Embed Size (px)
Citation preview

고급정보검색론Advanced Information Retrieval
Data Mining Lab., Univ. of Seoul 1

강의 주제• 정보검색
• intelligent information retrieval
• 텍스트 마이닝• Data mining• Text mining• Machine learning
• 분석 도구의 활용• R: language and environment for statistical
computing and graphics.
강의 목표

Data Mining Lab., Univ. of Seoul 3
교재 : Introduction to Information Re-trieval
• 강의홈페이지• http://dmlab.uos.ac.kr/dmlab/
TextMining(2014-1)
R 교재
http://dmlab.uos.ac.kr
강의 홈페이지
Data Mining Lab., Univ. of Seoul 6
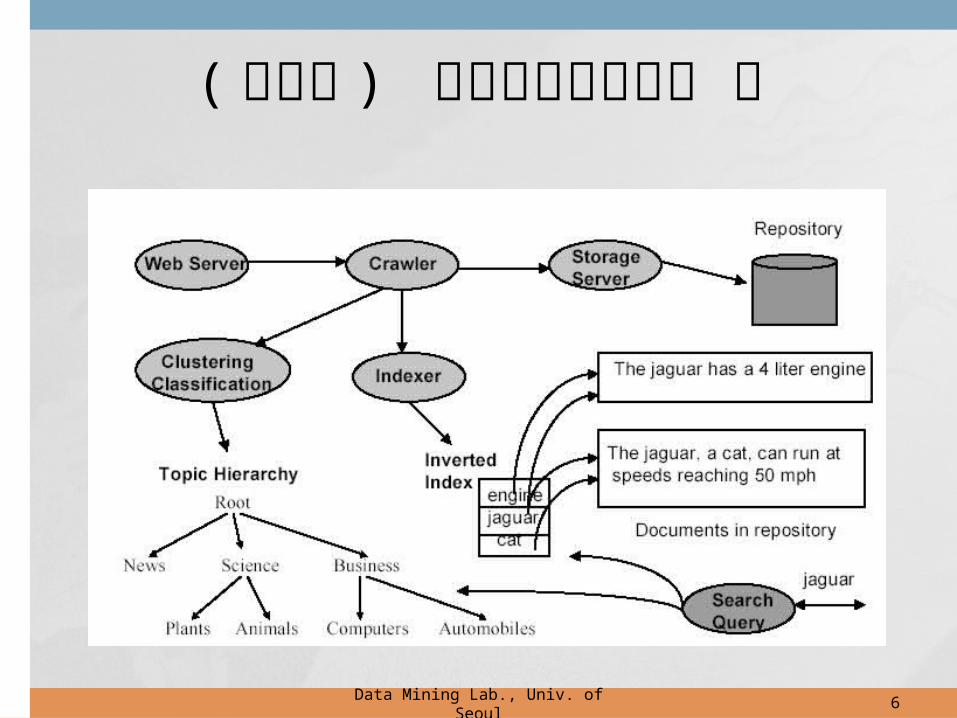
( 지능형 ) 정보검색시스템의 예

평가 방법• 발표 : 25%• 과제 리포트 : 25%
• 텍스트마이닝 및 최신 검색 기법 활용• 기말시험 : 50%
Data Mining Lab., Univ. of Seoul 7
Evaluation

The indexing and retrieval of textual documents.
Searching for pages on the World Wide Web is the most recent “killer app.”
Concerned firstly with retrieving relevant documents to a query.
Concerned secondly with retrieving from large sets of documents effi-ciently.
8
Information Retrieval(IR)

Given:• A corpus of textual natural-language
documents.• A user query in the form of a textual
string. Find:
• A ranked set of documents that are relevant to the query.
9
Typical IR Task
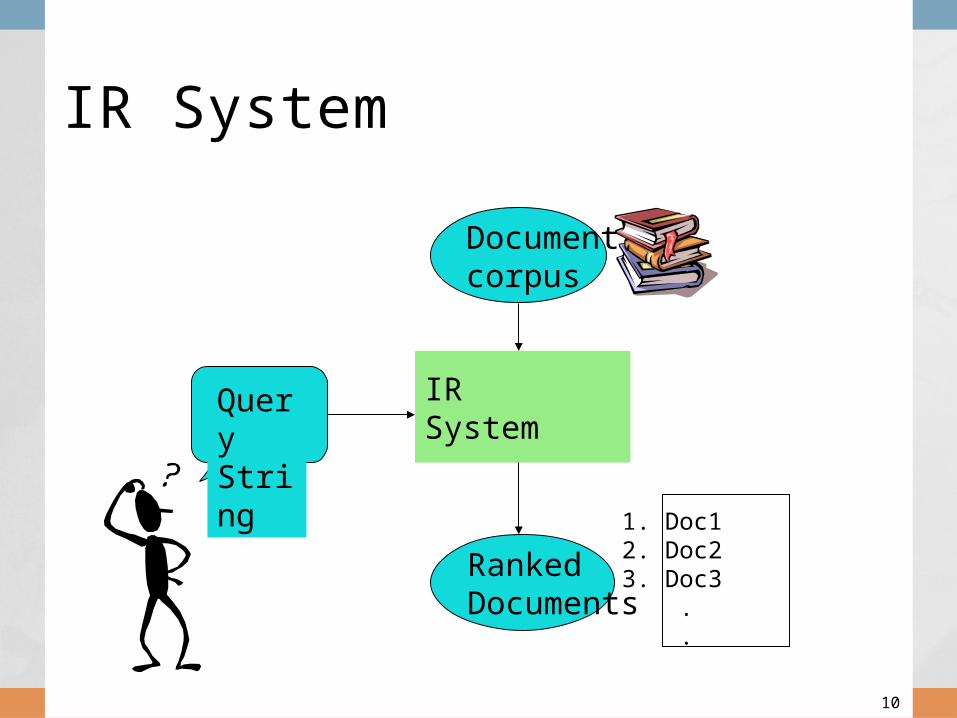
IR System
10
IRSystem
Query String
Documentcorpus
RankedDocuments
1. Doc12. Doc23. Doc3 . .

