Embed Size (px)
Citation preview

1
Information retrieval systems in scientific and technological libraries:
from monolith to puzzle and beyond
Vrije Universiteit Brussel
Pleinlaan 2, B-1050 Brussels, BelgiumPrepared for a presentation at the annual conference
organised by IATUL http://www.iatul.org/ the International Association of Technological University Libraries in Porto, Portugal, May 2006

2
These slides should be available from the WWW site
http://www.vub.ac.be/BIBLIO/nieuwenhuysen/presentations/
note: BIBLIO and not biblio

3
Abstract of this presentationThis contribution presents an overview of the evolution of the retrieval systems implemented in
scientific and technological libraries to bring user to relevant information sources. We observe a growth in complexity, 1. starting from classical hard-copy catalogues over the monolith online public access catalogue 2. to a puzzle of software tools that try to cope with the growing complexity of the information sources
and services offered by libraries 3. while the evolution is going on and pieces of the puzzle are still missing; so software developers and
librarians may pay attention to these software tools for their future activities.More concretely we consider software systems• to improve the queries made by users, by expansion or refinement;• to cope with ambiguity of queries by categorizing search results in topical clusters;• to visualize data sets (information) in a map on the user’s computer display to assist the user in
analysing, interpreting, understanding, and eventually in decision making; such visualization tools can be applied to show and reveal for instance
» the characteristics of the collection(s) of data/ information sources that are made available to the user,
» the relations among words, terms, classification codes and so on, in the process of formulating and improving queries,
» some characteristics of the set of documents that results from a search query by a user.In conclusion: significant progress is still possible in the area of information retrieval tools offered by
libraries.

4
Information retrieval systems in libraries:
1. from monolith
2. to puzzle
3. and beyond:
3.1 Systems to expand or refine a search
3.2 Systems to cluster documents
3.3 Systems to visualize sets of data
contents = summary = structure = overviewof this presentation

0. Information retrieval in libraries
is (still) evolving

6
Information retrieval in libraries is (still) evolving
• This contribution presents an overview of the evolution of the retrieval systems implemented in libraries to bring users to relevant information sources.
• Complexity is increasing.
• Moreover several additional computer-based tools are proposed that may add some value.

1. The past: Information retrieval
through the monolith catalogue

8
1. The past: Information retrieval through the monolith catalogue
• Classical hard-copy catalogues and more recent computer-based catalogues have fulfilled a central role in most libraries.
• They can be seen as monoliths: solid, simple, straightforward systems.

2. The present: Information retrieval
as a puzzle

10
2.1 Many target databases in the puzzle
• Many libraries today offer access to
1. hard-copy collections
2. digital information collections
• Therefore they are called “hybrid” libraries.
• Examples of target databases:
» online access catalogues of local print collections
» local online access digital document repository
» external bibliographic databases
» external full-text databases and repositories
» search engines to find external WWW pages

11
2.2 Many library retrieval tools in the puzzle
• To offer the contents to users, many computer-based tools can be installed by the library, such as
»a central library catalogue, using database technology
»a WWW site of the library, which offers links to sources
»a system to search through a local document repository
»a system for federated searching through several databases
»a system that generates links from an available starting point to related information sources and services (based on OpenURL)
»(search engines that cover selected WWW pages)

12
2.3 Need to educate and guide users in information retrieval
• The complexity of the information landscape, in particular of the sources + retrieval tools and services offered by many libraries justify the metaphor “puzzle” or “jigsaw puzzle”.
• Some user guidance is justified so that all the libraries offering can be exploited well and efficiently by well-informed users.

13
2.4 Assembling the pieces of the information retrieval puzzle
• To reduce the complexity in the eyes of users, it is important that the many retrieval system components in the library are integrated as far as possible.
• Furthermore, user education and guidance should be well integrated in this information retrieval system.
• In this line of thinking, it helps when an OpenURL-based generator of links is incorporated in the retrieval system of a library.

3. The future? Missing pieces
of the information retrieval puzzle3.0 Introduction

15
3.0 Introduction
• The evolution of the retrieval tools or ‘system’ offered by libraries is going on and we suggest that some pieces of the puzzle are still missing.
• Software developers and librarians may include these in their planning.

16
3.0 Introduction: Basic difficulties in information retrieval
• Information retrieval from databases is hindered by several difficulties.
• These are well-known by information experts and scientists, but not by all users.
• The following are some fundamental problems.

17
3.0 Introduction: Basic difficulties in information retrieval (continued)
Difficulty: A word or phrase is not the same as a concept.
This may cause a low recall.
Word
WordConcept

