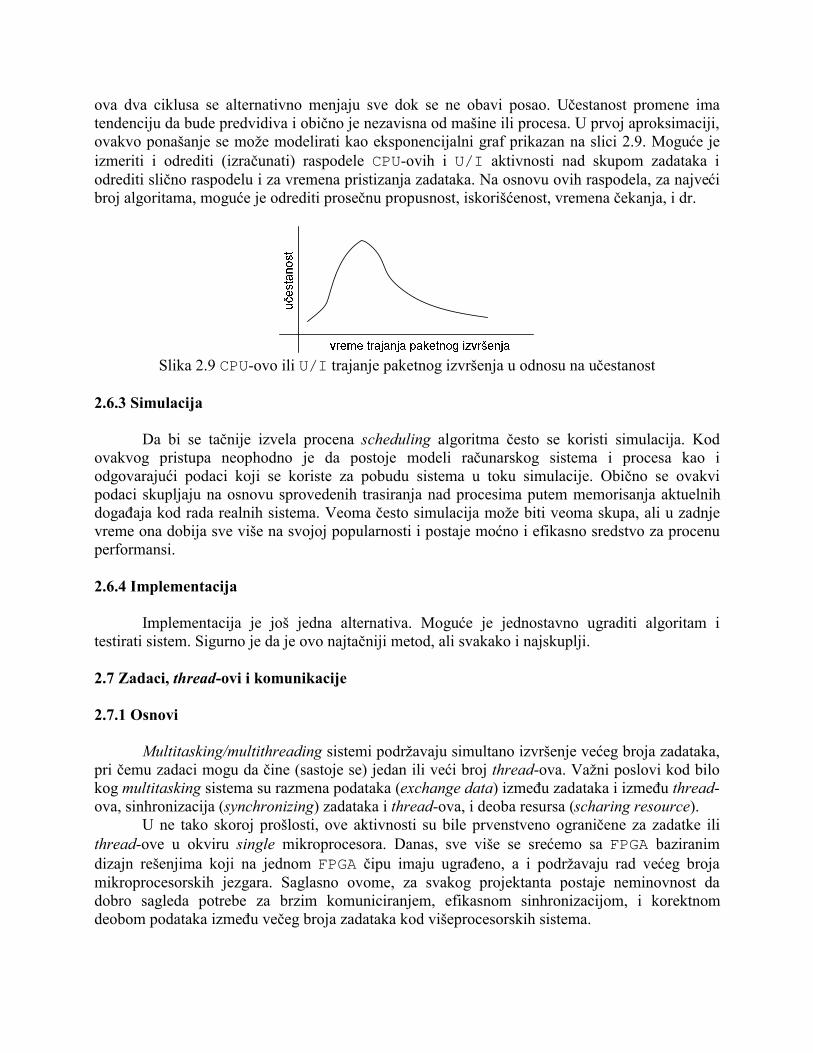
ova dva ciklusa se alternativno menjaju sve dok se ne obavi posao. Učestanost promene ima tendenciju da bude predvidiva i obično je nezavisna od mašine ili procesa. U prvoj aproksimaciji, ovakvo ponašanje se može modelirati kao eksponencijalni graf prikazan na slici 2.9. Moguće je izmeriti i odrediti (izračunati) raspodele CPU-ovih i U/I aktivnosti nad skupom zadataka i odrediti slično raspodelu i za vremena pristizanja zadataka. Na osnovu ovih raspodela, za najveći broj algoritama, moguće je odrediti prosečnu propusnost, iskorišćenost, vremena čekanja, i dr.
Slika 2.9 CPU-ovo ili U/I trajanje paketnog izvršenja u odnosu na učestanost
2.6.3 Simulacija Da bi se tačnije izvela procena scheduling algoritma često se koristi simulacija. Kod ovakvog pristupa neophodno je da postoje modeli računarskog sistema i procesa kao i odgovarajući podaci koji se koriste za pobudu sistema u toku simulacije. Obično se ovakvi podaci skupljaju na osnovu sprovedenih trasiranja nad procesima putem memorisanja aktuelnih događaja kod rada realnih sistema. Veoma često simulacija može biti veoma skupa, ali u zadnje vreme ona dobija sve više na svojoj popularnosti i postaje moćno i efikasno sredstvo za procenu performansi. 2.6.4 Implementacija Implementacija je još jedna alternativa. Moguće je jednostavno ugraditi algoritam i testirati sistem. Sigurno je da je ovo najtačniji metod, ali svakako i najskuplji. 2.7 Zadaci, thread-ovi i komunikacije 2.7.1 Osnovi Multitasking/multithreading sistemi podržavaju simultano izvršenje većeg broja zadataka, pri čemu zadaci mogu da čine (sastoje se) jedan ili veći broj thread-ova. Važni poslovi kod bilo kog multitasking sistema su razmena podataka (exchange data) između zadataka i između thread-ova, sinhronizacija (synchronizing) zadataka i thread-ova, i deoba resursa (scharing resource). U ne tako skoroj prošlosti, ove aktivnosti su bile prvenstveno ograničene za zadatke ili thread-ove u okviru single mikroprocesora. Danas, sve više se srećemo sa FPGA baziranim dizajn rešenjima koji na jednom FPGA čipu imaju ugrađeno, a i podržavaju rad većeg broja mikroprocesorskih jezgara. Saglasno ovome, za svakog projektanta postaje neminovnost da dobro sagleda potrebe za brzim komuniciranjem, efikasnom sinhronizacijom, i korektnom deobom podataka između večeg broja zadataka kod višeprocesorskih sistema.

2.7.2 Intertask/interthread komunikacija Kada se zadaci izvršavaju nezavisno, tada realno postoji opasnost da dođe do: a) konflikta u radu; b) nekorektnosti u radu; i c) sudara. Kod realnih sistema pomenuti problemi moraju biti uspešno rešeni na jedan robustan, siguran, i bezbedan način. Interakcija između zadataka se može izvesti na direktan i indirektan način i mora biti sinhronizovana i koordinisana. Pri tome je neophodno izbeći race conditions - uslovi kod kojih ishod izračunavanja zavisi od redosleda po kome se zadaci izvršavaju. Jedna tipična razmena informacije je prikazana na slici 2.10.
Zadatak 2
Zadatak 1razmena
informacije
upravljanje
embedded aplikacija
Slika 2.10. Intertask komunikacija
Interakcija i razmena između zadataka zahteva tri osnovne komponente: i) informacija koja treba da se razmeni; ii) mesto gde će se ta informacija naći i mesto gde će se ona smestiti; i iii) dogovor o tome kako će se ostvariti interakcija i razmena. Ovi zahtevi su objedinjeni u sledeći model interprocesne komunikacije i sinhronizacije:
- informaciija - podaci ili signali koji se kopiraju, - mesto ili mesta iz/u kojih/koja se informacija kopira, - upravljanje i sinhronizacija - akcija i kopiranje informacije.
Kod ovog modela, mesta - izvorište i odredište(a) razmene - se mogu identifikovati na različite načine, recimo imenovanjem promenljivih ili pokazivača promenljivih lokacija u kojima se čuvaju memorijske adrese. Upravljanje i koordinacija uključuje veći broj različitih tehnika počev od onih koje se odnose na rad sa markerima ili statusnim bitovima do onih koji se tiču manipulisanja prekidima ili upravljanja pristupima kritičnim oblastima što se ostvaruje pod kontrolom semafora ili monitora. Informacija se kopira preko deljivih promenljivih (schared variables), ili poruka (messages). Ukazaćemo prvo na intertask komunikaciju i sinhronizaciju sagledavajući komponentu deljiva-informacija. Ovakva deoba se ostvaruje na razlličite načine. 2.7.3 Deljive promenljive

Deoba se može ostvariti na različite načine. Analizu ćemo početi najjednostavnijim modelom: deljive globalne promenljive. 2.7.3.1 Globalne promenljive Fundamentalno rešenje za razmenu podataka između zadataka je okruženje koje se bazira na deljivoj memoriji. Kod ovakvog okruženja, globalne promenljive mogu biti efikasan mehanizam za deobu informacije. U postupku manipulisanja sa glopobalnim promenljivim egzistiraju ozbilljni problemi koji se javljaju kada dva ili veći broj zadataka treba da pročita deo globalnih podataka i potencijalno modifikuje te vrednosti. Glavna prednost globalno promenljivih je ta što njih ne treba, u toku kontekst komutacije, kopirati u magacin. Izbegavanjem (premošćavanjem) potreba za kopiranjem štedi se na vremenu što je od posebne važnosti kod HRT problema. Ako se sa globalnim promenljivim korektno manipuliše, one mogu biti veoma efikasno sredstvo za deobu informacije. 2.7.3.2 Deljivi bafer Deljivi bafer (shared buffer) je tehnika za razmenu informacije kod koje dva procesa dele zajednički skup memorijskih lokacija kako je to prokazano na slici 2.11.
Slika 2.11 Intertask komunikacije koje koriste deljivi bafer
Proizvođač (producer) podataka smešta podatke u bafer, a potrošač (consumer) ih izbavlja. Naglasimo da i u ovom slučaju postoji nekoliko ozbiljnih problema. Tako na primer, ako je jedan proces brži od drugog, tada postoji realna opasnost od pojave prekoračenja (overrun) ili podbačaja (underrun) u radu sa baferom. Drugim rečima, identifikacija korektnog obima bafera (za datu aplikaciju) kao i definicija protokola za pristup baferu, predstavljaju kritične stavke za izbegavanje problema overrun i underrun. Šta više, kada je obim bafera korektno određen, proizvođač i potrošač, pre insertovanja ili izbavljanja podataka iz magacina uvek proveravaju stanje bafera. Dobra dizajn praksa kod manipulisanja deljivim baferom se bazira na pozivu test procedure. buf isFull() or buf isEmpty()

