Embed Size (px)
Citation preview

1
HBASE: overview
Jean-Baptiste PoulletConsultant @Stat'Rgy

2
Contents
● What is HBase ?● HBase vs RDBMS (like MySQL or PostgreSQL)● Backup ? CRUD operations ? ACID compliant ?● Hardware/OS ● HBase DB Design● UI ? Let's make a demo.

3
What is HBase ?
● Wikipedia definition: HBase is an open source, non-relational, distributed database modeled after Google's BigTable and written in Java. It is developed as part of Apache Software Foundation's Apache Hadoop project and runs on top of HDFS (Hadoop Distributed Filesystem), providing BigTable-like capabilities for Hadoop. That is, it provides a fault-tolerant way of storing large quantities of sparse data (small amounts of information caught within a large collection of empty or unimportant data, such as finding the 50 largest items in a group of 2 billion records, or finding the non-zero items representing less than 0.1% of a huge collection).

4
HBase is used by the largest companies

5
HBase featuresNo real indexes
● Rows are stored sequentially, as are the columns within each row. Therefore, no issues with index bloat, and insert performance is independent of table size.
●
● Automatic partitioning● As your tables grow, they will automatically be split into regions and distributed across all available nodes.●
● Scale linearly and automatically with new nodes● Add a node, point it to the existing cluster, and run the regionserver. Regions will automatically rebalance and load will spread evenly.●
● Commodity hardware● Clusters are built on $1,000–$5,000 nodes rather than $50,000 nodes. RDBMSs are I/O hungry, requiring more costly hardware.●
● Fault tolerance● Lots of nodes means each is relatively insignificant. No need to worry about individual node downtime.●
● Batch processing● MapReduce integration allows fully parallel, distributed jobs against your data with locality awareness.

6
HBase vs RDBMS
Why should I migrate to HBase ? ● Scalability / dealing with sparse matrix
– In RDBMS, NULL cells need to be set and occupy space
– In HBase, NULL cells are simply not stored
When ? If you stay up at night worrying about your database (uptime, scale, or speed), then you should seriously consider making a jump from the RDBMS world to HBase.
How ?● ETL (sqoop, scalding/cascading, scala, python, BI ETL, etc)

7
CRUD operations in HBaseCRUD operations for many clientsSingle-row transactions (multiple-row transactions are possible since version 0.94 if the rows are on the same region server)Select columns and version possibleAtomic read-modify-write on data stored => concurrent access is not an issueCo-processors are equivalent to stored-procedures in RDBMS
allow to push user code in the address space of the server access to server local data implement lightweight batch jobs, data pre-processing, data summarization
HFile is persistent and ordered immutable maps from key to valueDeleting data: a delete marker (tombstone marker) is written to indicate that a given key is deleted. In the READ process data marked as deleted are skipped.DDI: Stands for Denormalization, Duplication and Intelligent Keys• Denormalization : replacement for JOINs• Duplication : Design for reads• Intelligent Keys : Implement indexing and sorting, optimize reads

8
Is HBase ACID ?
● ACID = Atomicity, Consistency, Isolation, and Durability● HBase guarantees:
– Atomic: All row level operations within a table are atomic. This guarantee is maintained even when there’s more than one column family within a row.
– Consistency: Scan operations return a consistent view of the data stored in HBase at some point in the past. Concurrent client interaction could update a row during a multi-row scan, but all rows returned by a scan operation will always contain valid data from some point in the past.
– Durability: Any data that can be retrieved from HBase has also been made durable to disk (persisted to HDFS, in other words).
–
When ACID properties are required by HBase clients, design the HBase schema such that cross row or cross table data operations are not required. Keeping data within a row provides atomicity.

9
HBase cluster – Failure Candidates
● Data Center: geo distributed data● Cluster: avoid redundant cluster, rather have one big cluster with high redundancy● Rack: Hadoop has built-in rack awareness● Network Switch: redundant network within each node● Power Strip: redundant power within each node● Region Server or Data Node: can be added/removed dynamically for regular
maintenance => need of a replication factor of 3 or 4● Zookeeper Node: Zookeeper nodes are distributed and can be added/removed
dynamically, must be in odd number due to the quorum (Best practices: 5 or 7)● HBase Master or Name Node: Multiple Hmaster (Best practices: 2-3, 1 per rack)

10
Backup built-in
● HBase is highly distributed and has built-in versioning, data retention policy
– No need to backup just for redundancy– Point-in-time restore:
● Use TTL/Table/CF/C and keep the history for X hours/days– Accidental deletes:
● Use 'KeepDeletedCells' to keep all deleted data
HDFS is a key enabling technology not only for Hadoop but also for HBase. Bystoring data in HDFS, HBase offers reliability, availability, seamless scalability,high performance and much more — all on cost effective distributed servers.