18
3.0 Introduction: Basic difficulties in information retrieval (continued)
• When the user needs information related to a particular concept or a combination of more elementary concepts, then the user should formulate a query that covers these concepts well, by using not just a single word or term to cover each concept, but by using several words and/or terms, including synonyms, spelling variations, narrower terms, related terms, translations, and so on.
• The aim is mainly to increase the recall of the search action, by covering the concept better, but also to increase the precision by including the most appropriate words and/or terms in the query.
19
3.0 Introduction: Basic difficulties in information retrieval (continued)
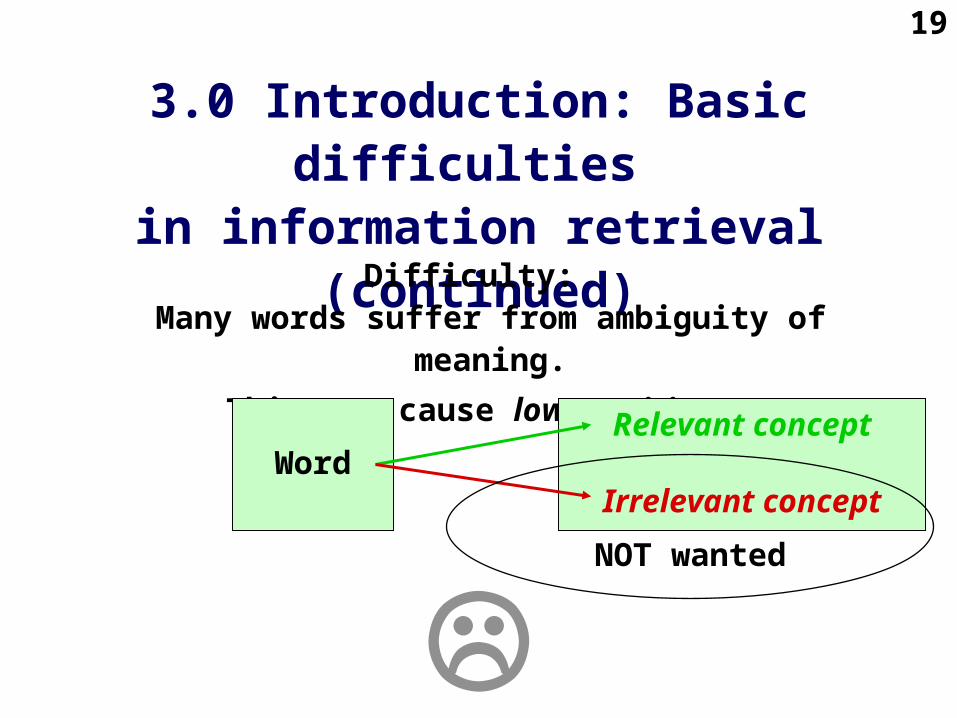
Difficulty: Many words suffer from ambiguity of meaning.
This may cause low precision.
WordRelevant concept
Irrelevant concept
NOT wanted

20
3.0 Introduction: Basic difficulties in information retrieval (continued)
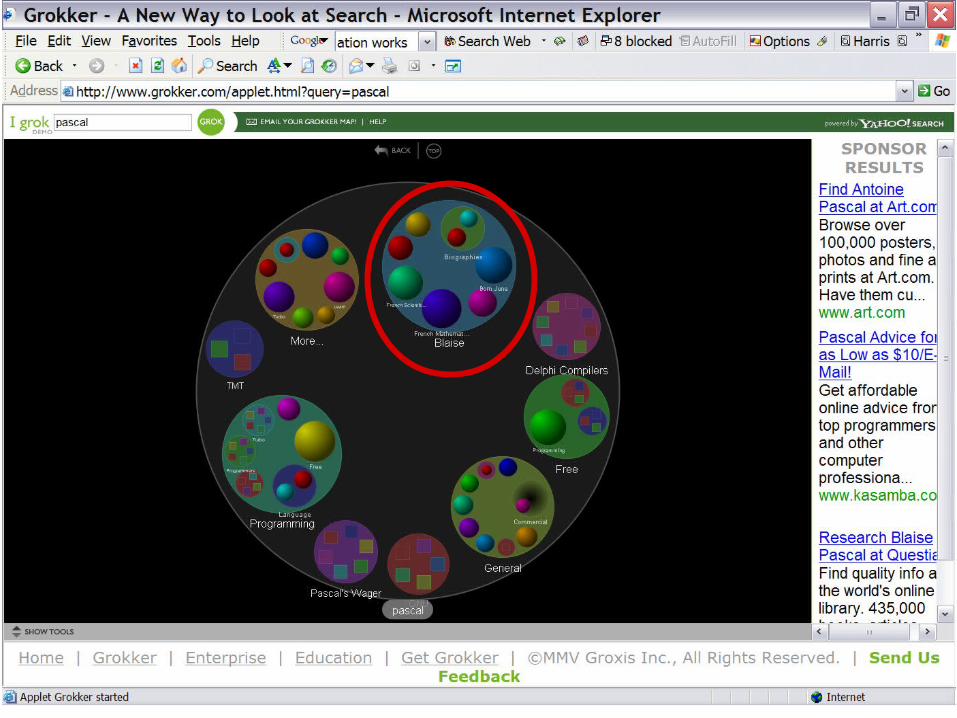
• Many words and/or terms from some natural language suffer from ambiguity, because natural languages have evolved spontaneously, not strictly controlled.
• An example is the word “pascal”, which can have several meanings:»the philosopher named Blaise Pascal, »the programming language named Pascal, »the physical unit of pressure, and »the name of many persons…

21
3.0 Introduction: Basic difficulties in information retrieval (continued)
• When ambiguous words or terms are inserted by a user in a database query, then this generates noise, irrelevant entries in the query result set. In other words, this lowers the precision of a search, where ‘precision’ can be defined more formally.
• This difficulty can be tackled »already in the stage of database production, »in the stage of formulating a query, and also »in the stage when the computer system presents the results
of a query, for instance by clustering the results in topical categories.