Ova procedura treba da se uvek pozove pre nego što se vrši čitanje ili upis podataka u bafer. 2.7.3.3 Dvostruki deljivi bafer - ping-pong bafer Model dvostrukog deljivog bafera (shared double buffer) omogućava da dva zadatka dele dva (ili više) zajednička(ih) skupa(ova) memorijskih lokacija. Dijagram toka prenosa podataka i upravljanja je prikazan na slici 2.12. Ova konfiguracija se takođe naziva ping-pong bafer.
Slika 2.12. Intertask komunikacije koje koriste dvostruki deljivi bafer
Nekoliko šema upravljanja se koristi kod ping-pong bafera. Analizirajmo onu prikazanu na slici 2.13. Neka proces T0 predstavlja proizvođač, a T1 potrošač. Na početku rada usvojimo da su oba bafera prazna. U toku rada, proces T0 upisuje u bafer B0 sve dok se on ne napuni. U međuvremenu proces T1 je blokiran jer podatak nije dostupan. Kada se B0 popuni, T0 signalizira procesu T1 da je B0 pun i komutira (prebacuje se) na upisivanje u bafer B1. Proces T1 mmože sada ppočeti sa čitanjem podataka iz bafera B0. Kada T1 izbavi sve podatke iz B0, on signalizira procesu T0 da je bafer B0 prazan. Ako je T0 poppunio B1, tada T1 mmože početi čitanje podataka iz B1, inače T1 mora da čeka. Na sličan način, ako T0 završi sa upisom u B1 pre nego što je T1 ispraznio B0, tada se T0 mora zaustaviti (blokirati). Princip razmene podataka preko deljivog bafera je prikazan na slici 2.13. Pristup dvostrukog-baferovanja predstavlja efikasan način za razmenu informacije između procesa koji rade sa različitim brzinama. Dok se jedan bafer puni, drugi se prazni. Pri tome proces potrošač se blokira kada ne postoje dostupni podaci za njega, a proces proizvođač mora da izbegne prepunnjavanje bafera, tj. blokira se kadda je bafer pun. Task T0 while(1) ............ if (B0 = = EMPTY) repeat smesti podatak u nextB0 until (B0 = = FULL) signal (T1, FULLB0)
Task T1 while(1) ............ if (B0 = = FULL) repeat pribavi podatak iz nextB0 until (B0 = = EMPTY) signal (T0, EMPTYB0)

endif if (B1 = = EMPTY) repeat smesti podatak u nextB1 until (B1 = = FULL) signal (T1, FULLB1) endif ............ end while
endif if (B1 = = FULL) repeat pribavi podatak iz nextB1 until (B1 = = EMPTY) signal (T1, EMPTYB1) endif ............ end while
Slika 2.13. Dva zadatka razmenjuju informaciju koristeći deljivi bafer
Druga varijanta ping-pong bafera,o kojoj čemo govoriti, koriti više od dva bafera. Pretpostavimo, ponovo da imamo dva zadatka T0 i T1, i da prvi zadatak proizvodi zadatke sa brzinom (frekvencijom) od 4MHz, a drugi može da prihvata te zadatke sa brzinom od 1MHz. Da bi iskomplikkovali problem uzećemo da se u deljivi bafer može upisivati brzinom od 1MHz. Implementacija za rešavanje problema kojom se reguliše tok podataka i tok upravljannja je prikazana na slici 2.14.
Slika 2.14. Deljiva informacijaj između zadataka koji se izvršavaju različitim brzinama
Na slici 2.15 prikazani su pseudo-kodni fragmenti koji ilustruju kako se izvršava ova sinhronizirajuća šema. U svaki bafer se upisuje frekvencijom od 1MHz. Baferi se paketno pune (filled in bursts) od strane procesa T0, a čitaju uniformnom brzinom od strane T1. Task T0 while(1) ............ if (B3 = = EMPTY) repeat smesti podatak u nextB0 smesti podatak u nextB1
Task T1 while(1) ............ if (B3 = = FULL) repeat pribavi podatak iz nextB0 pribavi podatak iz nextB1

smesti podatak u nextB2 smesti podatak u nextB3 until (B3 = = FULL) signal (T1, FULLB3) endif ....... end while
pribavi podatak iz nextB2 pribavi podatak iz nextB3 until (B3 = = EMPTY) signal (T1, EMPTYB3) endif ........ end while
Slika 2.15. Deoba informacije između dva zadatka koji se izvršavaju različitim brzinama
2.7.3.4 Kružni bafer Kružni bafer (ring buffer) koristi FIFO strukturu (vidi sliku 2.16). Struktura omogućava simultani ulaz i izlaz koristeći pokazivače tipa zaglavlje i rep. Zadatak T0, proizvođač, unosi podatke u bafer, dok zadatak T1, potrošač, izbavlja podatke iz bafera. Kao i kod manipulisanja sa drugim baferima mora se voditi računa da ne dođe do prepunjenja (overflow), ili izbavljanja podataka iz praznog bafera (underflow).
Slika 2.16. Deoba informacije koristeći kružni bafer
2.7.3.5 Mailbox Mailbox (poštanski sanduk) je struktura koja koristi semantiku pristupa sličnu onoj koja se koristi kod redova čekanja. Dva ili veći broj zadataka mogu da koriste mailbox za predaju (preenos) podataka ili za sinhronizaciju. U velikom broju slučajeva mailbox-ovi su sastavni delovi OS-a. Kod mailbox strukture podataka definišu se sledeće dve operacije: a) operacija upis nazvana post; i b) operacija čitanja nazvana pend. Kada proces post-uje podatak u mailbox, marker (flag) pridružen mailbox-u se postavlja na 1 ukazujući da je podatak dostupan. Zadatak koji očekuje (pending) podatke proverava da li je taj marker postavljen. Kada je marker postavljan on čita podatke i resetuje marker. Pend i post operacije se izvode na sledeći način: post (mailbox, podaci) // upis u mailbox pend (mailbox, podaci) // čitanje iz mailbox-a

Na prvi pogled pend operacija izgleda ista kao i poll iz razloga što poll zadatak kontinualno ispituje polled promneljivu okupirajući CPU da stalno proverava promenu stanja signala. Nasuprot ovakvog pristupa, pending zadatak se suspenduje i CPU se predaje drugom zadatku, za slučaj kada ne postoji dostupan podatak, a (zadatak) se probudi kada podatak bude dostupan. To znači da je kod polling operacije CPU okupiran testiranjem stanja signala poll, dok se kod pend operacije CPU oslobađa i prepušta drugom zadatku. Razni tipovi podataka se mogu prenostiti preko mailbox-a, kakvi su single bit ili flag, single podatak, pokazivač (pointer) na bafer podataka ili neku složeniju poruku. Tok prenosa podataka i upravljanja kod mailbox-a je prikazan na slici 2.17.
Slika 2.17. Deoba informacije koristeći message-e i mailbox-ove
Često mailbox se implementira pomoću reda čekanja koji u ovom slučaju ima ulogu kontejnera za podatke. Kod osnovne impelmentacije dužina (obim) reda čekanja je 1. Operacija post napuni mailbox i sprečava (ne dozvoljava) dalje operacije post, sve dok se operacijom pend ne izbavi podatak i isprazni mailbox. 2.7.4 Poruke Kod metoda komunikacije između zadataka, o kojima smo do sada govorili, uglavnom se podrazumeva da postoji uzajamna saglasnost o tome preko kojih memorijskih oblasti se vrši razmena podataka. Današnje embedded aplikacije postaju sve više distribuirane, pa tim više potrebe za sinhronizacijom i razmenom informacije postaju sve izraženije. Da bi se obavila razmena, treba koristiti neki koncept zasnovan na radu sa mailbox-ovima. Koristeći pristup mailbox-a, podaci - sada nazvani poruka (message) - se predaju preko imenovanih mailbox-ova ili se predaju odredištu. Imenovani mailbox-ovi se usmeravaju sada ka određenoj adresi, tj. odredištu poruke. Poruke se mogu baferovati ali i ne mora na strani izvorišta poruke, odredišta poruke, ili na obe strane. Ovakva šema rada, po svom konceptu, i načinu realizacije, nije identična sa principom rada baziranim na deljivoj memoriji. Princip razmena informacija zasnovan na konceptu prenosa poruka često se naziva interprocess communication (IPC). IPC podržava dva tipa operacija: send i receive. Ove operacije su analogne operacijama pend i post koje se koriste kod mailbox-ova. Po analogiji poruke (messages) mogu biti fiksnog i promenljivog obima. Ako zadaci T0 i T1 žele da razmene informaciju, oni prvo mora da uspostave komunikacionu vezu (communication link), a nakon toga da predaju i primaju podatke.

