Embed Size (px)
Citation preview

XML
•XML stands for eXtensible Markup Language.•Markup language for documents containing structured information.•XML is designed to transport and store data.•XML is very easy to learn.•XML tags are not predefined. You can define your own tags.•XML is designed to be self-descriptive.•XML is a W3C Recommendation.

XML……..
•Based on Standard Generalized Markup Language (SGML).•Version 1.0 introduced by World Wide Web Consortium (W3C) in 1998.•Bridge for data exchange on the Web.•Standard Generalized Markup Languages are:

Also XML….
• Excellent for handling data with a complex structure or a typical data
• Data described using mark-up language• Text data description• Human- and computer-friendly format• Handles data in a tree structure having one-
and only one-root element• Excellent for long-term data storage and data
reusability

1. Excellent for Handling Data with a Complex Structure or Atypical Data
• Data managed using RDB tables has a regular data structure. One could say that nothing surpasses RDB for handling data of this type of structure.

• However, not all of the various data that exists in the world today is of a structure that can be managed using tables. Most such data has either an extremely complex structure (system logs, e-mail data, etc.), or is atypical data (product manuals, specification sheets, etc.) that has no specific structure. What can be done to handle these data types without extensive manipulation? XML is a data format well-suited to handling these circumstances.

2. Text Data Description
• XML allows for the description of data in a text format. Since XML uses text data, XML data created on a Windows platform can also be used in a UNIX system. Data can be delivered back and forth without having to take OS and systems differences into account.

3. Excellent for Long-Term Data Storage and Data Reusability
• Data created through a specific application becomes useless or even impossible to access if the application is eventually unusable or cannot maintain backward compatibility.
• However, XML documents are text data, and do not rely on any particular application. The data can be stored for long periods of time with little fear of ever becoming unusable. Using "XSLT (XSL Transformation)" (note), an XML document can be transformed into a document of a different structure or format (HTML, CSV, etc.), increasing the reusability of XML documents-a "one-source, multi-use" solution.

4. Human- and Computer-Friendly Format
• CSV is a typical example of a data format expressed using text. Data in CSV format is easily understood by programs designed to process CSV data, but only appears as a continuous string of characters to the human eye. Data expressed in XML, however, is "marked up" so it is not only an easy format for computer processing, but can be read and understood by humans.

5. Data Described using Mark-up Language
• With XML, each individual piece of information is "marked up" (a marker shows the meaning of the associated data) with a tag that attaches meaning to the information. The unit of data to which a meaning has been attached is called an "element." An "element" consists of a "start tag", "content," and an "end tag."
• When required, an "attribute" can be described in the start tag of an element, allowing more detailed information to be assigned to the data.

6. Handles data in a tree structure having one-and only one-root element
• With XML, a hierarchical element structure can be created by nesting elements. Under the XML specification, one-and only one-XML root element (the outmost element in an XML document) must exist, giving XML a single "tree structure" always having a single root element at the top. A collection of compiled data starting with a root element is called an "XML Document."

Difference b/w XML & HTML
HTML XML
Extensible set of tags. No predefined tags.
Content Oriented. Presentation oriented.
Allow multiple output forms.
Single presentation.
Design to display the data with focus on how data looks.
Design to transport and store the data with focus on what data is.
HTML for humans (describe web pages).
XML for computers (describe the data).

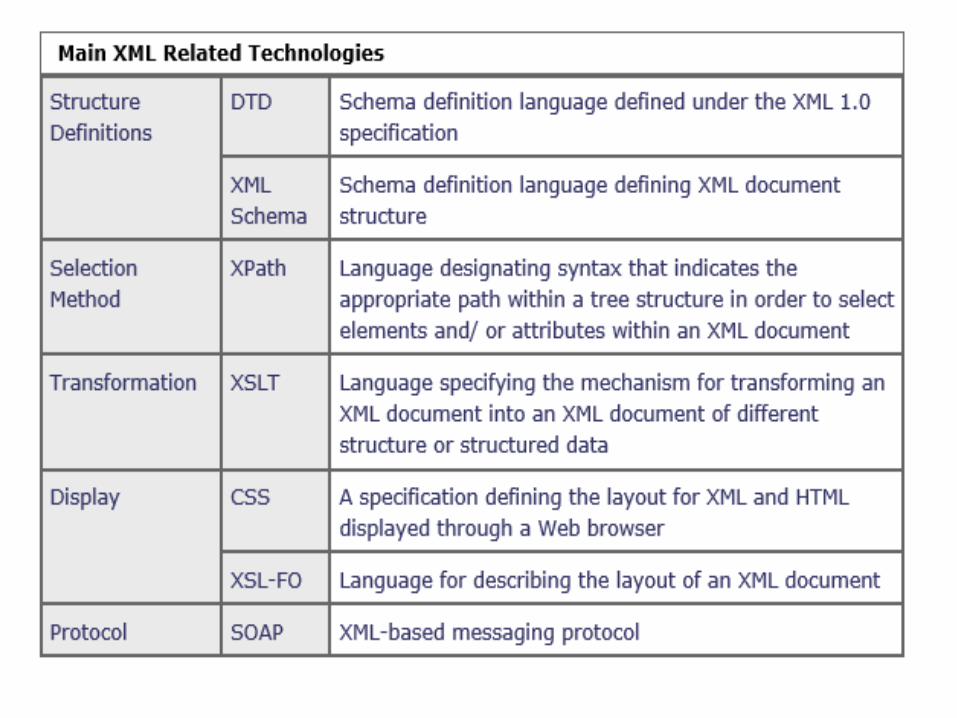
XML – related technologies•DTD (Document Type Definition) and XML Schemas are used to define legal XML tags and their attributes for particular purposes
•CSS (Cascading Style Sheets) describe how to display HTML or XML in a browser
•XSLT (eXtensible Stylesheet Language Transformations) and XPath are used to translate from one form of XML to another
•DOM (Document Object Model), SAX (Simple API for XML, and JAXP (Java API for XML Processing) are all APIs for XML parsing.