3. The future? Missing pieces
of the information retrieval puzzle3.1 System to expand or to limit
a first query by a user

23
3.1.1 Classification and thesaurus systems
• To cope with the difficulties mentioned above, classification and thesaurus systems have been used already for centuries.
• In reality nowadays, many information collections have become so large that application of a classification or thesaurus system by the database producer has become too expensive. Any of the well-know, popular, big WWW search engines can serve here as an example.

24
3.1.1 Classification and thesaurus systems
• Furthermore we prefer ideally a system that is applicable to any target database or even to several targets at the same time, like in federated searching through several databases in one search action.
• Therefore, a comprehensive, horizontal, general thesaurus system for some relevant human natural languages would be welcome.
• Ideally this would be integrated well with the user interface offered to formulate a search query.
• Application of the thesaurus helps the user to expand or refine an initial query, manually, after consideration of several possibilities.

25
3.1.1 Horizontal thesaurus systems for natural human language
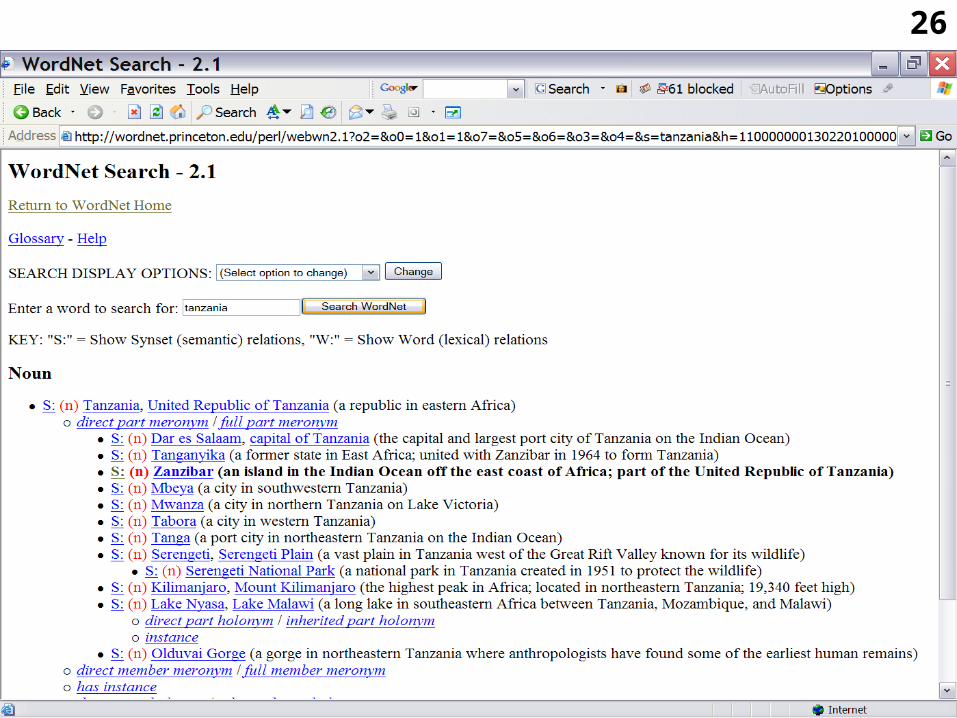
• For instance, WordNet offers an open access thesaurus for the English language.
• A WWW site is devoted to the system: http://wordnet.princeton.edu/
• WordNet can be used as the basis of a thesaurus integrated in some retrieval software system.
26

27
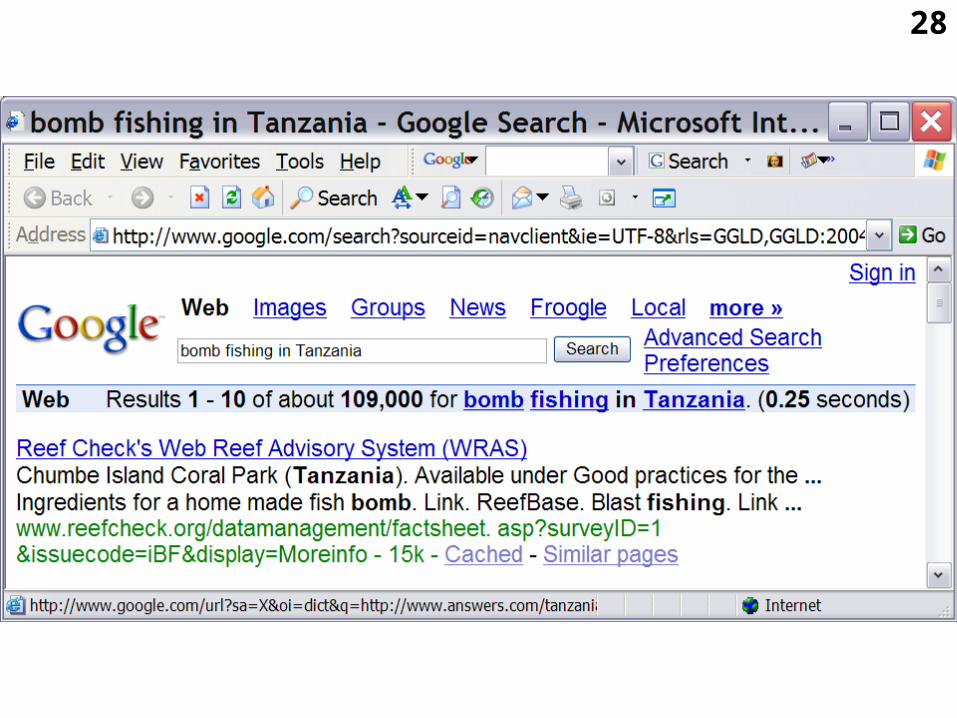
3.1.1 Horizontal thesaurus systems for natural human language
• Another example: the WWW search engine Google Web Search offers already for a few years a link from the user’s individual query words in English to a
»dictionary,
»thesaurus, and/or
»encyclopaedia
28