Kao što smo ranije naglasili, sa povećanjem korišćenja FPGA baziranih mikroprocesorskih jezgara potrebe za komuniciranjem postaju sve izraženije. Pri tome, u zavisnosti od aplikacije komunikaciona veza se može ostvariti između procesora koji su locirani na istom čipu kao i između fizički geografski razdvojenih mikroprocesora između FPGA čipova smeštenih na štampanoj ploči. No, kada se govori o prenosu poruka, moraju prvo biti sagledani sledeći detalji:
- Na koji način se uspostavlja veza (link)? - Da li se vezi može pridružiti veći broj zadataka? - Koliko veza postoji između para zadataka? - Koliki je kapacitet veze, i da li postoje baferi? - Koliki je obim poruke? - Da li su veze jednosmerne (unidirekcione), ili dvosmerne (bidirekcione)?
Daćemo sada odgovor na nekoliko od ovih pitanja. Zadnja dva pitanja se uglavnom odnose na probleme koji prate umrežavanje i remote sisteme, a o njima smo pričali u predmetu Računarske mreže i interfejsi. Kada se razmatraju implementacioni metodi, moguće je napraviti izbor između:
• Direktne/indirektne komunikacije, • Simetrično/asimetrično adresiranje, • Auto ili ekspličitno baferovanje, • Slanje kopije ili obraćanje referenciranjem, • Fiksni ili promenljivi obim poruke.
2.7.4.1 Komunikacija Poruka (message) se može premeštati sa jednog mesta na drugo, direktno ili indirektno, preko neke međutačke ili tačaka. Svaki od ovih pristupa ima svoje prednosti i nedostatke. Direktna komunikacija Kada se koristi šema direktne komunikacije, svaki proces mora eksplicitno imenovati predajnik/prijemnik poruke. Logička forma poruke je sledeća: send (T1, message) // šalje poruku zadatku T1 receive (T0, message) // prima poruku od zadatka T0 U okviru procesa automatski se uspostavlja veza između svakog para procesa ili thread-ova. Za sistem koji ima četiri procesa, konfiguracija prikazana na slici 2.18 prezentuje potpune, bidirekcione veze između svih procesa.

Slika 2.18. Četiri potpuno povezana zadatka
Kod ovakve implementacije potrebno je sagledati nekoliko važnih aspekata:
• Individualni zadaci mogu ali ne moraju biti fizički raspoređeni. Jedan ekstremum predstavlja kada su oni locirani u okviru istog FPGA čipa, a drugi ako su oni raspoređeni na nekoliko različitih mesta, recimo zemalja.
• Potpuna povezanost ne predstavlja efikasan pristup za povezivanje većeg broja zadataka. Hijerarhijska šema kod koje je manji podskup zadataka međusobno povezan može biti efikasnija za implementaciju i upravljanje. Internet je jedan dobar primer takvog modela.
Kod korišćenja direktne komunikacione šeme, svaki zadatak treba da zna identitet drugog zadatka, tj. koja je veza pridružena između ta dva procesa. Veze mogu biti jednosmerne (unidirectional) ili dvosmerne (bidirectional). Razmena se može ilustrovati modifikovanim dijagramom toka podataka prikazanog na slici 2.19. Naglasimo da se svakom procesu pridružuje bafer, mada to ne mora da bude slučaj kod svih implementacija. Obično se bafer pridružuje U/I zadatku.
Slika 2.19. Razmena informacije između dva zadatka preko mreže
Primer 1 Neka je data skeletna struktura između dva zadatka - zadatak proizvođač T0 i zadatak potrošač T1. Zadatak T0 generiše podatke i smešta ih u bafer koga deli sa zadatkom za predaju (slanje). Zadatak koji predaje uzima podatke iz bafera, formira ih u poruku koju šalje zadatku T1 kao korisnu informaciju (payload) u okviru predate poruke (message). Aktivnosti koje se obavljaju od strane oba zadatka su prikazane prvo preko dijagrama aktivnosti datog na slici 2.20, a nakon toga preko dijagrama-sekvenciranja sa slike 2.21.

generiše stavku
predaja stavke
primi stavku
potroši stavku
proizvođač potrošač
Slika 2.20. Dijagram aktivnosti koji prikazuje trazmenu između proizvođača i potrošača
Slika 2.21. Dijagram sekvenciranja koji ilustruje razmenu između potrošača i proizvođača Konačno, deo (fragment) koda koji odražava operacije koje se obavljaju od strane oba zadatka je prikazan na slici 2.22. while(1) ..... produce stavku u nextB0 ..... send (T1, nextB0) ..... end while
while(1) ..... receive (T0, nextB1) ..... consume stavku u nextB1 ..... end while
Slika 2.22. Kodni fragment koji ilustruje razmenu između proizvođača i potrošača
Indirektna komunikacija Kod indirektne komunikacije poruke se predaju i primaju preko deljive promenljive, u opštem slučaju u formi mailbox-a. Jedan opšti oblik predaje i prijema je send (M0, message) // predaja poruke u mailbox M0 receive (M0, message) // prijem poruke iz mailbox-a M0 Veza se uspostavlja samo ako zadaci/thread-ovi imaju deljiv mailbox ili sličan kontejner. Veza može biti pridružena većem broju procesa, a između procesa može da postoji i veći broj

veza (link-ova). Kao i kod direktne šeme, veza može biti jednosmerna ili dvosmerna. Dijagram toka podataka kod koga dva zadatka indirektno razmenjuju informaciju je prikazan na slici 2.23. Sprežne veze su bidirekcione.
Slika 2.23. Indirektna razmena informacije između dva zadatka preko mreže koristeći deljivi
mailbox 2.7.4.2 Baferovanje Bafer ili baferi se mogu pridružiti svakoj vezi. Baferovanje obezbeđuje da se veći broj poruka može bezbedno slati po vezi, a da se pri tome one korektno prime od strane odredišta. Ako se poruka šalje suviše brzo, može da se desi da prijemnik nema dovoljno vremena da prihvati i procesira poruku pre nego što pristigne naredna. Postoje tri moguće šeme baferovanja:
• kapacitet veze je 0 - to znači da veza (link) nema mogućnost pamćenja poruka. Predajnik mora da sačeka, kako bi prijemnik prihvatio poruku pri čemu se čekanje realizuje uvođenjem kašnjenja ili korišćenjem procedure tipa handshake. Ova šema se naziva randezvous ili Idle RQ protokol.
• kapacitet veze je ograničen - svakoj vezi je pridružen red čekanja poruka obima n. Ako postoji prostor kada predajnik želi da preda, tada se message smešta u red čekanja, a predajnik produžava sa radom. Inače, predajnik mora da sačeka kako bi se oslobodio prostor u redu čekanja.
• veza ima neograničeni kapacitet - ovaj slučaj se može posmatrati kao kad je red čekanja neograničenog obima. U ovom slučaju predajnik post-uje message i produžava sa daljim radom. Ne postoji čekanje. Važno je naglasiti da u ovom slučaju treba prepopznati mehanizam kod koga predajnik ne mora da čeka. Ako prijemnik može da izbavi dolazeće podatke dovoljno brzo, i bafer obima 1 biće dovoljan. Ova šema se naziva Continous RQ protokol.
Svi pristupi koji se odnose na intertask komunikaciju, a o kojima smo do sada govorili, su prikazani na slici 2.24.

Slika 2.24. Alternativni pristupi za intertask komunikaciju
2.8 Saradnja između zadataka, sinhronizacija, i deoba Pored deobe informacija, zadaci kod multitasking sistema ili procesora u miltiprocesorskom sistemu su često u toku izvršenja aplikacije zaduženi i za međusobnu kooperaciju/sinhronizaciju u radu. Zadaci/thread-ovi ili procesori koji međusobno kooperišu mogu uticati na rad drugih procesa/thread-ova ili procesora, ili da na njihov rad utiču upravo ti drugi zadaci/thread-ovi ili procesori. Oni mogu direktno deliti logički adresni prostor (kako podatke tako i kôd) ili da im se dozvoli da dele podatke koristeći bilo koji model koji manipuliše sa deljivim promenljivim koga smo već prethodno analizirali. Ovakav konkurentni pristup zajedničkim (common) podacima rezultira nekonzistentnostima u manipulisanju sa podacima, nenormalnom i neočekivanom ponašanju sistema, ili potencijalno može da dovede do greške u radu sistema. 2.8.1 Kritične sekcije i sinhronizacija Pretpostavimo da se dvoja kola kreću u suprotnim smerovima po uskom putu. Na mestu njihovog razmimolilaženja postoji jedan tesan most (slika 2.25) po kome u datom trenutku može da prođe samo jedno vozilo.