Relevance is a subjective judgment and may include:• Being on the proper subject.• Being timely (recent information).• Being authoritative (from a trusted
source).• Satisfying the goals of the user and
his/her intended use of the information (information need).
11
Relevance

Simplest notion of relevance is that the query string appears verbatim in the document.
Slightly less strict notion is that the words in the query appear fre-quently in the document, in any or-der (bag of words).
12
Keyword Search

May not retrieve relevant docu-ments that include synonymous terms.• “restaurant” vs. “caf锕 “PRC” vs. “China”
May retrieve irrelevant docu-ments that include ambiguous terms.• “bat” (baseball vs. mammal)• “Apple” (company vs. fruit)• “bit” (unit of data vs. act of eating)
13
Problems with Keywords

We will cover the basics of keyword-based IR, but…
We will focus on extensions and re-cent developments that go beyond keywords.
We will cover the basics of building an efficient IR system, but…
We will focus on basic capabilities and algorithms rather than system’s issues that allow scaling to indus-trial size databases.
14
Beyond Keywords

Taking into account the meaning of the words used.
Taking into account the order of words in the query.
Adapting to the user based on direct or indirect feedback.
Taking into account the authority of the source.
15
Intelligent IR
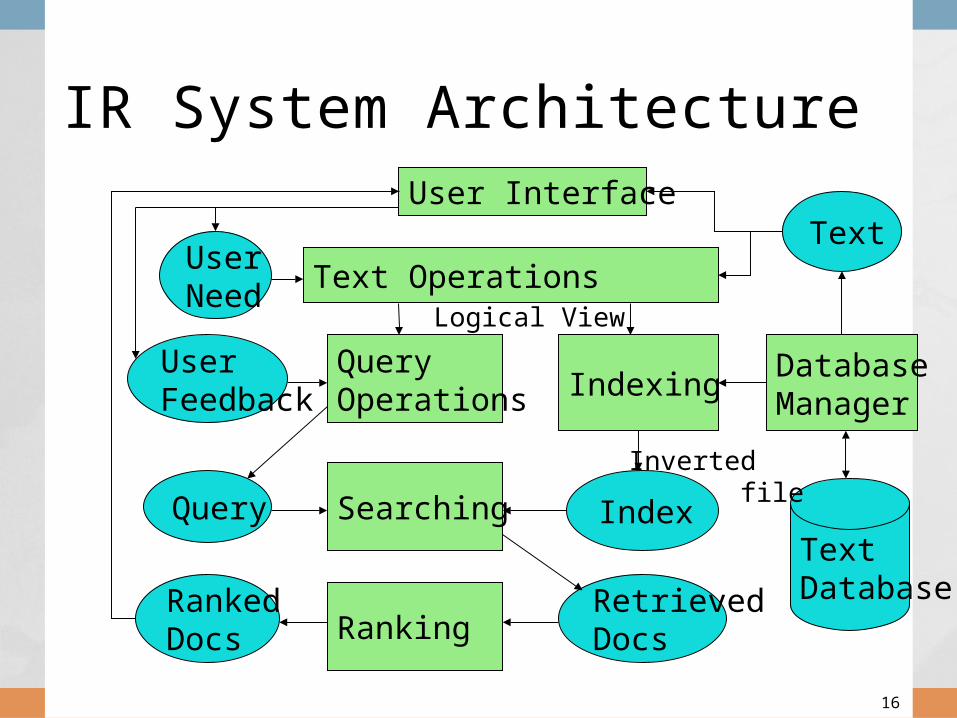
IR System Architecture
16
TextDatabase
DatabaseManager
Indexing
Index
QueryOperations
Searching
RankingRankedDocs
UserFeedback
Text Operations
User Interface
RetrievedDocs
UserNeed
Text
Query
Logical View
Inverted file