1) Extensible--XML is extensible. It lets to define own tags, the order in which they occur, and how they should be processed or displayed. Another way to think about extensibility is to consider that XML allows all of us to extend our notion of what a document is: it can be a file that lives on a file server, or it can be a transient piece of data that flows between two computer systems (as in the case of Web Services).
2) Markup-- The most recognizable feature of XML is its tags, or elements (to be more accurate). In fact, the elements create in XML will be very similar to the elements already been creating in HTML documents. However, XML allows to define own set of tags.
3) Language-- XML is a language similar to HTML. It is more flexible as it allows to create own custom tags. However, XML is not just a language. XML is a meta-language: a language that allows us to create or define other languages. For example, with XML we can create other languages, such as RSS, MathML (a mathematical markup language), and even tools like XSLT.

Need of an XML• We need XML because HTML is specifically designed to describe
documents for display in a Web browser. It becomes cumbersome if you want to display documents in a mobile device or do anything that’s even slightly complicated, such as translating the content from German to English. HTML’s sole purpose is to allow anyone to quickly create Web documents that can be shared with other people. XML, on the other hand, isn’t just suited to the Web – it can be used in a variety of different contexts, some of which may not have anything to do with humans interacting with content (for example, Web Services use XML to send requests and responses back and forth).
• HTML rarely (if ever) provides information about how the document is structured or what it means. In layman’s terms, HTML is a presentation language, whereas XML is a data-description language.

XML……….
•XML defines its own tags –
Opening the tag (<); Closing the tag (</)
e.g. <TAGNAME> student </TAGNAME>• XML tags are case sensitive.• These tags include attributes that provide additional information about the content of tag. These attribute resides within the tags:
e.g. <TAGNAME attributename =“value”> student </TAGNAME>

XML Structure• The basic structure is like:
<root> <child> <subchild>.....</subchild> </child></root>
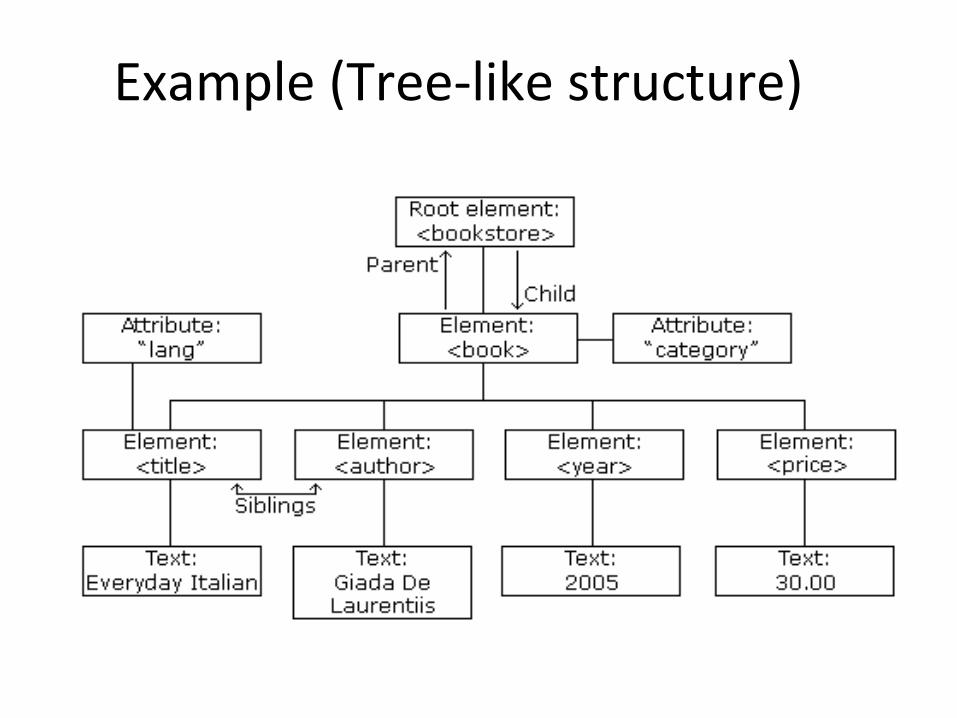
Example (Tree-like structure)

ProgrammeThis is an example if we have one book in book-store:
<bookstore> <book category="COOKING"> <title lang="en">Everyday Italian</title> <author>Giada De Laurentiis</author> <year>2005</year> <price>30.00</price> </book>

If more than one book………

XML Syntax rules• XML tags are case-sensitive.• Once the tag opened must be closed.• XML document must have root element. e.g.
<root> <child>
<subchild>.....</subchild> </child>
</root>• XML attribute value must be in quotation.• Comments in XML : <!-- This is a comment -->• XML stores a new line as LF (Line Feed).
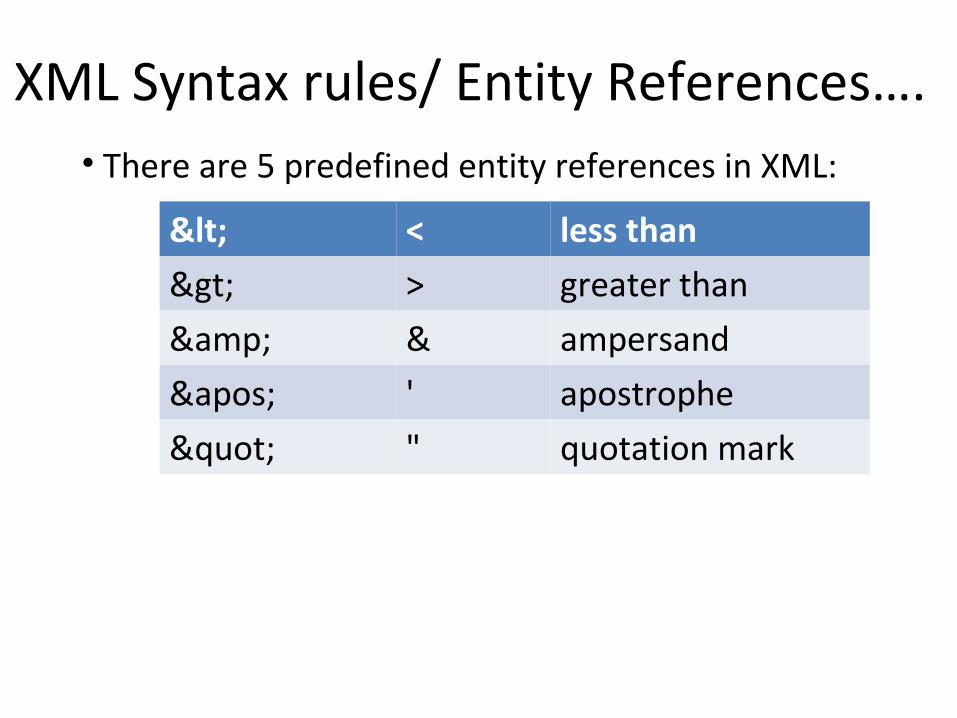
XML Syntax rules/ Entity References….• There are 5 predefined entity references in XML:
< < less than
> > greater than
& & ampersand
' ' apostrophe
" " quotation mark

XML Elements•An element can contain:
other elements, text, attributes, or a mix of all of the above...• <bookstore> <book category="CHILDREN"> <title>Harry Potter</title> <author>J K. Rowling</author> <year>2005</year <price>29.99</price> </book>• Here, <bookstore> ,<book> has element contents and <book> also has attribute while <title>,<author> , <year> contain the text contents.