Slika 2.25. Kritična sekcija Slika 2.26. Deljiva promenljiva kritične sekcije Ako se svako vozilo modelira kao proces, a most predstavlja deljivi resurs, problem se može predstaviti dijagramom toka podataka sa slike 2.26. Jedno od mogućih rešenja problema kojim se kontroliše pristup mostu je da se postavi kamen na ivici mosta. Kada se kola približe mostu i žele da ga pređu, neophodno je prvo da se kola zaustave, uoči gde se nalazi kamen, vozač uzme, pređe most, i nakon toga stavi kamen na drugu stranu mosta. Ako nema kamena kola moraju da čekaju. Naravno, da bi ovo rešenje bilo ostvarivo, potrebno je učiniti sledeće pretpostavke. Prva je sledeća: Koliko dugo kamen može da se zadrži, i šta će se desiti ako onaj koji ga je uzeo ne vrati ga. Druga se odnosi na sledeće: Dva vozila ne pristižu istovremeno pa onaj koji je prvi naišao proceni da može da pređe most, alil negde pri kraju naiđe na drugo vozilo koje se nalazi na mostu. Naravno da su moguća i druga scenarija koja dovode do zakrčenja saobraćaja. Dijagram toka podataka sa slike 2.26 se može sada proširiti, kako je to prikazano na slici 2.27, sa ciljem da se uspešno reši problem prelaska preko mosta.
Slika 2.27. Uvođenje kontrole radi upravljanja kritičnom sekcijom
Ispitajmo prvo na koji se način konkurentni pristup deljivom resursu može manifestovati u dizajnu. Posmatrajmo problem koji se javlja u priloženom pseudo-kôdnom fragmentu (odnosi se na sliku 2.30). U konkretnom slučaju je implementiran jednostavni prenos podataka između dva zadatka. Jedan zadatak ima ulogu proizvođača, a drugi potrošača, dok se razmena podataka između njih obavlja preko deljivog bafera. Bafer ima ograničeni kapacitet od n stavki. Prenos mora biti tako organizovan da proizvođač ne pokušava da smešta podatke u pun bafer, a potrošač da čita podatke kada je bafer prazan. Promenljiva counter predstavlja merilo koje ukazuje na to kkoliki je broj stavki u baferu. Ona se inkrementira kada se stavka dodaje, a dekrementira kada se izbavlja iz bafera. Dijagram toka podataka za deljivi bafer je prikazan na slici 2.28.
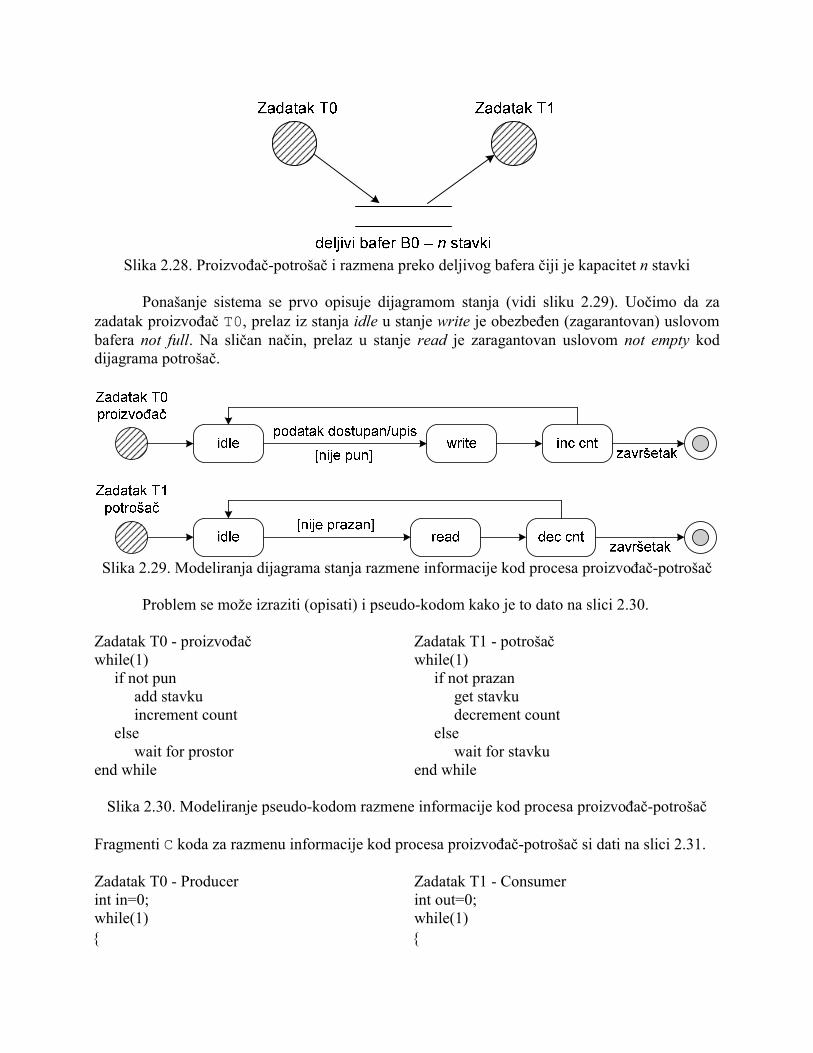
Slika 2.28. Proizvođač-potrošač i razmena preko deljivog bafera čiji je kapacitet n stavki
Ponašanje sistema se prvo opisuje dijagramom stanja (vidi sliku 2.29). Uočimo da za zadatak proizvođač T0, prelaz iz stanja idle u stanje write je obezbeđen (zagarantovan) uslovom bafera not full. Na sličan način, prelaz u stanje read je zaragantovan uslovom not empty kod dijagrama potrošač.
Slika 2.29. Modeliranja dijagrama stanja razmene informacije kod procesa proizvođač-potrošač
Problem se može izraziti (opisati) i pseudo-kodom kako je to dato na slici 2.30. Zadatak T0 - proizvođač while(1) if not pun add stavku increment count else wait for prostor end while
Zadatak T1 - potrošač while(1) if not prazan get stavku decrement count else wait for stavku end while
Slika 2.30. Modeliranje pseudo-kodom razmene informacije kod procesa proizvođač-potrošač
Fragmenti C koda za razmenu informacije kod procesa proizvođač-potrošač si dati na slici 2.31. Zadatak T0 - Producer int in=0; while(1) {
Zadatak T1 - Consumer int out=0; while(1) {

// produce stavku nextT0 // čekaj na slobodno mesto while (count==MAXSIZE); B0[in]=nextT0; in=(in+1)%MAXSIZE; count++; }
while (count==0); // čekaj na stavku nextT1= B0[out]; ount=(out+1) %MAXSIZE); count--; // consume stavku nextT0 }
Slika 2.31. C kôdni fragment koji modelira razmenu informacije kod procesa proizvođač-
potrošač Kao i kod pokušaja istovremenog pristupa mostu (slika 2.25) i u ovom slučaju postoji potencijalni problem koji egzistira zbog istovremenog pristupa promenljivoj count. Vrednost promenljive count zavisi od toga koji joj zadatak pristupa i u kakvom redosledu. S obzirom da se oba zadatka izvršavaju asinhrono, promenljiva, u bilo kom trenutku, može da ima jednu od sledećih triju različitih vrednosti (pozitivan broj, negativan, ili nula). Kao i kod mosta, count predstavlja kritičan deo podataka ili kritičnu sekciju koja je deljiva između oba procesa, T0 i T1. U opštem slučaju, kritična sekcija je resurs koga mogu da dele nekoliko zadataka kakav je U/I port ili memorijski segment u koji zadaci upisuju ili iz koga čitaju deljive promenljive. Deljive promenljive mogu imati jednostavnu formu kakva je single bit ili složene forme kakvi su fajlovi ili tabele. Kakav je bio slučaj sa prelaskom mosta (Slika 2.25) kada neki proces manipuliše sa delom podataka ili nekim drugim resursom u kritičnoj sekciji, i u ovom slučaju neophodno je da se zabrani pristup svim ostalim procesima koji pristupaju tom resursu. Drugim rečima, potrebno je ostvariti uzajamno-isključivi pristup (mutually exclusive access). Potreba da se kontroliše pristup deljivom (shared) resursu ili deljivim (common) podacima nameće potrebu za uvodjenjem sinhronizacije procesa ili procesora koju nazivamo mutual exclusion synchronization - uzajamno isključiva sinhronizacija- . Drugi oblik sinhronizacije naziva se uslovna-sinhronizacija (condition synchronization). Kod uzajamno isključive sinhronizacije cilj je obezbediti da se dva procesa istovremeno ne nađu u njihovoj zajedničkoj kritičnoj sekciji. Uslovna sinhronizacija, sa druge strane, uslovljava da se proces zakasni (odgodi) ili blokira sve dok je specificirani uslov true (ili false). Potreba da se deli i koordiniše pristup egzistira samo ako postoji više od jedan zadatak ili procesor koji želi da koristi deljivi resurs ili da istovremeno modifikuje zajedničke podatke (obavlja operaciju write nad deljivim resursom). Ovo je vrlo važan zaključak (aspekt). Kada je resurs deljiv, a zadaci obavljaju nad njim samo operacije tipa Read tada do problema u radu zadataka ne dolazi (operacija read nije destruktivna, tj. ne menja sadržaj promenljive). Kao i kod šeme pristupa mostu (slika 2.25), rešenje problema pristupa kritičnoj sekciji zahteva da se koristi (primeni) neki upravljački algoritam ili protokol kojim se reguliše pristup deljivoj oblasti. Na visokom nivou upravljanja, protokol treba da je takav da zadatak koji želi da pristupi kritičnoj sekciji vrši proveru sa ciljem da ustanovi da li neki drugi zadatak koristi promenljivu. Za slučaj da je ne koristi on oglašava svim ostalim zadacima da će on biti taj koji će koristiti promenljivu, nakon toga obavlja svoj posao, i na kraju ukazuje svim zadacima da je završio svoj posao. Jedan apstraktni model strukture zadatka sa kritičnom sekcijom se može opisati kako je to prikazano na slici 2.32.