Text Operations forms index words (tokens).• Stopword removal• Stemming
Indexing constructs an inverted index of word to document pointers.
Searching retrieves documents that contain a given query token from the inverted index.
Ranking scores all retrieved docu-ments according to a relevance metric.
17
IR System Components

User Interface manages interaction with the user:• Query input and document output.• Relevance feedback.• Visualization of results.
Query Operations transform the query to improve retrieval:• Query expansion using a thesaurus.• Query transformation using relevance
feedback.
18
IR System Components (continued)
Application of IR to HTML docu-ments on the World Wide Web.
Differences:• Must assemble document corpus by
spidering the web.• Can exploit the structural layout in-
formation in HTML (XML).• Documents change uncontrollably.• Can exploit the link structure of the
web.
19
Web Search
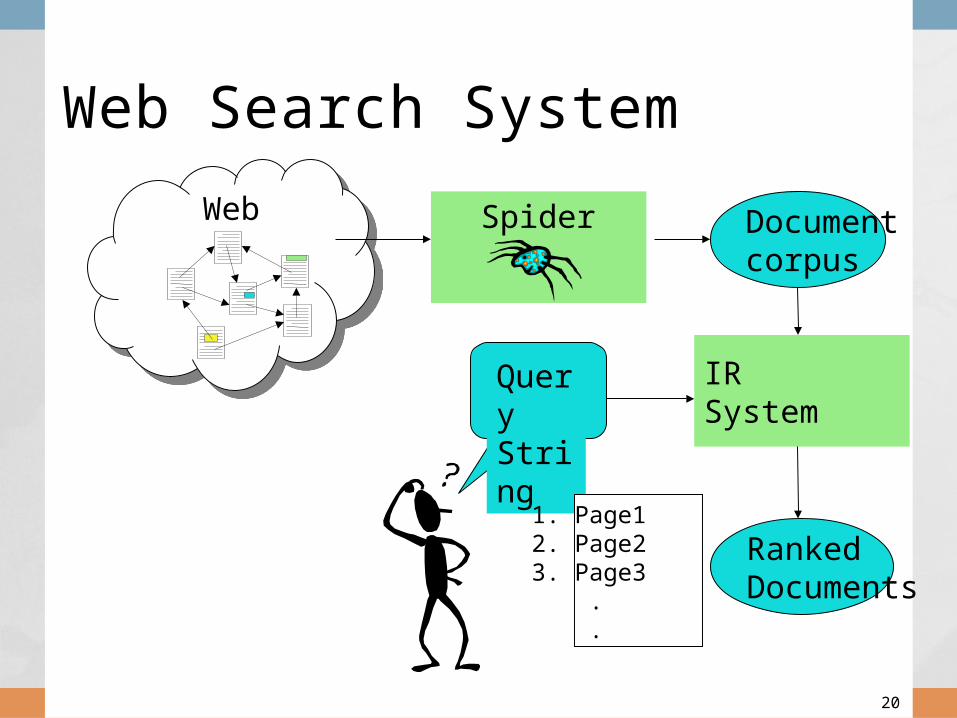
Web Search System
20
Query String
IRSystem
RankedDocuments
1. Page12. Page23. Page3 . .
Documentcorpus
Web Spider

Automated document categorization Information filtering (spam filtering) Information routing Automated document clustering Recommending information or prod-
ucts Information extraction Information integration Question answering
21
Modern IR-Related Tasks

1960-70’s:• Initial exploration of text retrieval sys-
tems for “small” corpora of scientific abstracts, and law and business docu-ments.
• Development of the basic Boolean and vector-space models of retrieval.
• Prof. Salton and his students at Cornell University are the leading researchers in the area.
22
History of IR

1980’s:• Large document database systems,
many run by companies:• Lexis-Nexis• Dialog• MEDLINE
23
IR History Continued

1990’s:• Searching FTPable documents on the
Internet• Archie• WAIS
• Searching the World Wide Web• Lycos• Yahoo• Altavista
24
IR History Continued

1990’s continued:• Organized Competitions
• NIST TREC
• Recommender Systems• Ringo• Amazon• NetPerceptions
• Automated Text Categorization & Clus-tering
25
IR History Continued

2000’s• Link analysis for Web Search
• Automated Information Extraction• Whizbang• Fetch• Burning Glass
• Question Answering• TREC Q/A track
26
Recent IR History

2000’s continued:• Multimedia IR
• Image• Video• Audio and music
• Cross-Language IR• DARPA Tides
• Document Summarization
27
Recent IR History

Database Management Library and Information Science Artificial Intelligence Natural Language Processing Machine Learning
28
Related Areas

Focused on structured data stored in re-lational tables rather than free-form text.
Focused on efficient processing of well-defined queries in a formal language (SQL).
Clearer semantics for both data and queries.
Recent move towards semi-structured data (XML) brings it closer to IR.
29
Database Management