29
3.1.1 Horizontal thesaurus systems for natural human language
• Google offers this feature not in an aggressive or striking way, and its possible application is not clear for most users.
• So most users probably neglect this feature.
• This feature can be used to expand or refine a query.

30
3.1.1 Horizontal thesaurus systems for natural human language
• Furthermore, Google Web Search offers also a more direct, automatic expansion of query words, at least for the English language.
• This requires an explicit request through the Google command language by the user to implement this, in fact by preceding a particular search query word in a query by a tilde like in “~queryword”.
• However, this is probably not known by most users. A more user-friendly implementation would be welcome.

31
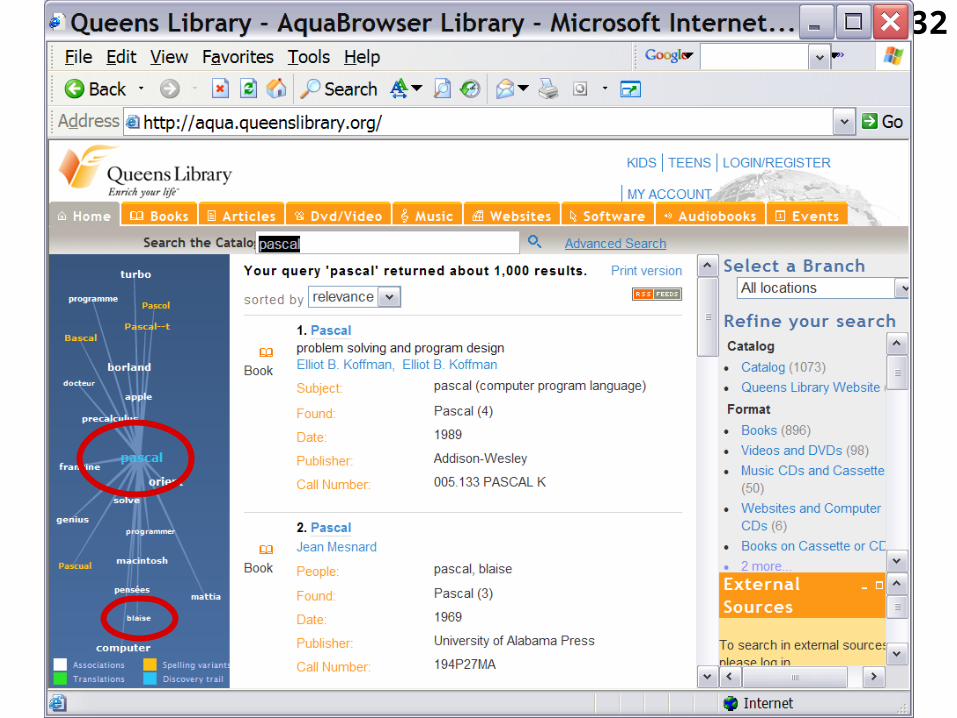
3.1.2 System based on words present in the context of the first query
• For instance, AquaBrowser Library software shows the query words of a user in the context of a selection of other words that occur in the document collection.
• More information is available from their WWW site http://www.medialab.nl/
• We can read there: “When you type in a word, you get a 'word cloud' that contains different associations and shades of meaning of that word. You click on the ones that most closely match your interest, and it will help you find
the library resources you need. It’s a lot of fun to use, too."
32

33

3. The future? Missing pieces
of the information retrieval puzzle3.2 Automatic topical
clustering / categorization / classification of search results

35
3.2.0 Automatic topical clustering today
• The ambiguity of words and terms from natural languages lowers the precision of searches executed with relatively classical, simple retrieval software, as mentioned above.
• This problem can be tackled by topical clustering of search results on the basis of the words included in those results, hoping that this will result in clusters of documents about similar, semantically related concepts/topics/subjects.

36
3.2.0 Automatic topical clustering today
• Advantages offered by clustering include the following:»The presentation in clusters helps the user to interpret and
navigate the results faster and more efficiently.Furthermore, selecting and entering a cluster is simple while this corresponds to narrowing the initial search.This is more complicated in a more classical, traditional, simple search system.
»The clusters can also reveal the few rare entries/results/documents that are relevant, but that would be buried by other entries in the single set of results that is created by a more simple search engine.

37
3.2.0 Automatic topical clustering today
• These days some useful clustering can be accomplished in real time, on the fly, almost instantaneously, without a significant delay for the user.
• For instance Clusty, Grokker, Kartoo, Vivisimo, Wisenut offer federated searching of databases plus clustering of the search results.