while(1) nekritični kod ulazna sekcija kritična
sekcija
izlazna sekcija nekritični kod
Slika 2.32. Apstraktni model kritične sekcije
Kôd koji je relevantan za kritičnu sekciju nalazi se između ulazne sekcije (entry section) i izlazne sekcije (exit section). Ulazna sekcija se ponaša kao čuvar i obezbeđuje kontrolisani pristup kritičnoj sekciji. Izlazna sekcija se koristi da ukaže ostalim zadacima da je zadatak završio sa modifikacijom kritične promenljive. Bilo koje rešenje koje se odnosi na problem pristupa kritičnoj sekciji mora da zadovolji sledeće zahteve:
1. mora da obezbedi mutual exclusion u kritičnoj regiji (oblasti) 2. mora da osigura da ne dođe do samrtnog-zagrljaja (deadlock). Ako dva ili veći broj
zadataka pokuša da uđe u kritičnu sekciju, samo jedan može da nastavi. 3. mora da obezbedi progres (napredovanje u izvršenju) u kritičnoj sekciji. Kada nema
zadatka u kritičnoj sekciji, a neki od zadataka želi da uđe, samo zadaci koji nisu u delu izlazne sekcije (slika 2.32) mogu uticati na to koji će zadatak kao naredni ući u kritičnu sekciju. Šta više, zadatku koji želi da uđe u kritičnu sekciju ne može se ta namera zabraniti na beskonačno dug period.
4. rešenje mora da osigura ograničeno čekanje (bonded waiting).
Pri ovome, gornja granica, kao vrednost, se mora dodeliti promenljivoj koja vodi evidenciju o broju puta za koji se izvršenje zadatka sa najnižim prioritetom može blokirati, u slučaju kada se javi zahtev za izvršenjem zadatka čiji je prioritet viši. Analizirajmo sada nekoliko mogućih rešenja problema koji prate problem kritične sekcije. Počećemo sa flag baziranim pristupom, ali pre nego što se upustimo u analizu upoznaćemo se sa terminom atomic koji se koristi kao kvantifikator operacije. Atomska operacija je ona operacija za koju se garantuje da će se završiti. To znači da je ona nedeljiva operacija sa tačke gledišta testiranja i modifikacije stanja promenljive kojoj se pristupa. Pojam nedeljiva operacija se odnosi na sledeće: Nakon startovanja, operacija se izvodi (realizuje) do njenog kraja bez prekidanja. Sa aspekta grubo-zrnaste strukture upravljanja ova operacija se ponaša kao jedinstveni iskaz, dok sa tačke gledišta sitno-zrnaste strukture upravljanja operaciju čini nekoliko nedeljivih koraka kakvi su čitanje-modifikacija-upis. To znači da sekvenca koraka ne sme da se prekida sve do njenog završetka.

2.8.2 Flag-ovi Da bi se zaštitila kritična sekcija neophodno je obezbediti mutual exclusive pristup. Isključivost (exclusion) se ostvaruje koristeći markere (flags) koji se ugrađuju u atomske operacije. Ovaj metod ilustrovaćemo koristeći dva markera i dva procesa. Proširenje na veći broj procesa se može logički izvesti. Neka su T0 i T1 dva procesa koji dele kritičnu sekciju. Definišimo dva Boole-ova markera T0Flag i T1Flag, koji označavaju koji se od procesa nalazi u kritičnoj sekciji. Konačno, definišimo atomsku operaciju, await, čiji je pseudo-kôd prikazan na slici 2.33.
await (uslov) {
iskazi } varijabla
Slika 2.33. Pseudo-kod model iskaza await
Uslov je Boole-ov izraz kod koga zadatak, thread, ili procesor čeka sve dok se ne proceni da je isti true. Iskazi se odnose na skup akcija koje se moraju obaviti kada se proceni da je uslov true. Kada se proceni da je uslov true, izvršenje produžava iskazima koji čine telo konstrukcije await. Važna pretpostavka koja je učinjena ovde je ta da kada proces čeka (awaiting) na uslov, drugi procesi imaju mogućnost da se izvršavaju. Inače dolazi do samrtnog zagrljaja (deadlock). Koristeći operaciju await, moguće je sada preispitati problem deljivi-bafer o kome smo prethodno govorili.. Za svaki zadatak iskazi await su oblika await (!T1Flag){T0Flag=true;} await (!T0Flag){T1Flag=true;} U suštini, iskazi await se koriste za upravljanje pristupom kritičnoj sekciji - promenljiva count. Prvo ćemo sagledati zadatak proizvođač (producer) - vidi sliku 2.34a). Task T0 - Producer int in=0; while(1) { // proizvedi stavku nextT0 while (count==n); // čekanje B0[in]=nextT0; in=(n+1)%n; await (!T1Flag){T0Flag=true;} // ulazna (entry) sekcija count++; // kritična sekcija T0Flag=false; // izlazna (exit) sekcija }

Slika 2.34a) Upravljanje kritičnom sekcijom koristeći await iskaz na strani proizvođača Na strani potrošača (consumer) imaćemo - vidi sliku 2.34b) Task T0 - Consumer int out=0; while(1) { while (count==n); // čekanje nextT1=B0[out]; out=(out+1)%n; await (!T0Flag){T1Flag=true;} // ulazna (entry) sekcija count--; // kritična sekcija T1Flag=false; // izlazna (exit) sekcija // potroši stavku nextT1 } Slika 2.34b) Upravljanje kritičnom sekcijom koristeći await iskaz na strani potrošača 2.8.3 Token passing Jedno drugo moguće rešenje koje se odnosi na problem deljivi bafer, a predstavlja proširenje rock-passing (prenos kamena) protokola preko mosta je definicija flag-a ili token-a. Da bi se ostvsrila deljivost podataka koristi se samo jedan token (znak). Token se neprekidno prenosi od jednog zadatka do drugog, a svaki zadatak koji čeka na pristup kritičnoj sekciji može da pristupi toj sekciji samo kada poseduje token (vidi sliku 2.35). Prenos iz stanja A u stanje B, iz kojeg se pristup deljivim podacima može ostvariti, ostvaruje se zahtevom za posedovanjem u vlasništvo token-a.
Slika 2.35. Dijagram stanja koji modelira token-passing protokol kao rešenje za problem kritične sekcije
I pored toga što kod ovog rešenja postoji kontrolisani pristup kritičnoj sekciji, ipak se javljaju nekoliko problema: 1) zadatak ili procesor koji ne želi da deli podatke može zauvek (trajno) da zadrži token. 2) zadatak ili procesor koji čuva token može za duži vremenski period da bude neoperativan. 3) zbog raznih smetnji (šum) token može da se izgubi. 4) zadatak ili proces kod koga je token može da završi ili napusti sistem bez da preda (oslobodi se) token. 5) kako će se identifikovati novi zadatak ili procesor koji se pridružuje sistemu?

Jedna od mogućih ideja za rešavanje svih ovih problema se ogleda u pozajmljivan ju ideje koju koriste projektanti računarskih mreža. U sistem se uvodi zadatak, na sistemskom nivou, čiji je glavni posao da upravlja token-om. Ovaj zadatak ima ugrađen watchdog tajmer. Svaki put kada se neki zadatak oslobodi token tajmer se resetuje. Ako vreme tajmera istekne šalje se ping poruka svim zadacima ili procesorima kojom se pita za token (u smislu koji je trenutni vlasnik token-a). Za slučaj da niko ne odgovori, generiše se novi token. I sledeća ideja je pozajmljena od projektanata računarskih mreža: Svaki put kada zadatak ili procesor uđe, ili napusti sistem, on mora da se registruje token management zadatku. Alternativno, sistemski-zadatak može periodično da pita da li postoji neki novi zadatak ili procesor koji je ušao u sistem. Evidentno je da ovakav protokol ispunjava sve zahteve (stavke 1-5) o kojima smo govorili i rešava problem kritične sekcije. Ovakav pristup, na žalost, unosi intra- i inter-sistemsku komunikaciju kao i dodatni overhead za svaki zadatak što može biti posebno kritično za rad kod HRTS-a. 2.8.4 Prekidi Još jedan novi pristup koji se odnosi na rešavanje problema sa deljivim baferom bazira se na konceptu upravljanaj prekidima. S obzirom da se problem deljivog bafera javlja kod single-procesor konteksta kada je istiskivanje (preemptive) dozvoljeno, zabranom istiskivanja ovaj problem se može rešiti. Ipak, zabrana svih istiskivanja, u najvećem broju slučajeva, može da predstavlja suviše ekstremno rešenje. Zbog ovoga, jedan fleksibilniji pristup treba da predstavlja rešenje za ovaj problem. Ako se prisetimo ranijih rešenja koja opisuju ponašanja zadataka u kritičnoj sekciji, tada se problem može rešiti ako se prekidi zabrane kada se uđe u oblast entry sekcija (vidi sliku 2.32), i ponovo dozvole u sekciji exit. Koristeći ovakav pristup susrećemo se sa istim problemima sa kojima smo se suočavali kod token-based metoda. Konkretnije, ako zadatak u svojoj kritičnoj oblasti implementira neku vremenski dužu ili beskonačnu petlju, tada će prekudi biti zabranjeni za duži period. Problem se može rešiti korišćenjem sličnih varijanti rešenja koja su razvijena kod token-based šeme. Umesto, kada se uđe u entry kodni segment (vidi sliku 2.32), da se zabrane prekidi, brane se ili se maskiraju samo oni prekidi čiji je nivo prioriteta niži od specificiranog. Da bi sistem korektno radio, omogućava se tajmeru da generiše prekid čiji je nivo viši u odnosu na zabranjeni ili maskirani. Kada vreme tajmera istekne, sistem može da istisne izvršenje tekućeg zadatka. Sada ponovo, problem deljivog bafera baziran na pristupu mprekida zadovoljava zahteve koji se tiču problema pristupa kritičnoj sekciji. Jedina teškoća je ta što ovaj pristup nije efikasan kod multiprocesorskih rešenja koja koriste deljivu memoriju jer jedino postoji mogućnost da se upravlja prekidima (brane i dozvoljavaju) samo na nivou svog sopstvenog procesora, a ne i da se brane i dozvoljavaju prekidi drugih procesora. 2.8.5 Semafori Semafor je protokol koji se koristi za zaštitu pristupa kritičnoj sekciji, a predložen je od strane Prof. E. W. Dijkstra iz Holandije. U svojoj najjednostavnijoj formi, semafor je Boole-ova