Focused on the human user aspects of information retrieval (human-computer interaction, user interface, visualization).
Concerned with effective categoriza-tion of human knowledge.
Concerned with citation analysis and bibliometrics (structure of informa-tion).
Recent work on digital libraries brings it closer to CS & IR.
30
Library and Information Science

Focused on the representation of knowledge, reasoning, and intelli-gent action.
Formalisms for representing knowl-edge and queries:• First-order Predicate Logic• Bayesian Networks
Recent work on web ontologies and intelligent information agents brings it closer to IR.
31
Artificial Intelligence

Focused on the syntactic, semantic, and pragmatic analysis of natural language text and discourse.
Ability to analyze syntax (phrase structure) and semantics could allow retrieval based on meaning rather than keywords.
32
Natural Language Process-ing

Methods for determining the sense of an ambiguous word based on con-text (word sense disambiguation).
Methods for identifying specific pieces of information in a document (information extraction).
Methods for answering specific NL questions from document corpora.
33
Natural Language Processing:IR Directions

Focused on the development of computational systems that improve their performance with experience.
Automated classification of exam-ples based on learning concepts from labeled training examples (su-pervised learning).
Automated methods for clustering unlabeled examples into meaningful groups (unsupervised learning).
34
Machine Learning

Text Categorization• Automatic hierarchical classification (Ya-
hoo).• Adaptive filtering/routing/recommending.• Automated spam filtering.
Text Clustering• Clustering of IR query results.• Automatic formation of hierarchies (Ya-
hoo). Learning for Information Extraction Text Mining
35
Machine Learning:IR Directions

36
Machine Learning

37
Machine Learning
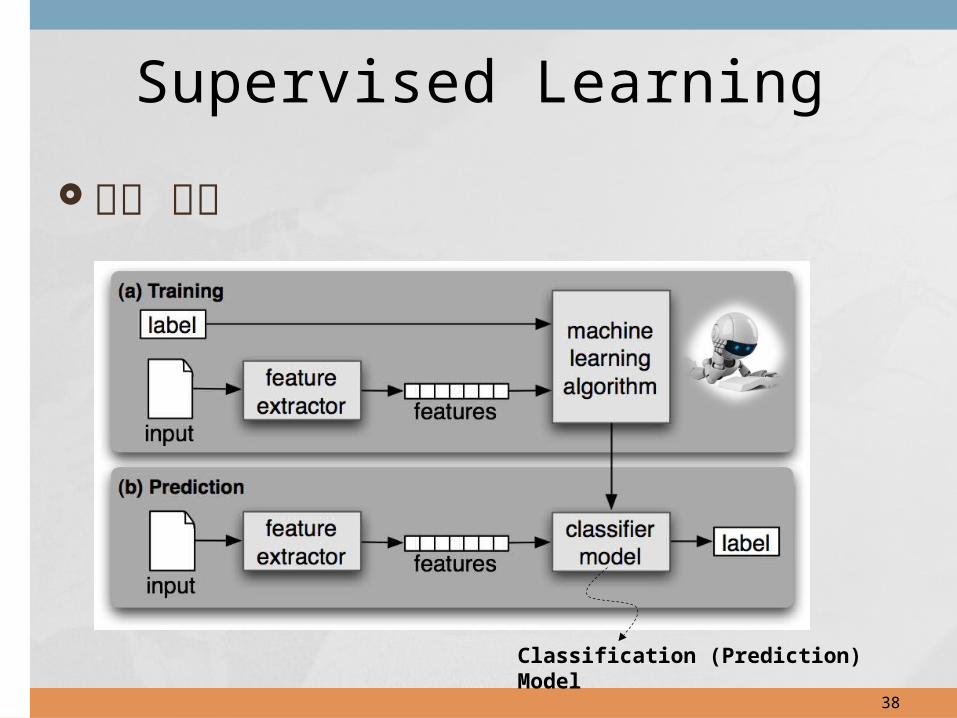
Supervised Learning• Classification• Prediction model
Unsupervised Learn-ing• Clustering, Association• Description model
Semi-Supervised Learning• For less supervision
Semi-Supervised Clustering• For a little supervision
38
Supervised Learning
기본 개념
Classification (Prediction)Model