11
Backup - Tools
● Use export/import tool:– Based on timestamp; and use it for point-in-time backup/restore
● Use region snapshots– Take HFile snapshots and copy them over to new storage
location– Copy Hlog files for point-in-time roll-forward from snapshot time
(replay using WALPlayer post import)● Table snapshots (0.94.6+)

12
Hardware/Disk/OS best practices
● 1U or 2U preferred, avoid 4U or NAS or expensive systems● JBOD on slaves, RAID 1+0 on masters ● No SSDs, No virtualized storage● Good number of cores (4-16), HyperThreading enabled on CPUs● Good amount of RAM (24-72G)● Dual 1G network, 10G or InfiniBand● SATA, 7/10/15K, the cheaper the better● Use RAID firmware drives, faster error detection and enable disk to fail on hardware errors● Ext3/Ext4/XFS● RHEL or CentOS or Ubuntu● Swappiness=0 and no swap files● Automation with Puppet (e.g. for deploying an HBase cluster) and Fabric (e.g. for deploying new HBase
release with zero downtime)

13
Alerting system
● Need proper alerting system– JMX exposes all metrics– Ops Dashboards (Ganglia, Cacti, OpenTSDB, NewRelic)– Small Dashboard for critical events– Define proper level for escalation– Critical
● Loosing a Master or ZooKeeper Node● +/- 10% drop in performance or latency● Key thresholds (load,swap,IO)● Loosing 2 or more slave nodes ● Disk failures ● Unbalanced nodes● FATAL errors in logs

14
Tables in HBase
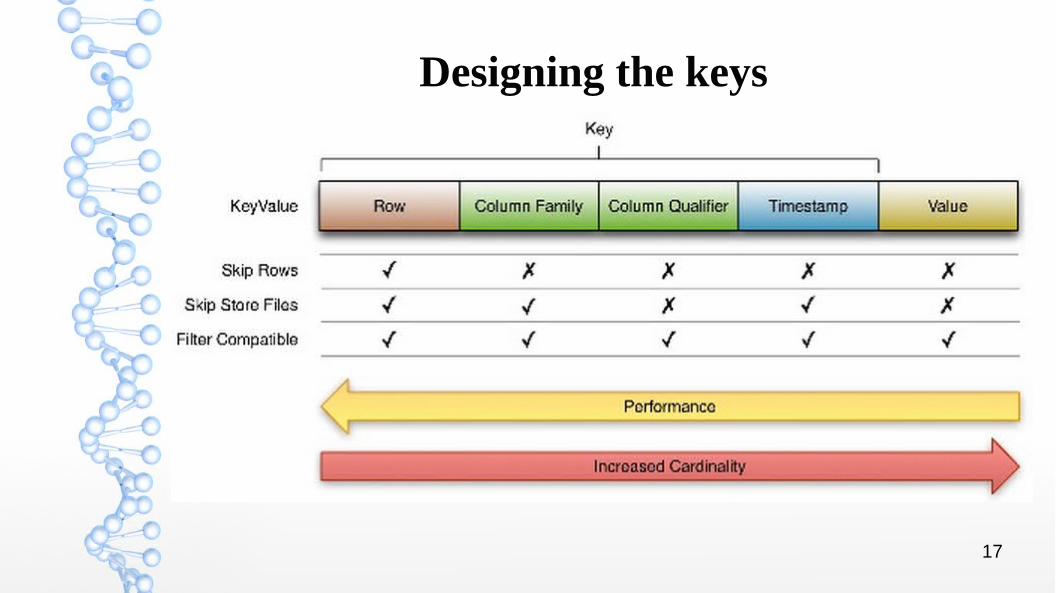
• Tables are sorted by Row in lexicographical order• Table schema only defines its column families
• Each family consists of any number of columns • Each column consists of any number of versions• Columns only exist when inserted, NULLs are free• Columns within a family are sorted and stored together• Everything except table name are byte
KeyValue:(Table, Row, Family:Column, Timestamp) -> Value
KeyValue instances are not split across blocks. For example, if there is an 8 MB KeyValue, even if the block-size is 64kb this KeyValue will be read in as a coherent block. For more information, see the KeyValue source code.
The KeyValue format inside a byte array is: • keylength• valuelength• key• value
The Key is further decomposed as: • rowlength• row (i.e., the rowkey)• columnfamilylength• columnfamily• columnqualifier• timestamp• keytype (e.g., Put, Delete,
DeleteColumn, DeleteFamily)

15
What about the schema design ?
Schema design is a combination of • Designing the keys (rows and columns)• Segregate data into column families• Choose compression and block sizes
CONFIG file: conf/hbase-site.xml

16
Designing the keys: READ or WRITE design
Sequential keys ([timestamp]) would be more appropriate for BridgeIris since the writing process can be done in a batch modeInteractive queries require a fast access to the data.
Risk of hotspotting on regions when continous writing (ok ifBulk loads instead)
17
Designing the keys

18
Designing keys• Tall-Narrow Tables (many rows, few columns) vs Flat-Wide Tables (few rows,
many columns) Tall-Narrow is recommended Store part of the cell data in the row key
• Rows do not split => avoid too large rows.
• Dimensions that are queried together in the same column family since those columns will be stored in the same low-level storage file (HFile on HDFS)
• Atomicity on row level => not an issue in BrideIris: we can build row/column key such that we don’t need several rows to be updated in a row.