promenčljiva ili celobrojna vrednost, S. Promenljivoj se može pristupati samo preko sledeće dve atomic operacije:
wait - p(S) signal - v(S)
Slova p i v su prva slova holandskih reči proberen, što znači test, i verhogen što znači inkrement. Vrednost semafora ukazuje da li je dozvoljen ili nije dozvoljen pristup kritičnoj promenljivoj. Reč atomic ukazuje da je operacija pristupa semaforu važna i nedeljiva. Operacija wait testira vrednost semafora, i ako je on false, postavlja ga na true. Operacija signal postavlja vrednost na false. Operacija wait obavlja svoju aktivnost u sledeća dva koraka: test, a nakon toga set. Ova dva koraka vide se spolja gledanmo u odnosu na wait, kao jedinstvena atomic operacija. Sekvenca događaja prikazana na slici 2.36 ne bi trebalo da je moguća. U datoj situaciji, izvršavaju se oba zadatka, T0 i T1. T0 tekuće upravlja radom CPU-a i treba da uđe u kritičnu sekciju. On izvršava wait. Za slučaj da test i set operacija nije atomic, T0 može da kompletira test deo koda i da ustanovi da je resurs dostupan. Neka u međuvremenu, zadatak T1, čiji je prioritet viši, prekine rad procesora (interrupts) i zahteva dodelu resursa. On takođe izvršava wait, sve do završetka. Zadatak T1 zatim izlazi iz prekidne rutine, a T0 nastavlja sa radom gde je bio prekinut i postavlja marker. Oba procesa sada veruju da imaju uzajamno isključivi pristup kritičnoj oblasti. Sve dok ni jedan od zadatak ne promeni vrednost kritične promneljive sistem će se ponašati po očekivanju. Ipak, operacija write od strane bilo kog zadatka može potencijalno da kreira seriozan problem. Operacije koje manipulišu semaforom se mogu definisati kao kodni fragmenti. (vidi sliku 2.37). Uočimo sličnosti u odnosu na operaciju await.
Slika 2.36. Ne-atomski model Flag-a koji se koristi da zaštiti kritičnu sekciju
wait(s) { while(s); a=True; } s inicijaliziran na FALSE
signal(s) { s= FALSE; }

Slika 2.37. Model ponašanja semafora
Treba imati u vidu da sa await upravljačkim iskazom, i pored toga što je prikazan u nekoliko koraka, operacija wait mora da se izvrši kao jedinstvena (single) atomic operacija. Čitalac zaključuje da se znak ";" odnosi na neku grešku, alli u suštini to nije. Ovakva konstrukcija uslovljava blokadu zadatka sve dok se ne postavi semafor. Operacije test i set (skraćeno u različitim tekstovima se sreću kao TS, TAS, ili TNS) a implementiraju se od strane hardverskih instrukcija kod velikog broja procesora. Semafor se može sada koristiti da zaštiti kritični resurs kao što je prikazano u sledeća dva kodna fragmenta na slici 2.38. Zadatak koji izvršava wait(S) prvi dobiće pravo pristupa kritičnoj sekciji. Drugi zadatak biće blokiran, čekajući da prvi zadatak izvrši signal. S toga, on će takođe, moći biti prosleđen za procesiranje.
Task T0 { ...... wait(s) kritična sekcija signal(s) ...... }
Task T1 { ...... wait(s) kritična sekcija signal(s) ...... }
Slika 2.38. Zaštita kritične sekcije sa semaforom
2.8.6 Sinhronizacija procesa Moguće je koristiti semafor na neznatno drugačiji način kako bi forsirali redosled izvršenja nekoliko asinhronih zadataka. U tom smislu razmotrimo aplikaciju koju čine dva zadatka, T0 i T1, a koji međusobno sarađuju u delu aplikacije. Zadatak T0 sadrži funkciju f(s0), dok zadatak T1 funkciju g(s1). Njihov rfedosled izvršenja je kritičan; funkcija f(s0) mora da se izvrši pre g(s1). Da bi ostvarili ovakvu sinhronizaciju definisaćemo semafor sync i inicijalizirati ga na vrednost TRUE. Kodni fragment prikazan na slici 2.39 prikazuje ovaj dizajn. Naglasimo da, pošto je sync inicijaliziran na TRUE, zadatak T1 izvršiće g(s2) samo pošto je T0 izvršio iskaz f(s1).
Task T0 { ...... f(s1) signal(sync; //signaliziraj ...... }
Task T1 { ...... wait(sync); // čekaj g(s2) ...... }

Slika 2.39. Korišćenje semafora radi upravljanja redosledom izvršenja
2.8.7 Spin Lock i Busy Waiting Jedini nedostatak korišćenja semafora za potrebe sinhronizacije je taj što kada se izvršava wait nad deljivim resursom ili objektom, proces koji obavlja wait mora da se kontinualno izvršava u petlji dok čeka. Ovaj fenomen se naziva busy waiting. Pod ovakvim uslovom, procesi koji čekaju, troše CPU-ove cikluse koje drugi procesi mogu produktivnije da koriste. Zaključavanje (lock) u kritičnoj sekciji naziva se spin lock jer se proces stalno vrti (spins) čekajući da se brava otključa (lock to open). Prednost zaključavanja je ta što ne postoji kontekst komutacija za koju CPU troši značajno vreme. Ako se za zaključavanje očekuje da će se obaviti za kratak vremenski interval, tada korišćenje spin lock-a postaje posebno korisno kod vremensko kritičnih situacija. 2.8.8 Brojački semafori Semafori o kojima smo do sada govorili se nazivaju binarni semafori; oni mogu uzimati samo jednu od dve vrednosti. Ova definicija se može proširiti na taj način što će omogućiti semaforu da uzima vrednosti u opsegu od 0 do N-1. Ovakav semafor nazivamo brojački semafor (counting semaphore). Svakom ovakvom semaforu je dodeljena celobrojna vrednost i (potencijalna) lista pridruženih procesa. Kada proces izvršava wait operaciju, a semafor nije dostupan, umesto da čeka, proces može sam sebe da blokira (block itself). Preko block operacije, proces samog sebe smešta u waiting-red-čekanja koji se pridružuje semaforu. Stanje procesa se menja na waiting, i upravljanje se prenosi scheduler-u. Blokirani proces se može restartovati kada neki drugi zadatak izvrši operaciju signal. Operacija restart se inicira od strane wakeup operacije koja postavlja zadatak u stanje ready i smešta ga u red-čekanja ready. Brojački semafor može biti posebno koristan kada treba da se upravlja radom pool-a (skupa) identičnih resursa. Definicija rada ovog semafora je neznatno modifikovana, kao što se vidi iz kodnog fragmenta prikazanog na slici 2.40. No, nezavisno od svega, modelirana operacija semafora i dalje ostaje atomic tipa. Semafor s koji se sada definiše inicijalizira se na vrednost 0.
wait(s) { s=s+1; if(s>1) { dodaj proces u waiting queue; block; } }
signal(s) { s=s-1; if(s>1) { izbavi proces iz waiting queue; wakeup(p); } }
Slika 2.40. Kodni fragment koji modelira brojački semafor