39
Supervised Learning
Learning Algorithm 에 따라 Classifi-cation Model 이 다름

40
Decision Tree Neural Networks Bayesian Statistics
• Naïve Bayes• Bayesian Networks
Instance-based Learning• K-Nearest Neighbor
Support Vector Machine Rough Set Theory Meta-learning
• Ensemble (Committee): Bagging, Boosting• Expectation-Maximization (EM)
Supervised Learning Algo-rithms
41
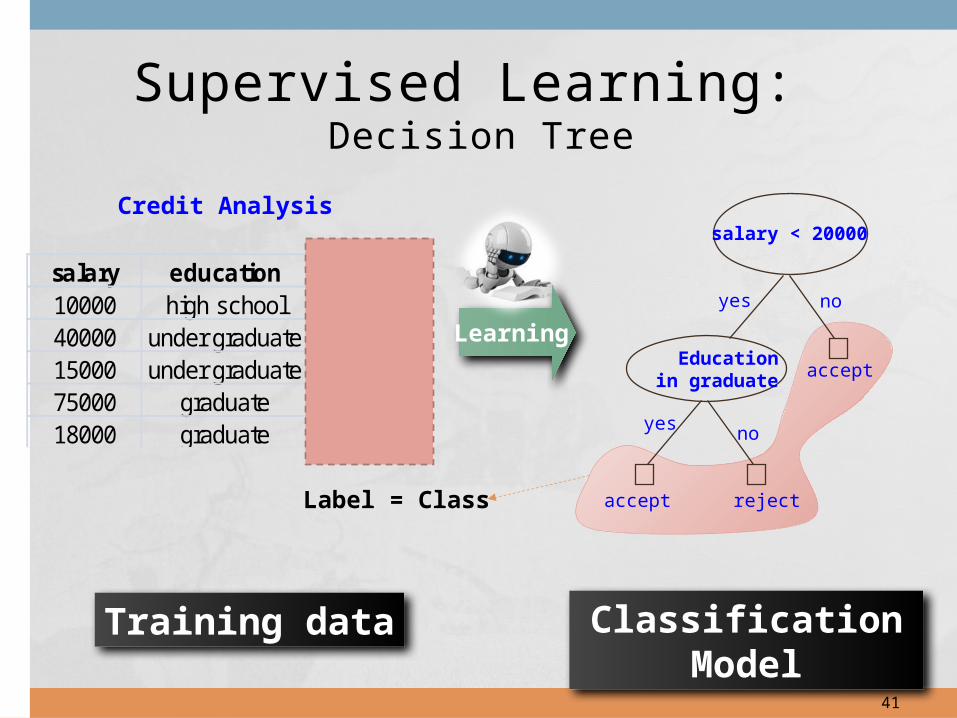
Supervised Learning: Decision Tree
salary education label10000 high school reject40000 under graduate accept15000 under graduate reject75000 graduate accept18000 graduate accept
accept reject
salary < 20000
noyes
noyes
acceptEducation
in graduate
Credit Analysis
Training data
Learning
Classification Model
Label = Class

• The hyper-plane that separates posi-tive and negative training data is
w x + b = 0
Supervised Learning: Support Vector Machine
42

43
dwcc
ccwdcdclassifier )Pr()|Pr(maxarg)|Pr(maxarg)(
Estimated probability distribution
Supervised Learning: Naïve Bayes
44
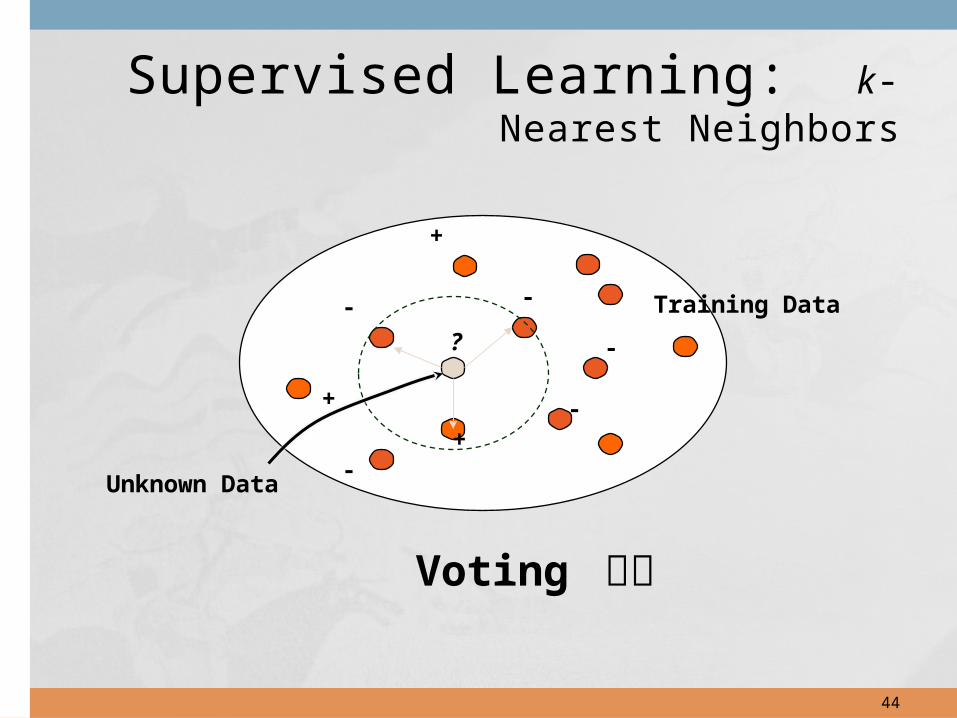
Supervised Learning: k-Nearest Neighbors
Voting 적용
?
+
+
+
-
- -
-
-
Training Data
Unknown Data