XML Element - Naming rulesXML elements must follow these naming rules:• Names can contain letters, numbers, and other characters• Names cannot start with a number or punctuation character• Names cannot start with the letters xml (or XML, or Xml, etc)• Names cannot contain spaces• Any name can be used, no words are reserved• Name cannot have hyphen(-), colon(: ), termination(.) – they are reserved and have specific meaning.

XML Attribute• Attribute provide extra information about the element.• XML attribute must be quoted.• <person sex="female"> (Here, sex is an attribute) <firstname>Anna</firstname> <lastname>Smith</lastname> </person>• <person> <sex>female</sex> (Sex is an element) <firstname>Anna</firstname> <lastname>Smith</lastname></person> • Attributes are handy in HTML not in XML.

Attribute Vs Element• Attributes cannot contain multiple values (elements can)• Attributes cannot contain tree structures (elements can)• Attributes are not easily expandable (for future changes)• Attributes are difficult to read and maintain.

O:xml
• What is o:XML-- Well, it's a dynamically typed, general-purpose object-oriented programming language. It's got threads, exception handling, regular expressions, namespaces, and all the other things you would expect from a modern language. And it's expressed entirely in XML. Maybe o:XML is a bit like Python crossed with XML

Viewing XML Files
<?xml version="1.0" encoding=“mg1"?> - <note> <to>Tove</to> <from>Jani</from> <heading>Reminder</heading> <body>Don't forget me this weekend!</body> </note>
Name of file: abc.xml

Contd…..•The XML document will be displayed with color-coded root and child elements. •A plus (+) or minus sign (-) to the left of the elements can be clicked to expand or collapse the element structure. •To view the raw XML source (without the + and - signs), select "View Page Source" or "View Source" from the browser menu.

For Example---<?xml version="1.0" encoding=“a12" ?> <!-- Edited by --> + < CATLOG>Here + means it can be expanded. E.g.
<?xml version="1.0" encoding="ISO-8859-1" ?> <!-- Edited by XMLSpy® --> - <CATALOG>- <CD> <TITLE>Empire Burlesque</TITLE> <ARTIST>Bob Dylan</ARTIST> <COUNTRY>USA</COUNTRY> <COMPANY>Columbia</COMPANY> <PRICE>10.90</PRICE> <YEAR>1985</YEAR> </CD>

For example---- with multiple values

Linking With CSS (Cascading Style Sheets)<?xml version="1.0" encoding=“a12"?>
<?xml-stylesheet type="text/css" href="cd_catalog.css"?><CATALOG> <CD> <TITLE>Empire Burlesque</TITLE> <ARTIST>Bob Dylan</ARTIST> <COUNTRY>USA</COUNTRY> <COMPANY>Columbia</COMPANY> <PRICE>10.90</PRICE> <YEAR>1985</YEAR> </CD> <CD> <TITLE>Hide your heart</TITLE> <ARTIST>Bonnie Tyler</ARTIST> <COUNTRY>UK</COUNTRY> <COMPANY>CBS Records</COMPANY> <PRICE>9.90</PRICE> <YEAR>1988</YEAR> </CD></CATALOG>

CSS File –used for formatingCATALOG
{ background-color: #ffffff;
width: 100%; }
CD { display: block; margin-bottom: 30pt; margin-left: 0; }
TITLE { color: #FF0000; font-size: 20pt; }
ARTIST { color: #0000FF; font-size: 20pt; } COUNTRY,PRICE,YEAR,COMPANY
{ display: block; color: #000000; margin-left: 20pt; }

With CSS program appear like this….

Editor for creating XML programme• Notepad•WWW Consortium’s browser and editor
( A complete development environment for XML and many child languages)
http://www.w3.org/User/BinDist.html• http://www.softsquad.com (XMetaL)• http://www.extensiblity.com/products/xml_authority.htm

Parsers to run XML programme• Two types of parsers are there: Nonvalidating; Validating• Non validating are the simplest; used to check for well- formedness with in XML document.• Nonvalidting parsers donot ensure that all of your XML tags are proper.• IE version 5 has built-in parser that checks for well- formedness without validaing the actual XML code.• Validating parsers with checking the well-formedness also verifies the conforms to a specific to external or internal DTD.

• Parsing is splitting up information into its component parts.
• In computing, a parser is a program (or a piece of code or API that you can reference inside your own programs) which analyses files to identify the component parts. All applications that read input have a parser of some kind, otherwise they'd never be able to figure out what the information means.
• XML applications contain a parser which reads XML and identifies the function of each the pieces of the document, and it then makes that information available in memory to the rest of the program

• While reading an XML file, a parser checks the syntax (pointy brackets, matching quotes, etc) for well-formedness, and reports any violations (reportable errors). The XML Specification lists what these are.
Well-formed XML:- 1. All tags must be balanced.
2. All attribute values must be in quotes.
3. Any EMPTY elements must either end with /> or they must look like non-EMPTY elements by having a real end-tag. e.g. <br> would become either <br/> or <br></br> (with nothing in between).
4. Elements must nest inside each other properly .
5. DTDless well-formed documents may use attributes on any element, but the attributes are all assumed to be of type CDATA.

• Validation is another stage beyond parsing. As the component parts of the program are identified, a validating parser can compare them with the pattern laid down by the DTD or Schema, to check that they conform. In the process, default values and data-types (if specified) can be added to the in-memory result of the validation that the validating parser gives to the application.
http://xml.silmaril.ie

XML DATA
XML data considered as PCDATA and CDATA.
Parsed Character Data(Unparsed) Character data

PCDATA --XML• PCDATA is termed used to show the text data which will be parsed by XML parser.• <name> -----example <first>Bill</first> <last>Gates</last></name>• when XML element is parsed, its data also parsed.