Naglasimo da operacija block suspenduej pozivni (invoking) proces dok wakeup (buđenje) nastavljla izvršenje blokiranog procesa. Obe operacije se obavljaju (ostvaruju se) kao OS call-ovi. Uočimo da se waiting lista može implementirati kao povezana (linked) lilsta i verovatno implementirati kao FIFO ili prioritetni-red-čekanja. 2.9 Primena koncepata Do sada smo diskutirali o problemima koji se odnose na deobu, kooperaciju, i sinhronizaciju između zadataka. Analiziraćemo sada jednu aplikaciiju koja koristi ove koncepte. 2.9.1 Problem ograničenog bafera Prvo, opisaćemo cilj. Jedan od glavnih ciljeva kod projektovanja embedded aplikacija ogleda se u tome što one na jedan robustan način treba da tolerišu greške i pogrešno korišćenje (manipulaciju) uređaja. U tom smislu, analiziraćemo sledeći problem. Primer 2.1 Aplikacija se odnosi na realizaciju dela sistema za upravljanje tokom i manipulisanjem podacima jednog proširljivog sistema za digitalizaciju slike koga treba ugrađivati u robote. Sistem će biti korišćen za ispitivanje konfiguracije i osobine tla neistraženih oblasti. Cilj ispitivanja je da se sprovede niz detaljnih studija sa lica mesta neistražene oblasti. Sistem čini nekoliko kamera koje kolektivno skupljaju različite podatke o slici. Podaci se mogu odnositi na infracrvenu analizu, analizu atmosfere, ili topografske mape. Kamerni sistem (imaging system) je montiran na robotu. Podaci se prikupljaju u bafer i nakon toga prenose u lokalni centar, koji prenosi slike jednu za drugom (sekvencijalno) ka udaljenim dispečerskim centrima (može ih biti više). S obzirom da se u toku svake misije u fazi prikupljanja podataka iz okruženja neistražene oblasti pribavlja što je moguće više podataka, podaci se umesto u jedan veliki bafer prikupljaju u n manjih bafera. Kod ovakve šeme, ne dolazi do čekanja kako bi se jedan bafer ispraznio pre nego što počne ponovna analiza slike, čime se maksimizira prenos na obe strane (kamera sa jedne i lokalni centar sa druge strane). To znači da kada se bafer napuni podaci o prikupljenoj slici se usmeravaju ka narednom slobodnom baferu. Za slučaj da se prekine komunikaciona veza između lokalnog centra i jedan od udaljenih dispečerskih centara, tu informaciju će primiti drugi dispečerski centar i biće u stanju da je procesira. Blok dijagram dela sistema je prikazan na slici 2.41.
Slika 2.41. Korišćenje deljive informacije kod dizajna baziranog na baferima

Da bi rešili problem prvo se moraju identifikovati esenciijalni zahtevi. Postoje sledeće dve stavke sa kojima treba upravljati:
• vođenje evidencije o broju slobodnih/punih bafera; i • kontrolisati pristup specifičnom baferu radi čitanja i upisa podataka o slici.
Nakon ovoga treba pristupiti rešavanju problema. Imaging system je proizvođač (producer), a lokalni centar je potrošač (consumer). Za specifikaciju promenljivih koje ukazuju na broj punih ili praznih bafera, a shodno tome i pristup tim baferima, koriste se semafori. S toga, na početku definisaćemo sledeće semafore: mutex - obezbeđuje mutual exclusion pool-u (skupu) bafera - inicijalizira se na vrednost 1 empty - vodi evidenciju o broju praznih bafera - inicijalizira se na vrednost n-1 full - ukazuje na broj punioh bafera - inicijalizira se na nula. Algoritam radi na sledeći način. Producer proverava kako bi ustanovio da li postoje prazni bafera, i za slučaj da postoje, čeka na isključivi pristup (exclusive access) skupu (pool-u) bafera. Nakon dobijanja prava pristupa, producer unosi podatke, i zatim napušta tu aktivnost. Na strani consumer-a, consumer proverava da li postoji neki bafer sa dostupnim podacima, i za slučaj da postoji on čeka na exclusive access. Kada se bafer-pool otvori, consumer prihvata podatke i nakon toga napušta tu aktivnost. Kodni fragment producer-a je prikazan na slici 2.42, a consumer-a na slici 2.43. Problem koga smo opisali predstavlja klasičan problem poznat kao Bounded Buffer problem. Task0 - Producer while(1) ....... produce stavku T0stavka ..... wait(empty); // čekanje na dostupni bafer wait(mutex); // bafer dostupan čekanj na ....... // exclusive access pool-u bafera add T0stavku u bafer; // kopiraj sliku podataka u bafer ....... signal(mutex); // signalizacija da je pool-bafera dostupan signal(full); // signalizacija dasu podaci dostupni ....... end while Slika 2.42. Rešenje problema Bounded Buffer na strani producer-a

Task1 - Consumer while(1) wait(full); // čekaj da podaci postanu dostupni wait(mutex); // čekaj na exclusive access pool-u bafera ....... remove T1stavku iz bafera; // izbavi podatke o slici ....... signal(mutex); // signalizacija da je pool-bafera dostupan signal(empty); // signaliziraj čitanje podataka ....... // exclusive access pool-u bafera consume stavku T1stavka // iskoristi podatke o slici ....... end while Slika 2.43. Rešenje problema Bounded Buffer na strani consumer-a 2.9.3 Problem Readers and Writers Mladi inženjer u projektantskom timu je predložio sledeće: Pošto postoji veći broj bafera, imaging sistem se može poboljšati ako se omogući istovremeno prikupljanje podataka od većeg broja kamera i njihovo memorisanje u jedan od bafera. Takođe, podaci se mogu puniti koristeći nekoliko veza (linkova) sa ciljem da se ubrza taj proces. Da bi demonstrirao rad inženjer je napravio jedan jednostavan model sistema. Rešenje radi dobro najvećim delom vremena, ali povremeno, dolazi do narušavanja a inženjer ne razume zašto se to dešava. Predloženi dizajn ukazuje na jedan od klasičnih problema. Postoji objekat podataka koji mora biti deljiv između većeg broja konkurentnih procesa. Neki od procesa mogu da čitaju (upload) a drugi da upisuju (store), pa se zbog toga ovi procesi nazivaju readers and writers. U toku rada, ako veći broj procesa readers pristupa podacima simultano do problema u radu ne dolazi iz razloga što je operacija Read nedestruktivna, tj. da li će podatke iz bafera prvo čitati proces A ili proces B je potpuno svejedno iz razloga što operacija Read ne menja sadržaj pročitanog podatka. No, u slučaju kada proces writer ili bilo koji drugi procesi simultano dele podatke, tada se potencijalno javlja jedan veliki problem. Ovaj problem se naziva readers-writers problem. Postoji nekoliko varijanti ovog problema, a to su:
• First Readers-Writers: nema reader-a da čeka ako je writer dobio (ostvario) pravo pristupa deljivoj promenljivoj
• Second Readers-Writers: ako je writer spreman, on obavlja operaciju write što je pre moguće. Ako je writer u stanju waiting, novi reader ne može startovati.
Sagledajmmo sada na koji način problem mladog inženjera može biti rešen. Predstavićemo rešenje koje se odnosi na problem first readers-writers. Da bi počeli sa analizom definisaćemo prvo sledeće pojmove (termine):

• Semafori - mutex, wrtSem - oba se inicijaliziraju na 1, • mutex - koristi se da obezbedi mutual exclusion kada se ažurira numReaders, • wrtSem - koristi se da obezbedi mutual exclusion za pristupe writer-a, • numReaders - celobrojna vrednost koja odgovara broju readers-a koji tekuće pristupaju
deljivom pool-bafera, inicijalizira se na 0. Svaki writer proces mora da proveri za exclusive access u pool-bafer pre nego što obavi upis (writing). Provera se ostvaruej zaštitom (by protection) pool-a pomoću semafora wrtSem. Kodni fragment za writer je prikazan na slici 2.44. Svim reader-ima koji žele da pristupe podacima je dozvoljen pristup, a ne i drugim procesima koji pristupaju pool-baferu radi promene vrednosti podataka. Kodni fragment reader-a je prikazan na slici 2.45. Uočimo da u entry sekciju kritične sekcije, ako entering zadatak nije samo reader, tada, mora da postoje i drugi readers-i. Ovaj uslov implicitno ukazuje da ne mogu da postoje bilo koji writers-i. Inače, mora da se proveri kako bi se obezbedili da ne postoje writers-i pre nego što se produži sa daljim radom. Ako writer nije u kritičnoj sekciji, n readers-a ga čeka, jedan reader je smešten u redu-čekanja uz pomoć wrtSem, dok n-1 readers-a su smeštena i red-čekanja pomoću mutex-a, a za slučaj da writer izvršava signal(wrtSem), on može da nastavi kao waiting readers ili waiting writer. Odluka se donosi od strane scheduler-a. Pretpostavku koju smo učinili je ta da baferi u kojih se upisuje ili iz kojih se čita u toku rada se upravljaju na takav način da ne dolazi ni do podbačaja (underflow) ni do premašaja (overflow). Writer Process wait(wrtSem); // čekaj da wrtSem=1 ...... // critical section obavi writing ..... signal(wrtSem); // wrtSem=1 ...... Slika 2.44. Problem First Readers and Writers - na strani writer-a Reader Process while(1) wait(mutex); // čekaj dok je mutex==1 // mutex=0 numReaders++; // inkrementiraj broj readers-a if(numReaders==1) // ako je samo jedan reader wait(wrtSem); // budi siguran da nema writers-a // wrtSem=1 endif signal(mutex); // mutex=0 // critical section