38
3.2.1 Clusty
• http://clusty.com/
• This is an internet meta-search engine that offers not only a conventional ranked list of search results but also search results clustered by topics or sources or URLs.
• The system is produced by the same company that produces the Vivisimo WWW meta-search system that is also mentioned further below. Both use the ‘Vivisimo Clustering Engine’.

39

40
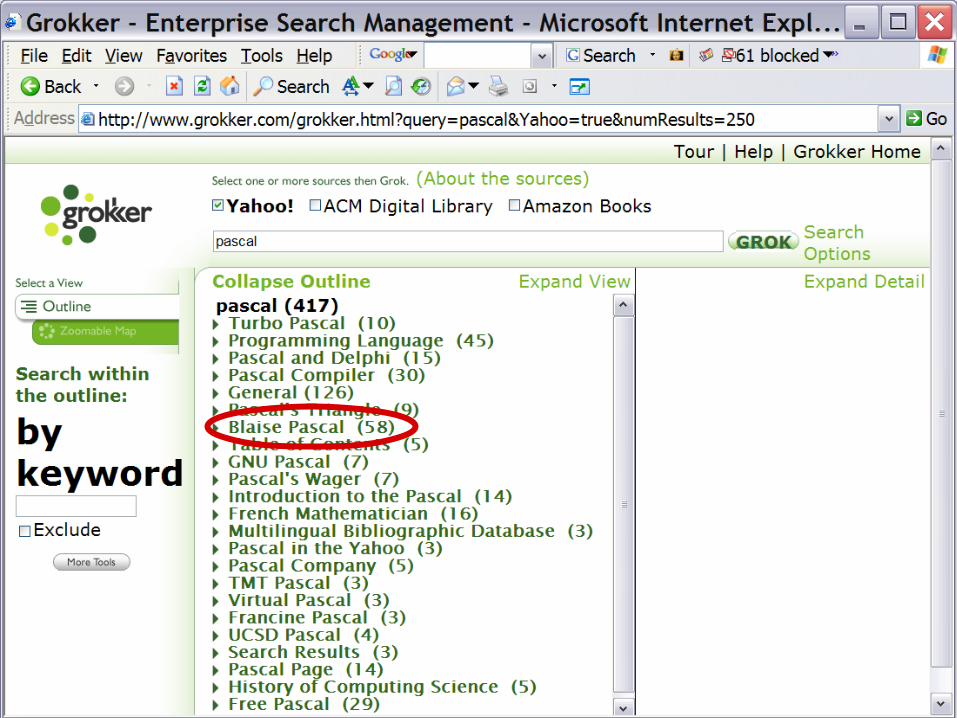
3.2.2 Grokker
• http://www.grokker.com/
• A public access implementation of Grokker software offers federated searching free of charge through the
»Yahoo! WWW search engine database,
»the Amazon Book database, and
»the ACM Digital Library
• The results are offered in an outline, a list of categories (and --if wanted-- also in the more graphical form of an interactive map).
41

42
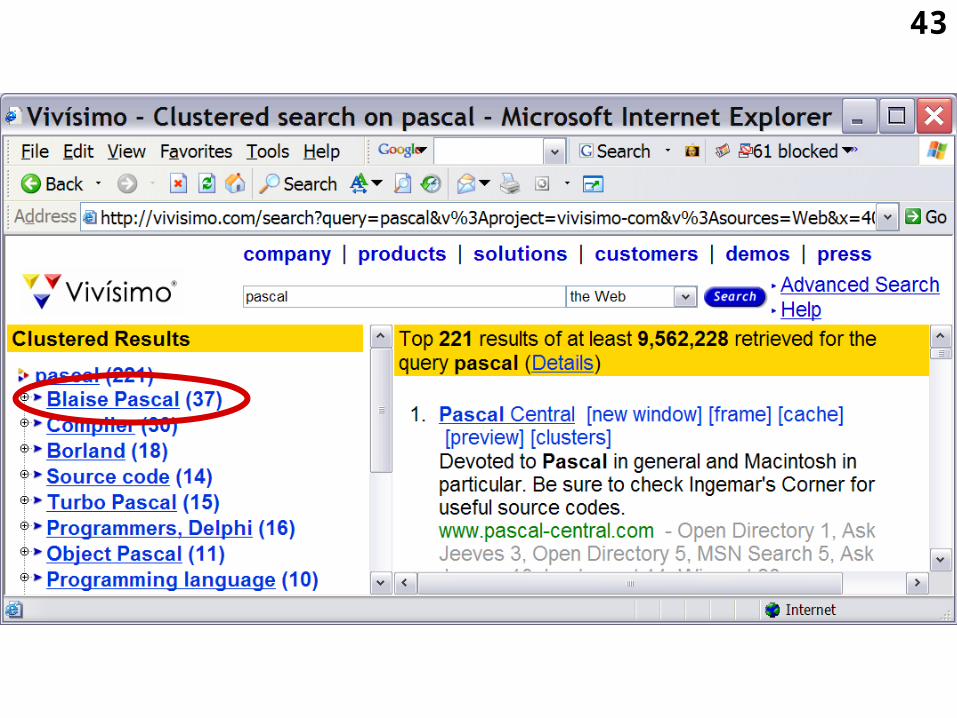
3.2.4 Vivisimo
• http://vivisimo.com/
• A public access implementation of Vivisimo software offers federated searching free of charge through many WWW search engine databases.Then it clusters results in an outline, a list of categories.
• (Clusty mentioned above uses the same ‘Vivisimo Clustering Engine’)
43