XML ---CDATA (Unparsed)• “<“ and “&” symbols perform illegal function in XML.• Parser treats “<“ -- as starting of a new element.• Parser treats “&” as start of new character entity.• If we write anything in CDATA section—it is ignored by parser.• A CDATA section starts with "<![CDATA[" and ends with "]]>“. • Nested CDATA is not permissible.• The "]]>" that marks the end of the CDATA section and cannot contain spaces or line breaks.

Script using CDATA<script><![CDATA[function match(a,b){if (a < b && a < 0) then { return 1; }else { return 0; }}]]></script>

PCDATA and CDATA
• CDATA and PCDATA are concepts while CDATA and #PCDATA are keywords. CDATA keyword is an attribute type and may also be used in element sections, but it is not considered wise. #PCDATA keyword can just be used in element section. As far as I understand both CDATA and #PCDATA keywords denote just plain text.

• In PCDATA text, the tags inside the text will be treated as markup and entities will be expanded, where as in CDATA, text will NOT be parsed by the XML parser.
• PCDATA stands for Parsed Character Data. That means the characters are to be parsed by the XML, XHTML, or HTML parser. (< will be changed to <, <p> will be taken to mean a paragraph tag, etc). Compare that with CDATA, where the characters are not to be parsed by the XML, XHTML, or HTML parser.
• The term CDATA, meaning character data, is used for distinct, but related purposes in the markup languages SGML and XML. The term indicates that a certain portion of the document is general character data, rather than non-character data or character data with a more specific, limited structure.

• A CDATA section cannot contain the string "]]>" and therefore it is not possible for a CDATA section to contain nested CDATA sections. The preferred approach to using CDATA sections for encoding text that contains the triad "]]>" is to use multiple CDATA sections by splitting each occurrence of the triad just before the ">". For example, to encode "]]>" one would write:
<![CDATA[]]]]><![CDATA[>]]>• This means that to encode "]]>" in the middle of a CDATA
section, replace all occurrences of "]]>" with the following:• ]]]]><
DTD (Document Type Definition)

DTD •The purpose of a DTD (Document Type Definition) is to define the legal building blocks of an XML document.•It defines the document structure with a list of legal elements and attributes.•A DTD can be declared inline inside an XML document, or as an external reference.

Building Block of XML Document..DTD
• Elements• Attributes• Entities• PCDATA• CDATA

How to declare an element in DTD
• In a DTD, elements are declared with an ELEMENT declaration.• Syntax is:
<!ELEMENT element-name (element-content)> • Elements with parsed character data is defined as:
<!ELEMENT element-name (#PCDATA)>• Elements with empty element declared as:
<!ELEMENT element-name EMPTY>• Elements with children declared as:
<!ELEMENT element-name (child1,child2,...)>

How to declare an attribute in DTD•Attributes are declared with an ATTLIST declaration.• Syntax is: <!ATTLIST element-name attribute-name
attribute-type default-value>• attribute-type can be any one of the following:
Type Description
CDATA The value is character data
ID The value is a unique id
ENTITY The value is an entity
ENTITIES The value is a list of entities
NMTOKEN The value is a valid xml name
xml: The value is a predefined xml value

• Default-value can be any one of the following:
1.With Default - attribute value:
DTD:<!ELEMENT square EMPTY><!ATTLIST square width CDATA "0"> -----default value
2.With #required value: syntax is------
<!ATTLIST element-name attribute-name attribute-type #REQUIRED>-------used when we want attribute to be present
3. With #Fixed syntax is-----
<!ATTLIST element-name attribute-name attribute-type #FIXED "value"> -------Value is fixed-----cannot change---
Value Explanation
Value The default value of the attribute
#REQUIRED The attribute is required
#IMPLIED The attribute is not required
#FIXED value The attribute value is fixed

Enumerated attribute value•Use enumerated attribute values when you want the attribute value to be one of a fixed set of legal values.•Syntax is:-<!ATTLIST element-name attribute-name (en1|en2|..) default-value> • for example:-
DTD:<!ATTLIST payment type (check|cash) "cash">
XML example:<payment type="check" />
or<payment type="cash" />

Internal DTD Declaration
•If the DTD is declared inside the XML file, it should be wrapped in a DOCTYPE definition with the following syntax:
<!DOCTYPE root-element [element-declarations]>

XML program using internal DTD<?xml version="1.0"?><!DOCTYPE note [<!ELEMENT note (to,from,heading,body)><!ELEMENT to (#PCDATA)><!ELEMENT from (#PCDATA)><!ELEMENT heading (#PCDATA)><!ELEMENT body (#PCDATA)>]><note><to>abc</to><from>xyz</from><heading>Reminder</heading><body>Don't forget me this weekend</body></note>

DTD…..The DTD above is interpreted like this:
!DOCTYPE note defines that the root element of this document is note
!ELEMENT note defines that the note element contains four elements: "to,from,heading,body"
!ELEMENT to defines the to element to be of type "#PCDATA"
!ELEMENT from defines the from element to be of type "#PCDATA"
!ELEMENT heading defines the heading element to be of type "#PCDATA"
!ELEMENT body defines the body element to be of type "#PCDATA"

External DTD Declaration
If the DTD is declared in an external file, it should be wrapped in a DOCTYPE definition with the following syntax:
<!DOCTYPE root-element SYSTEM "filename">

XML programme with external DTD

Hence…….DTD
•With a DTD, each of XML files can carry a description of its own format.•With a DTD, independent groups of people can agree to use a standard DTD for interchanging data.•An application can use a standard DTD to verify that the data receive from the outside world is valid.•We can also use a DTD to verify our own data.