Data Mining Lab., Univ. of Seoul, Copyright ® 2008
Partitioning method• K-means, K-medoids, …
Hierarchical method• Agglomerative and divisive hierarchical clustering• Complete-linkage, single-linkage, group-average,
ward’s method• BIRCH, CURE, …
Density-based method• DBSCAN, OPTICS, …
Grid-based method• STING, WaveCluster, CLIQUE, …
Model-based method• Statistical approach, …
Unsupervised Learning Algo-rithms
: Clustering
45
Data Mining Lab., Univ. of Seoul, Copyright ® 2008
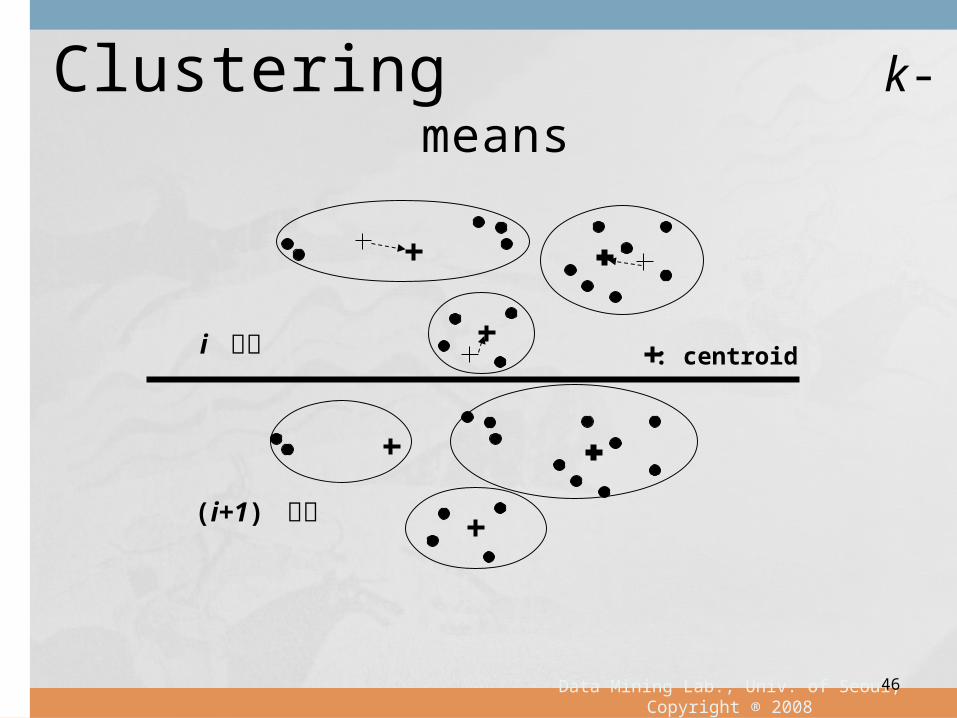
Clustering k-means
i 단계 : centroid