44
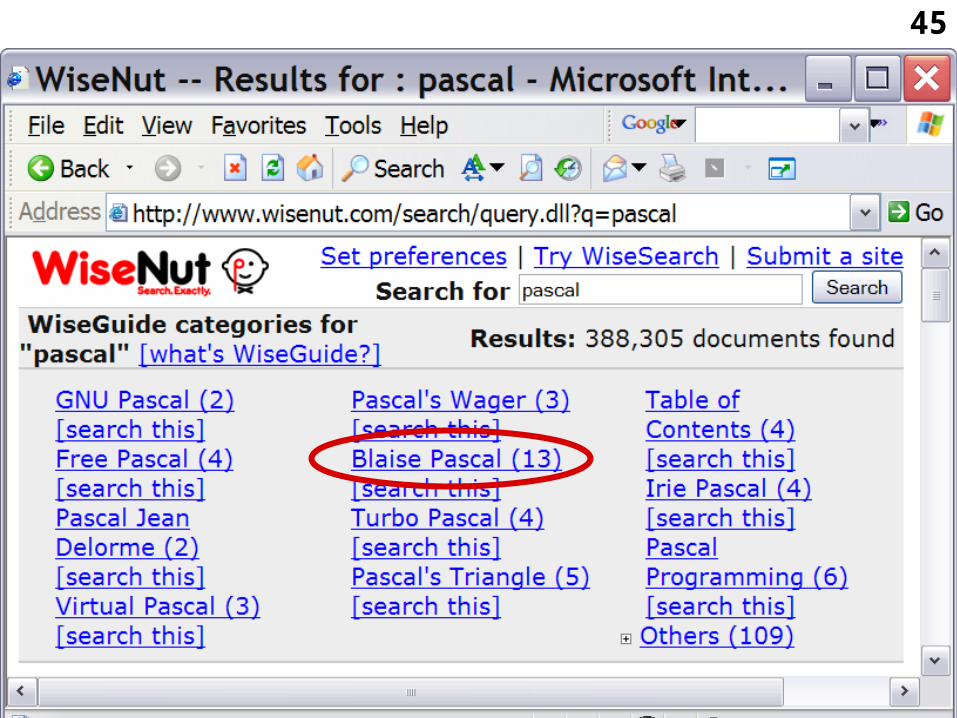
3.2.5 Wisenut
• http://www.wisenut.com/
• Wisenut offers searching free of charge through WWW pages and clusters the results in an outline, a list of categories.
45

3. The future? Missing pieces
of the information retrieval puzzle3.3 More information visualization
in the user interfaces

47
3.3.0 Information visualization: introduction
• Visualisation can help users to interpret complex data sets so that better decisions can be made faster.
• On the one hand the maps created by the system should help users to interpret and analyse a set data, but on the other hand they bring their own cognitive load. In other words, before the user can interpret the data set, first the type of visualization must be understood.
• Some mapping technique will probably prove to be useful and widely acceptable in the near future.

48
3.3.0 Information visualization: introduction
• Clustering is related to visualization:
1. Clusters of documents are identified by the retrieval system.
2. In the next step, some mapping software can visualize in a map on the user’s computer display
» one or several properties of the clusters(such as their relative size )
» and one or a few relations among the clusters.

49
3.3.1 Visualization of the information source available
• It may be useful to visualize some aspects of information sources to a user, to give the user a better idea of what is available.
• Visualization of what is available can already be applied in the case of the hard disk on personal computers. Obviously it is interesting to get a clear view on the contents of a hard disk. Some utility programs are available that can be installed and applied for this purpose.

50

51
3.3.2 Visualization in a system that helps the user to formulate a query
• Visualization can also be useful In the next phase, when a user has to expand, to limit or to refine a search query.