DTD---Entities• Entities are variables used to define shortcuts to standard text or special characters.• Entity references are references to entities.• Entities can be declared internal or external.• An entity has three parts: an ampersand (&), an entity name, and a semicolon (;).• Declaration of an internal entity:
<!ENTITY entity-name "entity-value">
e.g.-
In DTD: <!ENTITY writer "Donald Duck."><!ENTITY copyright "Copyright Warnier Brother">
In XML :
<author>&writer;©right;</author>

• Declaration of an external entity:
Syntax is: <!ENTITY entity-name SYSTEM "URI/URL">
• For example:
In DTD: <!ENTITY writer SYSTEM "http://www.abc.com/entities.dtd"><!ENTITY copyright SYSTEM "http://www.abc.com/entities.dtd">
In XML: <author>&writer;©right;</author>

DTD (Document Type Definition)<!DOCTYPE NEWSPAPER [<!ELEMENT NEWSPAPER (ARTICLE+)><!ELEMENT ARTICLE (HEADLINE,BYLINE,LEAD,BODY,NOTES)><!ELEMENT HEADLINE (#PCDATA)><!ELEMENT BYLINE (#PCDATA)><!ELEMENT LEAD (#PCDATA)><!ELEMENT BODY (#PCDATA)><!ELEMENT NOTES (#PCDATA)> <!ATTLIST ARTICLE AUTHOR CDATA #REQUIRED><!ATTLIST ARTICLE EDITOR CDATA #IMPLIED><!ATTLIST ARTICLE DATE CDATA #IMPLIED><!ATTLIST ARTICLE EDITION CDATA #IMPLIED>]>
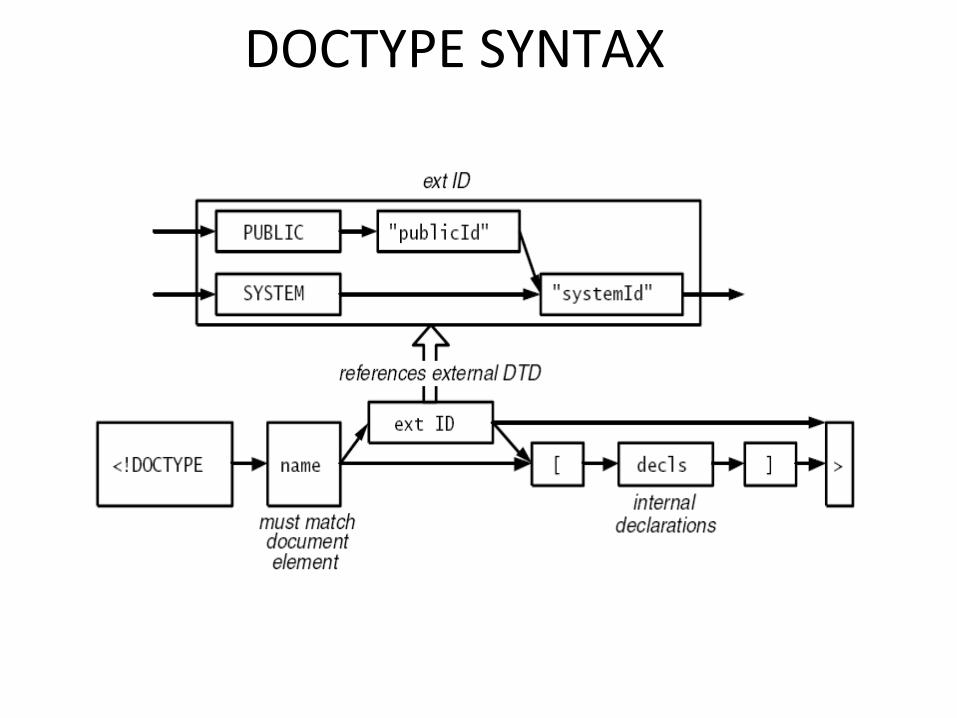
DOCTYPE SYNTAX

For the Internal declaration DTD:-•The simplest way to define a DTD is through internal declarations. •In this case, all declarations are simply placed between the open/close square brackets.
e.g. <!DOCTYPE person [
<!-- internal subset -->
<!ELEMENT person (name, age)>
<!ELEMENT name (#PCDATA)
<!ELEMENT age (#PCDATA)> ]>
<person>
<name>Billy Bob</name>
<age>33</age>
</person>• External DTD declaration is useful because it allows you to reuse the déclarations in multiple document instances.

ENTITY• Entities are the most atomic unit of information in XML. •Entities are used to construct logical XML documents (as well as DTDs) from physical resources.• An XML document that contains a DOCTYPE declaration is known as the document entity.•There are several other types of entities, each of which is declared using an ENTITY declaration. •A given entity is either general or parameter, internal or external, and parsed or unparsed.• General versus parameter entities:
General Entity may only be referenced in an XML document (not the DTD).
Parameter Entity may only be referenced in a DTD (not the XML document).

•Internal versus external entities:
•Parsed versus unparsed entities:
•All of these are declared using an ENTITY declaration.
Internal Entity value defined inline.
External Entity value contained in an external resource.
Parsed Entity value parsed by a processor as XML/DTD content.
Unparsed Entity value not parsed by XML processor.
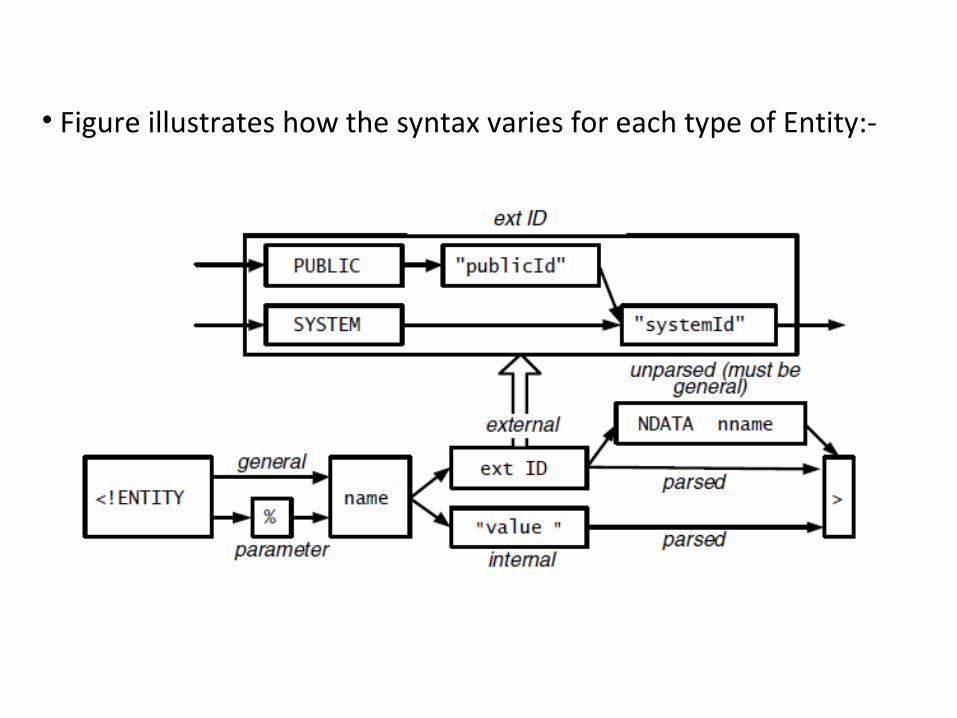
• Figure illustrates how the syntax varies for each type of Entity:-