(i+1) 단계
46
Data Mining Lab., Univ. of Seoul, Copyright ® 2008
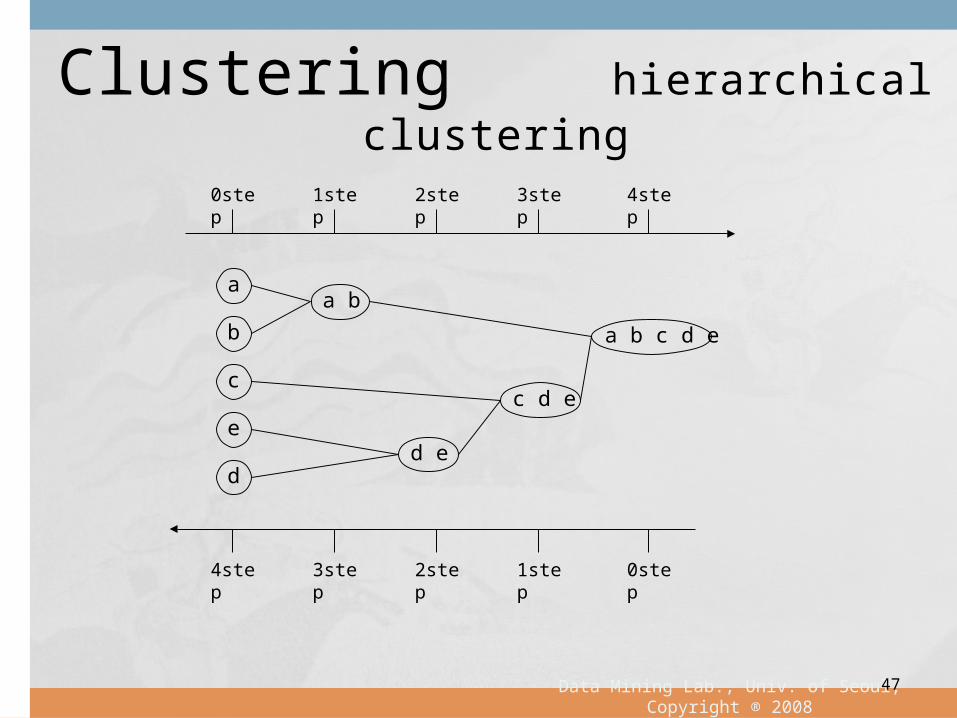
a
b
c
d
e
a b
c d e
d e
a b c d e
4step
3step
2step
1step
0step
0step
1step
2step
3step
4step
Clustering hierarchical cluster-ing
47
Data Mining Lab., Univ. of Seoul, Copyright ® 2008
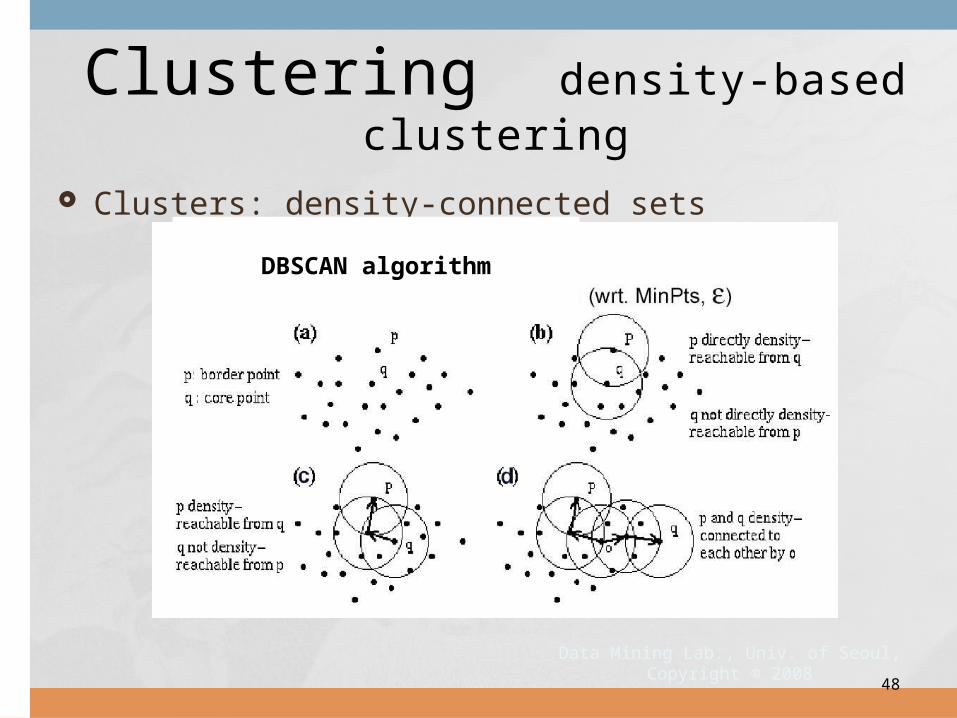
Clusters: density-connected sets
DBSCAN algorithm
Clustering density-based cluster-ing
48
49
Association (Rule) Mining
Basket Analysis A priori Algorithm
Sequential pattern mining Associations + Time (or order)