..... Perform reading; ...... wait(mutex); // čekaj za mutex==1 // mutex=0 numReaders--; // dekrementiraj broj readers-a if(numReaders==0) // nema readers-a signal(wrtSem); // wrtSem=0 endif signal(mutex); // mutex=0 ........ end while
Slika 2.45. Problem First Readers and Writers - na strani reader-a 2.10 Monitori Semafore koje smo do sada izučavali su fundamentalni metod za ostvarivanje sinhronizma u radu zadataka. Na žalost to su mehanizmi vrlo niskog nivoa i veoma je lako napraviti grešku kod njihovog korišćenja. Jedno alternativno rešenje koristi tip podataka nazvan monitor. Monitori su programski moduli koji nude veću struktuiranost u radu u odnosu na semafore, pa je zbog toga njihova implementacija efikasnija. Monitor je apstraktni mehanizam podataka koji enkapsulira prezentaciju apstraktnog objekta. On obezbeđuje public tip interfejsa kao jedino sredstvo pomoću koga se internim podacima može manipulisati. Naglasimo da je to slično kao klase kod C++ ili Java. Monitor sadrži internu (privatnu) promenljivu za memorisanje stanja objekata i procedura (metoda ili članova funkcije) koje implementiraju operacije nad objektom. Mutual exclusion je zadovoljena time što se obezbeđuje da se procedure u istom monitoru ne mogu izvršavati simultano. Uslovne sinhronizacije se ostvaruju preko condition variable. Monitor se koristi da grupiše prezentaciju i implementaciju deljivog resursa. On poseduje interface i body (telo). Interface (public tipa) specificira sve operacije koje se odnose na resurs, dok body sadrži promenljive koje se odnose na prezentaciju stanja resursa. Interne procedure implementiraju operacije koje su specificirane u interfejsu. Monitor se može šematski prikazati kao na slici 2.46. monitor monName { iskazi inicijalizacije procedure permanentne promenljive } Slika 2.46. Tipična struktura monitora Procedure implementiraju vidljive operacije. Svi procesi u monitoru dele permanentne promenljive. One se nazivaju permanentne jer zadržavaju svoje vrednosti na izlasku sve dok

monitor postoji. Ovakvo ponašanje je tipično za C ili C++ sa statičkim promenljivima. Procedure mogu takođe imati lokalne promenljive. Samo imena procedura su vidljiva van monitora - public interface. Permanentne promenljive se mogu jedino promeniti preko vidljivih procedura. Iskazi unutar monitora ne mogu imati efekat na promenljive koje se nalaze van monitora, što znači da imaju različit opseg delovanja (scope). Permanentne promenljive se inicijaliziraju pre nego što se pozovev bilo koja procedura. Inicijalizacija se ostvaruje izvršenjem inicijalizacionih procedura u trenutku kada se kreira instanca monitora. Glavna razlika između monitora i klase kod C ili Java je ta što je monitor deljliv za veći broj porcesa ili thread-ova koji se izvršavaju. Saglasno prethodnom, thread-ovi ili procesi koji koriste monitor mogu zahtevati mutual exclusion nad promenljivima monitora kao i da zahtevaju sinhronizaciju sa ciljem da obezbede da stanje monitora bude pogodno za produžetak izvršenja. Mutual exclusion je obično implicitna, dok se sinhronizacija implementira eksplicitno. Različiti procesi zahtevaju različite forme sinhronizacije. Implementacija neophodnbe sinhronizacije se ostvaruje preko condition variables. Eksterni zadatak ili thread poziva monitor proceduru. Procedura je active ako thread ili zadatak izvršava iskaz u proceduri. Najviše jedna instanca monitor procedure u datom trenutku je active. Simultani poziv dve procedure ili dva poziva iste procedure nije dozvoljen. Po definiciji procedura se izvršava sa mutual exclusion što se ostvaruje korišćenjem jezičkih bibliotečnih funkcija ili pozivom OS-a. Mutual exclusion se obično implementira korišćenjem lock-ova (zaključavanja) ili semafora i zabranom rada određenih prekida. 2.10.1 Uslovne promenljive Uslovne promenljive (condition variables) se koriste kao deo procesa sinhronizacije, i namenjene su da zakasne zadatak ili thread koji ne može bezbedno da produži sve dok stanje monitora ne zadovolji određeni Boole-ov uslov. Naglasimo da su uslovne promenljive slične guard uslovima kod UML dijagrama stanja. One se zbog toga koriste da pobude zakašnjeni proces nakon što uslov postane true. Uslovna promenljiva je instanca promenljive tipa cond cond myCondVar Deklaracija može biti samo unutar monitora. Vrednost uslovne promenljive odgovara redu čekanja zakašnjenih procesa. Inicijalno red čekanja je prazan. Vrednošću u redu čekanja se može samo indirektno pristupiti, kao na primer, da bi se testiralo njegovo stanje empty (myCondVar); Thread može da blokira uslovnu promenljivu: wait (myCondVar);

Izvršenje wait-a uzrokuje da se zadatak kopira na kraju reda čekanja i da oslobodu exclusive pristup monitoru. Blokirani proces se budi koristeći signal (myCondVar); Izvršenjem signal uzrokuje da se probudi zadatak sa zaglavlja reda čekanja. Uočimo da izvršenjem signal-a može da dovede do dileme. Nakon izvršenja, dva zadatka imaju mogućnost da se izvrše: probuđeni zadatak i signaling zadatak. Ovakva situacija može biti kontradiktorna sa zahtevom da samo jedan zadatak ili thread mogu istovremeno biti aktivni u monitoru. Za rešavanje ovog problema se koriste sledeća dva načina:
• Signal and Contunue - signaling zadatak produžava, dok probuđeni zadatak nastavlja sa radom nešto kasnije. Za ovu šemu smatramo da je non-preemptive, jer proces koji izvršava signal zadržava isključivo pravo upravljanja nad monitorom.
• Signal and Wait - smatra se da je preemptive. Zadatak koji izvršava signal prepušta upravljanje i predaje lock uspavanom zadatku. Probuđeni proces istiskuje signaling proces.
Proces je opisan na slici 2.47.
Slika 2.47. Model dijagrama stanja za monitor
Rad/sinhronizacija se dešava na sledeći način. Zadatak call (poziva) monitor proceduru. Ako se drugi zadatak izvršava u monitoru, pozivni zadatak se smešta u entry queue. Kada monitor postane slobodan, kao rezultat return ili wait, tada jedan zadatak se premešta iz entry queue u monitor. Ako ne postoje drugi zadaci koji se izvršavaju, zadatak koji je obavio poziv prolazi preko entry queue i odmah počinje sa izvršenjem. Ako zadatak dok izvršava monitor obavlja wait na condition variable on ulazi u red čekanja pridružen toj promenljivoj. Kada zadatak izvršava Signal and Continue nad condition variable zadatak na zaglavlju pridruženog reda čekanja se kopira u entry queue. Ako zadatak izvršava Signal and Wait nad condition variable tada zadatak sa zaglavlja pridruženog reda

čekanja se kopira u monitor, a zadatak koji se izvršava u monitoru se premešta u entry queue. 2.10.2 Problem ograničeni-bafer sa monitorom Analizirajmo sada problem ograničenog bafera i implementirajmo dizajn koristeći monitor. Usvojićemo da svaki zadatak čuva po jednu stavku. Definišimo monitor kao boundedBuffer Definišimo sledeće condition variable-e notEmpty signalizira kada je brojač bafera > 0 sledi stanje praznih bafera, inicijalizira se na 0 notFull signalizira kada je brojač bafera <n-1 sledi trag full bafera, inicijalizira se na 0 put(data) smešta podatke u bafer kada ima dostupan prostor get(data) dobavlja podatke iz bafera kada ima dostupne podatke Definišimo zaštićene celine bufferPool Monitor se može implementirati kako je to prikazano na slici 2.48. monitor boundBuffer bufferPool; count=0; cond notEmpty; // signalizira kada je count>0 cond notFull; // signalizira kada je count<n put(anitem) { while(count==n) wait(notFull); put anitem u buffer signal(notEmpty); } get(anitem) { while(count==0) wait(notEmpty);

get anitem iz buffer-a signal(notFull); } Slika 2.48. Rešenje monitora kod problema ograničeni bafer Kodni fragmenti koji se odnose na implementaciju su prikazani na slici 2.49. Producer while(1) ...... produce item anitem ...... boundBuffer.put(anitem) ...... end while
Consumer while(1) ...... boundBuffer.get(anitem) ...... consume item anitem ...... end while
Slika 2.49. Korišćenje monitora kod Producer i Consumer za rešavanje problema ograničeni
bafer. 2.11. Umiranje od gladi Kada se radi sa semaforima ili monitorima postoji realni uslov da se javi problem starvation (umiranje od gladi). To znači da postoji jedan proces čije se izvršenje (running) permanentno odlaže. Ovakva situacija može da se javi kada proces u okviru monitora ili semafora čeka da se drugi procesi dodaju ili izbavljaju u LIFO redosledu. 2.12 Samrtni zagrljaj Kada se radi o multitasking okruženju, javlja se još jedan problem nazvan deadlock (samrtni zagrljaj). Deadlock se javlja kada je svakom procesu iz skupa procesa, sa ciljem da nastavi sa daljim radom, potreban resurs koji se čuva od strane drugih procesa iz tog skupa. O ovom problemu govorićemo u narednom poglavlju.


















![Programski Jezik C++Sa Resenim Zadacima [Laslo Kraus BG]](https://img.dokumen.tips/doc/110x75/55cf983a550346d0339660e6/programski-jezik-csa-resenim-zadacima-laslo-kraus-bg.jpg)