ENITITY…..•As we can see from Figure, unparsed entities are always general and external whereas parameter/internal entities are always parsed.• In reality, there are only five distinct entity types (besides the document entity), which are:
• Although the syntax for external entities only shows using a system identifier, public identifiers may also be used as shown in Figure .
Syntax Description
<!ENTITY % name "value"> Internal parameter
<!ENTITY % name SYSTEM "systemId"> External parameter
<!ENTITY name "value"> Internal general
<!ENTITY name SYSTEM "systemId"> External parsed general
<!ENTITY name SYSTEM "systemId" NDATA nname> Unparsed

How Entities can be referenced?
Syntax Description
&name; General
%name; Parameter
Name is used as the value of an attribute of type ENTITY or ENTITIES
Unparsed

Conditional Statements: INCLUDE and IGNORE
•The Syntax is:
<![INCLUDE[
...
]]>
<![IGNORE[
...
]]>• They may be used to control what declarations are processed as part of the DTD at a given point in time.• Declarations within INCLUDE blocks are included in the DTD where as declarations within IGNORE blocks are ignored.

Example………

NOTATION• <!NOTATION name PUBLIC "publicId">• <!NOTATION name PUBLIC "publicId" "systemId">• <!NOTATION name SYSTEM "systemId">• Notation declarations associate a name with a type identifier, which can be either a public or a system identifier. • The actual type identifiers are application specific, although it’s common to see MIME types used within public identifiers. • Unparsed entities are associated with notation names to associate type with the referenced binary resource.

XML Name Spaces

XML Namespaces• Goal of XML namespace was to create a mechanism in which a single document can use elements and attributes.• It works by adding a prefix to the names of elements and attributes so that each attribute is associated with its originating document. • XML Namespaces provide a method to avoid element name conflicts.• A namespace act as a scope for all elements associated with it.• A namespace name is a URI.• The namespace and local name of an element together form a unique name known as qualified name.• The syntax of namespace is:
xmlns: prefix = ‘URI’ …………using prefix

Example………

• Also we can write it as…
<rootxmlns:h="http://www.w3.org/TR/html4/"xmlns:f="http://www.w3schools.com/furniture"><h:table> <h:tr> <h:td>Apples</h:td> <h:td>Bananas</h:td> </h:tr></h:table><f:table> <f:name>African Coffee Table</f:name> <f:width>80</f:width> <f:length>120</f:length></f:table></root> When a namespace is defined for an element, all child elements with the same prefix are associated with the same namespace.

XML Schema

• An XML Schema describes the structure of an XML document.• XML Schema provides a set of built-in data types. Some of these types are primitives, described in the specification, whereas others are derived types described in a schema.• In all examples, the xs namespace prefix is mapped to the namespace name of the XML schema language.• Similarly, the tns namespace prefix is mapped to the same namespace name as the target Namespace attribute of the schema
element even if that element is not shown.
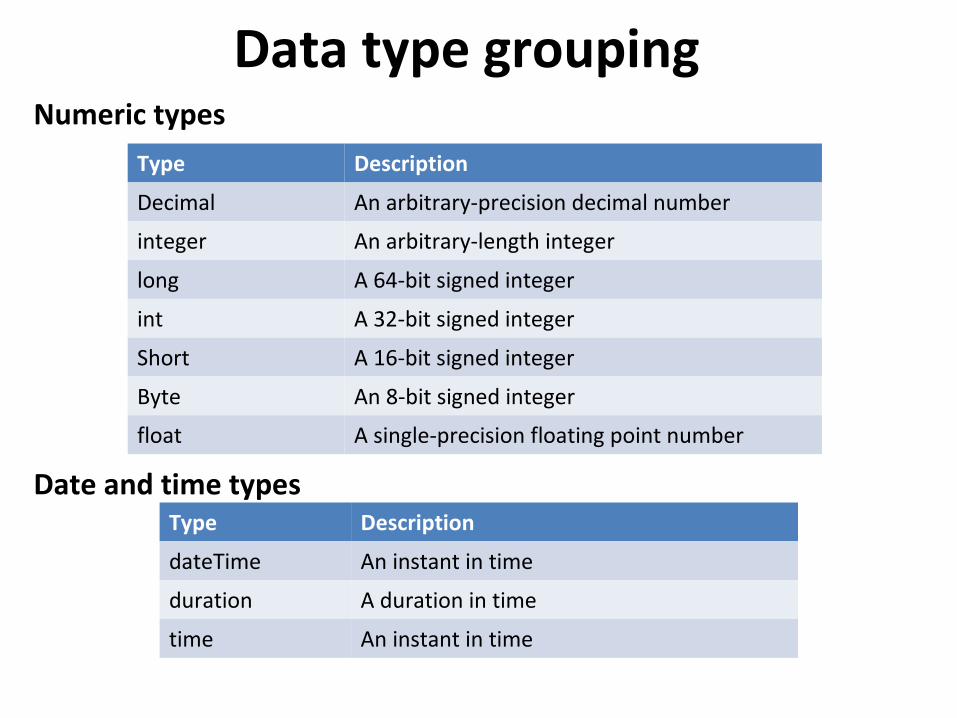
Data type groupingNumeric types
Date and time types
Type Description
Decimal An arbitrary-precision decimal number
integer An arbitrary-length integer
long A 64-bit signed integer
int A 32-bit signed integer
Short A 16-bit signed integer
Byte An 8-bit signed integer
float A single-precision floating point number
Type Description
dateTime An instant in time
duration A duration in time
time An instant in time
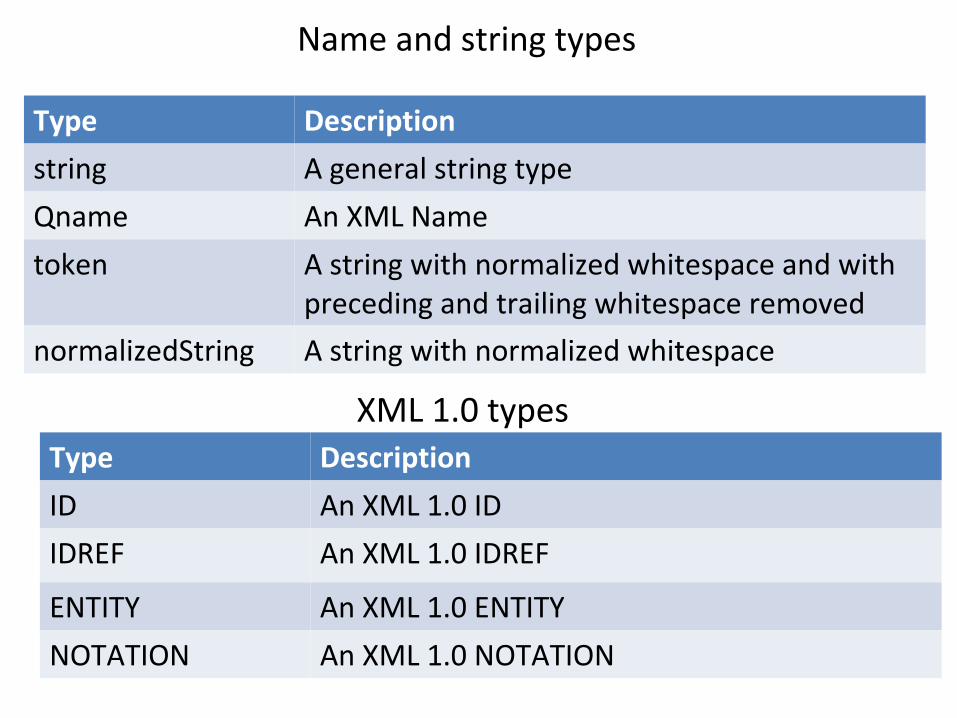
Name and string types
Type Description
string A general string type
Qname An XML Name
token A string with normalized whitespace and with preceding and trailing whitespace removed
normalizedString A string with normalized whitespace
XML 1.0 typesType Description
ID An XML 1.0 ID
IDREF An XML 1.0 IDREF
ENTITY An XML 1.0 ENTITY
NOTATION An XML 1.0 NOTATION