52
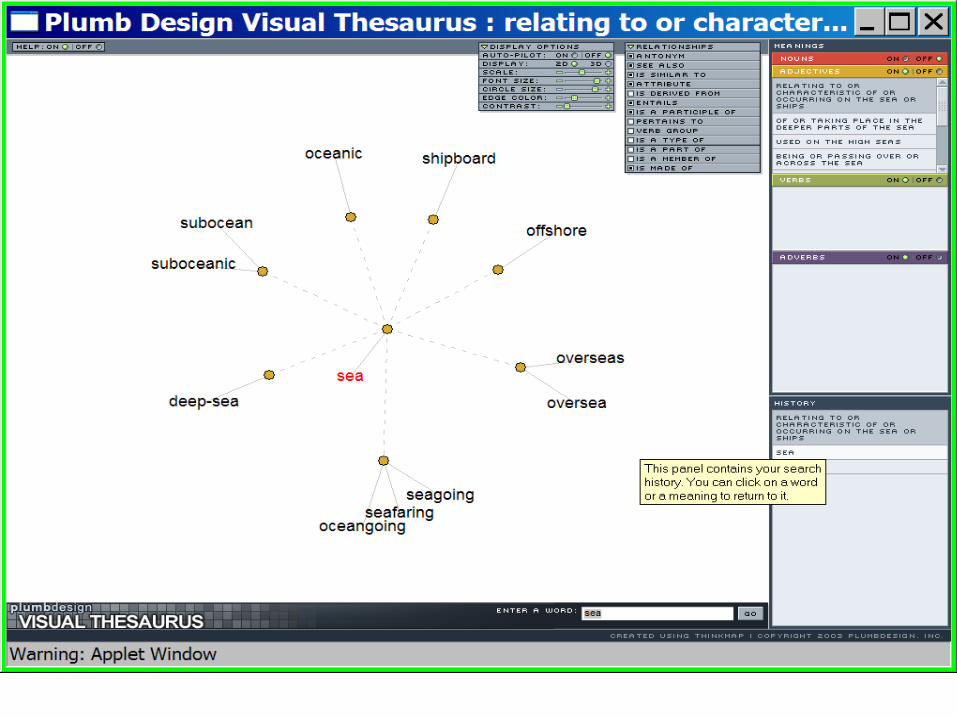
3.3.2 Visualization in a system that helps the user to formulate a query
• For instance the Thinkmap Visual Thesaurus can show relations among words in English in a graphical map on the computer display that is obviously 2-dimensional.
• Furthermore the map is dynamic: it moves to reveal and show the underlying 3-dimensional, spatial map of the related words and phrases.
• The software exploits the open access WordNet thesaurus (which is mentioned also above).
• http://www.visualthesaurus.com/
53

54
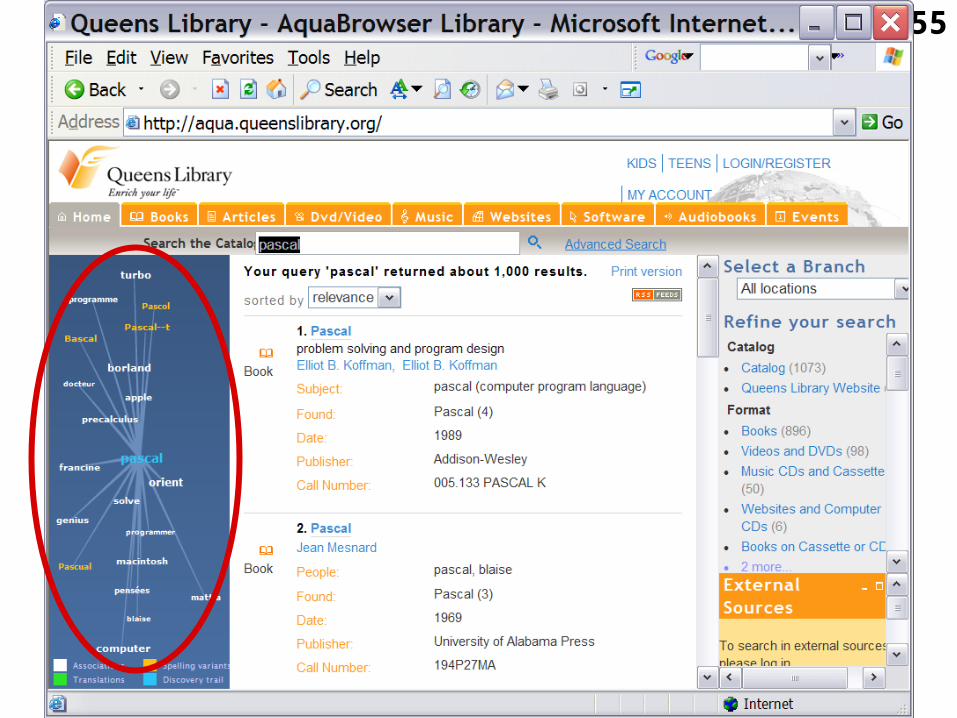
3.3.2 Visualization in a system that helps the user to formulate a query
• Another example: As mentioned and illustrated above, the AquaBrowser Library software visualizes relations between a user’s query and other words that are present in the information items that a library makes available and that may be relevant in the context of the query.
55

56
3.3.3 Visualization of the characteristics of query result sets
• In a next phase, when a user has formulated a query and has executed the search, then the set of search results are presented in most cases as a simple list of references, ordered or ranked in some way or another.
• Some systems go further and offer results in clusters(as outlined above).
• Moreover, some programs do not offer the results merely with text only, but they can visualize the results in the form of a map.

57
3.3.3 Visualization of the characteristics of query result sets
• For instance:Kartoo software can be applied
1. to search
2. to cluster/categorize the search results
3. and furthermore, to visualize these clusters in a map.
• A public access site offers meta-searching in several WWW search engines, free of charge, through http://www.kartoo.com/