50
Text Mining

51
Text Mining
Data Mining• 구조적 데이터를 대상
Text Mining• Unstructured/Semi-structured text doc-
uments 를 대상 Text Mining 의 기반 기술
• Machine learning• Information retrieval• Natural language processing• Statistical learning

Data Mining Lab., Univ. of Seoul, Copyright ® 2008
Data Mining 과의 차이• Curse of Dimensionality
• Feature selection 기술이 중요• Zipf’s Law, document frequency, x2 Sta-
tistics, Mutual Information
• Natural language process 기술과 결합• linguistic, lexical, and semantical tech-
niques
Text Mining

53
Text Mining Application
Document Retrieval (Search) Document Recommendation Text Classification Text Clustering Text Summarization Text (information) Extraction Text Association Rule Mining Topic Detection
Data Mining Lab., Univ. of Seoul, Copyright ® 2008
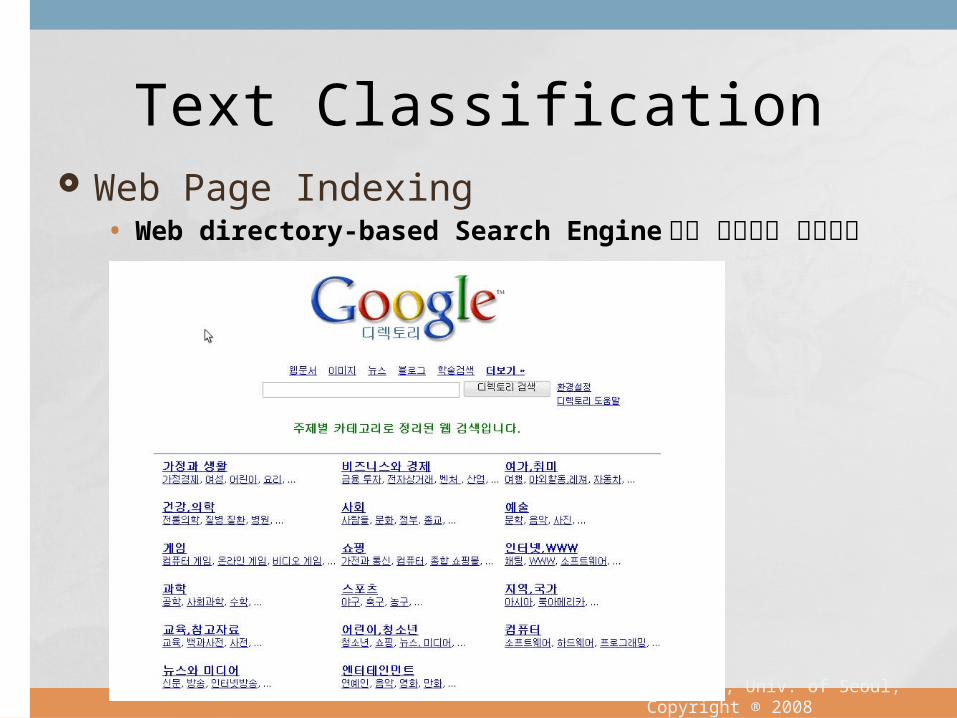
Web Page Indexing• Web directory-based Search Engine 에서 웹문서의
자동분류
Text Classification

55
Text Clustering
Document Clustering• Big text data 에 대한 조망 : document cluster 에 대한
description model 의 생성• Cluster 내 문서집합에서 주요 단어의 추출
• distance function 이 중요
Word Clustering• 용도 : thesaurus 구축 , word sense disambiguation 등• 2 가지 방식
• Corpus-based approach• Taxonomy-based approach
Data Mining Lab., Univ. of Seoul, Copyright ® 2008
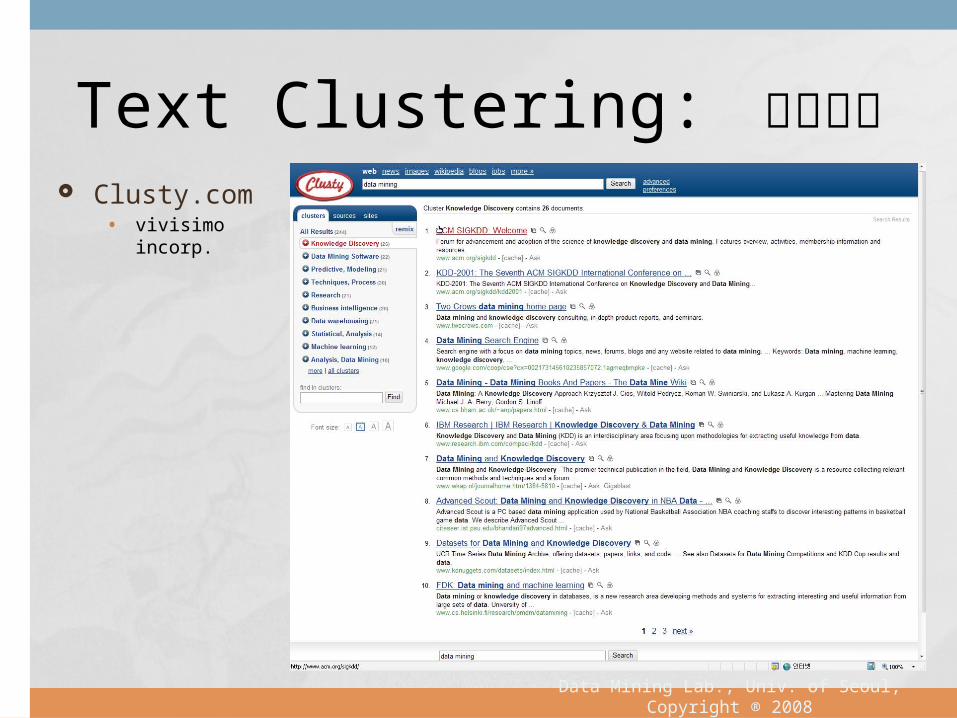
Clusty.com • vivisimo in-
corp.
Text Clustering: 검색엔진

57
Example:
Association Rules• w1 => w3 with 50% (2/4) support and 66% (2/3) confi-
dence• w3 => w1 with 50% (2/4) support and 100% (2/2) confi-
dence
Word Associations
doc-id words1 {w1, w2, w3}2 {w1, w4}3 {w1, w3}4 {w2, w5, w6}

Text Summarization
abstraction
중요 문장 -1
중요 문장 -2
중요 문장 -n
…MachineLearning활용
IE 활용
58


