Datatypes
•Datatypes in the XML Schema specification are defined in terms of a value space, the set of values the type can hold, and a lexical space. •We can say that, how those values are represented as characters in XML. •Some datatypes have multiple lexical representations whereas others only have one.
Some datatypes are:----

anyURIThe anyURI datatype represents a URI reference according to RFC 2396 and RFC 2732. (See References at the end of the chapter.)
Value space:
Any absolute or relative URI reference including those with a fragment identifier.
Lexical space:
The set of strings matching the URI reference production of RFC 2396, as amended by RFC 2732.
Applicable facets:
enumeration, length, maxLength, minLength, pattern, and whiteSpace
.

base64BinaryThe base64Binary datatype represents base64-encoded binary data.
Value space:
Any finite sequence of binary octets.
Lexical space:
Any finite sequence of binary octets encoded according to
the Base64 Content-Transfer-Encoding per RFC 2045.
Applicable facets:
enumeration, length, maxLength, minLength, pattern and
whiteSpace.
Note:- A prime number sequence for the numbers 1, 2, 3, 5, 7, 9, 11, 13, 17, and 19 encoded in base64.

byteThe byte datatype represents the range of integer values that can be stored in an 8-bit signed field.
Base type: short.
Value space: +127 to –128.
Lexical space: A finite sequence of decimal digits with an optional leading sign character (+ or –). The default sign is positive. Leading zeros may appear.
Canonical representation: Leading zeros are prohibited, as is the preceding + sign.
Applicable facets: enumeration, fractionDigits, maxExclusive, maxInclusive, minExclusive, minInclusive, pattern, totalDigits, and whiteSpace.

boolean
The boolean datatype represents two-value logic.
Value space: true, false.
Lexical space: true, false, 1, 0 (where 1 and 0 correspond to true and false respectively).
Canonical representation: true, false.
Applicable facets: pattern and whiteSpace.

dateThe date datatype represents a Gregorian calendar date.
Value space:
Any date.
Lexical space:
CCYY-MM-DD where CC, YY, MM, and DD correspond to the century, year, month, and day respectively. Additional digits may appear to the left of CC to indicate years greater than 9999.
Applicable facets:
enumeration, maxExclusive, maxInclusive,
minExclusive, minInclusive, pattern, and whitespace.

decimalThe decimal datatype represents arbitrary precision decimal numbers.
Value space: The infinite set of all decimal numbers.
Lexical space: A finite sequence of decimal digits with a period as the decimal point indicator and an optional leading sign character (+ or –). The default sign is positive. Leading and trailing zeros may appear. If the digits following the decimal point are all zero, those digits and the decimal point may be omitted.
Applicable facets: enumeration, fractionDigits, maxExclusive,
maxInclusive, minExclusive, minInclusive, pattern, totalDigits, and whiteSpace.
Derived type: integer.