58

59
3.3.3 Visualization of the characteristics of query result sets
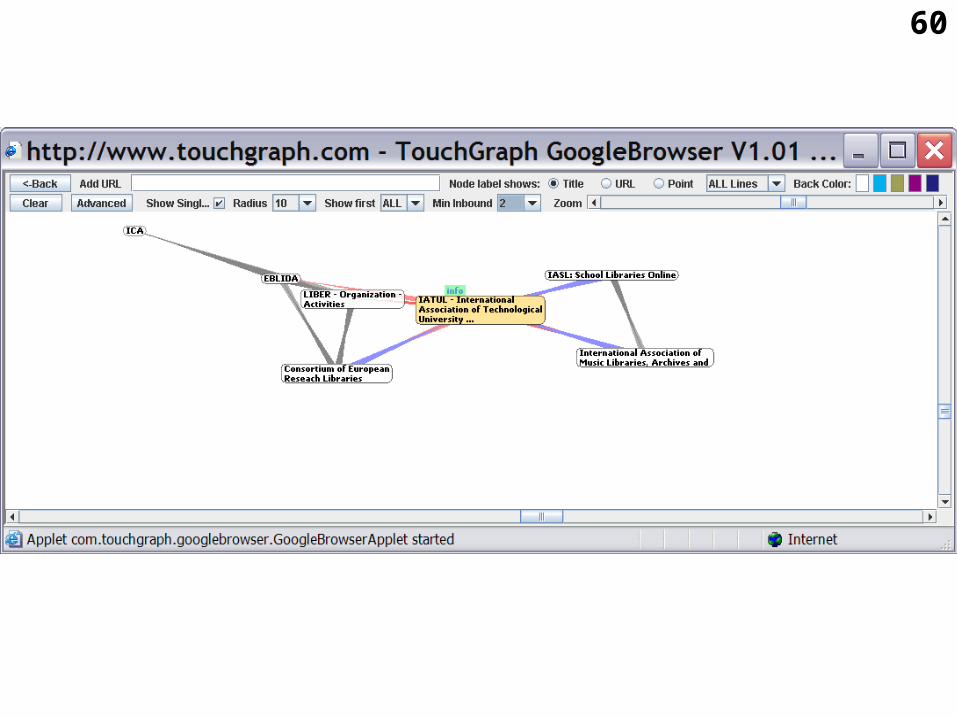
• Another example: Touchgraph software allows the creation of visual maps.Several demonstration systems are accessible online, free of charge, through http://www.touchgraph.com/index.html
• One particular application of the Touchgraph system can show WWW sites that are related to a particular WWW site that is investigated by the user, by exploiting the database of a WWW search engine http://www.touchgraph.com/TGGoogleBrowser.html
60

61
3.3.3 Visualization of the characteristics of query result sets
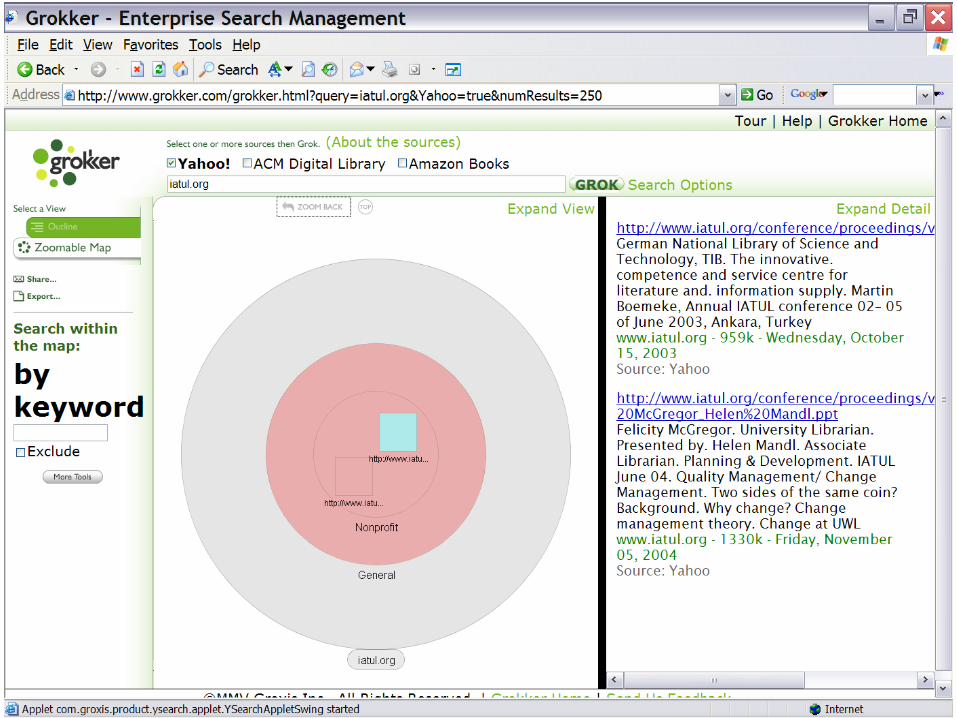
• Another example: Grokker software
1. can execute federated searches through several databases in 1 action,
2. can cluster/categorize results from search actions, and3. can then visualize these in a map
• A public access implementation allows anyone to perform a WWW search based on the Yahoo! database of WWW pages: http://www.grokker.com/
• Has already been implemented in a university library.
62
63

Conclusion

65
Conclusionon information retrieval in libraries
• The development of information retrieval tools offered by libraries has not yet come to an end.
• Significant progress is still possible.
• Of course in reality resources are limited and priorities must be set.

66
Questions?
Suggestions?
Topics for discussion?

67
• You are free to copy, distribute, display this work under the following conditions:
»Attribution: You must mention the author.
»Noncommercial: You may not use this work for commercial purposes.
»No Derivative Works: You may not change, modify, alter, transform, or build upon this work.
• For any reuse or distribution, you must make clear to others the license terms of this work.





