ENTITIESThe ENTITIES datatype represents the XML 1.0 ENTITIES type, a list of ENTITY names separated by whitespace. This type should only be used for attribute values.
A given ENTITY value in the list must match the name of an unparsed entity declared elsewhere in the XML document.
Base type: ENTITY
Derived by: list
Value space: The set of finite, nonzero-length sequences of ENTITY values that have been used in an XML document.
Lexical space: The set of whitespace-separated lists of ENTITY values that have been used in an XML document.
Applicable facets: enumeration, length, maxLength, minLength,
and whiteSpace.
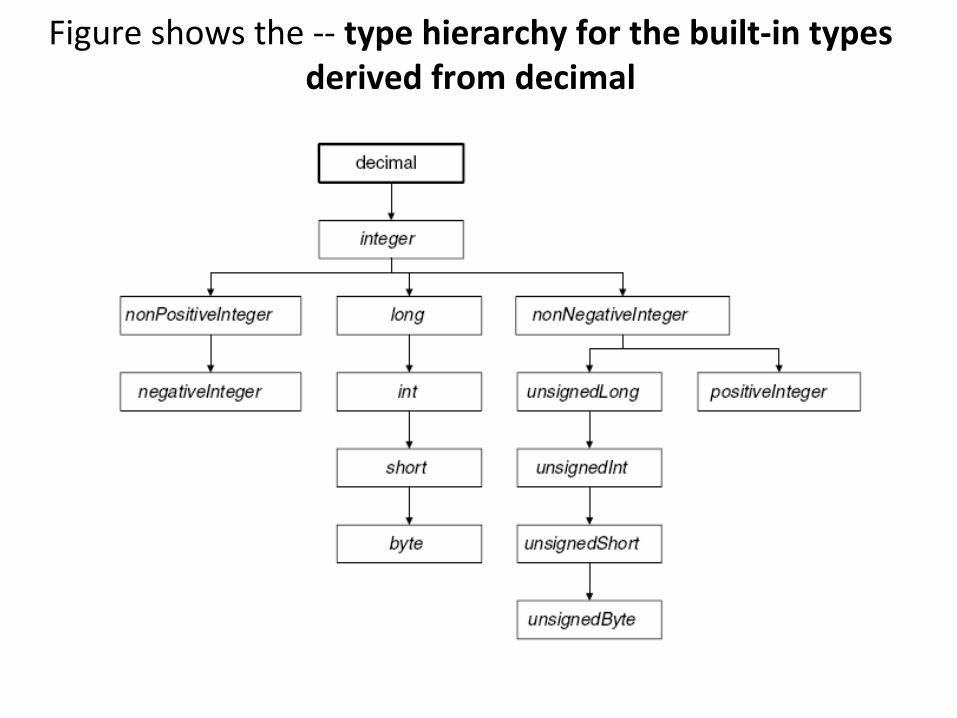
Figure shows the -- type hierarchy for the built-in types derived from decimal
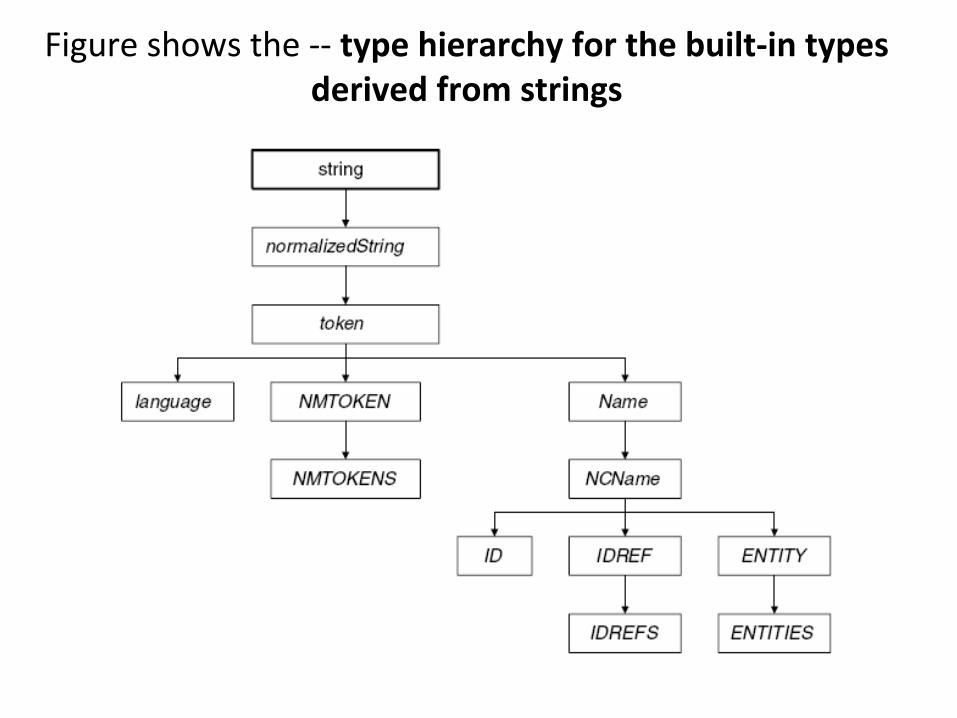
Figure shows the -- type hierarchy for the built-in types derived from strings

XML Schema
The purpose of an XML Schema is to define the legal building blocks of an XML document, just like a DTD.
An XML Schema: defines elements that can appear in a document defines attributes that can appear in a document defines which elements are child elements defines the order of child elements defines the number of child elements defines whether an element is empty or can include text defines data types for elements and attributes defines default and fixed values for elements and attributes

XML Schemas are the Successors of DTDs
Here are some reasons:•XML Schemas are extensible to future additions•XML Schemas are richer and more powerful than
DTDs•XML Schemas are written in XML•XML Schemas support data types•XML Schemas support namespaces

XML Schemas Support Data Types
•It is easier to describe allowable document content.•It is easier to validate the correctness of data.•It is easier to work with data from a database.•It is easier to define data facets (restrictions on data).•It is easier to define data patterns (data formats).•It is easier to convert data between different data types.

Facets
•Facets are used to restrict the set of values a data type.•The new value range must be equal to or narrower than the value range of the base type.• It is not possible to expand the value space of a type using facets.•There are 12 facet elements.• Attribute is of type xs:string, the value must typically be a valid value of the type to which the facet is applied.

FACETSe.g. minExclusive facet is being used to constrain the decimal datatype then the value must be numerical.
The facets are listed in alphabetical order:
Enumeration, fractionDigits, length, maxExclusive, maxInclusive, maxLength, minLength, pattern, totaldigits, whitespace

enumeration•<xs:enumeration value='string' fixed='boolean' id='ID' />•Defines a fixed value that the type must match. Multiple enumeration facets can be used to specify multiple legal values. Thus, multiple enumeration facets have a cumulative effect, allowing multiple possible values.•Values: Any value that matches the type of the base type.•Applies to: anyURI, base64Binary, byte, date, dateTime, decimal,•double, duration, ENTITIES, ENTITY, float, gDay, gMonth,•gMonthDay, gYear, gYearMonth, hexBinary, ID, IDREF, IDREFS,•int, integer, language, long, Name, NCName, negativeInteger,•NMTOKEN, NMTOKENS, nonNegativeInteger, nonPositiveInteger,•normalizedString, NOTATION, positiveInteger, QName, short, string, time, token,.





