19
What about the cluster and HBase config ?
• Data node and region server should be co-located. Same cluster • Replication: at least 3 => OK with HDFS • Too many or too small regions are not good.
• When does a region split ? Region size ? Keep default or set to 1 GB• Store larger than hbase.hregion.max.filesize (HBase v0.94 used by EMR: 10GB) after a
major compaction, for a 10 node cluster it is better to have 10 regions of 0.4 GB than one big of 4 GB. But too many will generate an overhead in memory (MSLAB requires 2MB per family per region).
• How is the region assigned to a region server ? Keep default– Automated to insure a balance between the region servers (manual command in HBase
shell: balance_switch, hbase.balancer.period property)
• What is the best block size ? Keep default– The block size can be configured for each column family (default 64 kb). – Column families can be defined in memory (quick read access) => are there columns that
will be almost always requested by the user ???
• Should blocks be compressed ? How ? No compression and Snappy if needed
– Compression is possible for each column family. GZIP (built in), SNAPPY (to be installed on all nodes). GZIP better compression but slower. If compression, SNAPPY would be more appropriate

20
Benchmark is a key
● Nothing fits for all● Simulate use cases and run the tests:
– Bulk loading – Random access, read/write– Batch processing– Scan, filter
● Negative performance– Replication factor– Zookeeper nodes– Network latency– Slower disks, CPUs– Hot regions, Bad row keys or Bulk loading without pre-splits
21
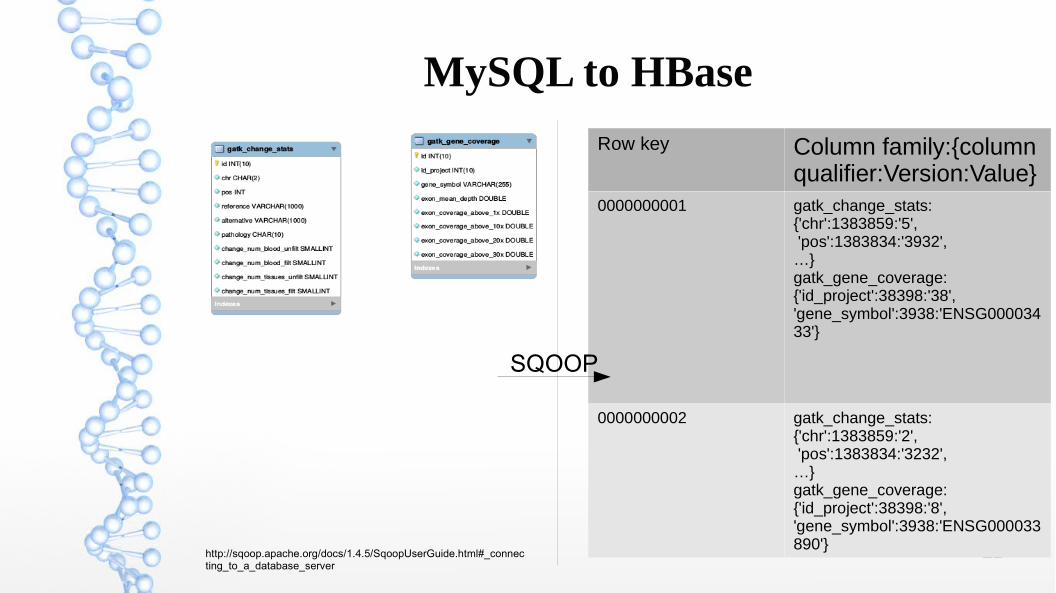
MySQL to HBase
Row key Column family:{column qualifier:Version:Value}
0000000001 gatk_change_stats:{'chr':1383859:'5', 'pos':1383834:'3932',…}gatk_gene_coverage:{'id_project':38398:'38','gene_symbol':3938:'ENSG00003433'}
0000000002 gatk_change_stats:{'chr':1383859:'2', 'pos':1383834:'3232',…}gatk_gene_coverage:{'id_project':38398:'8','gene_symbol':3938:'ENSG000033890'}
SQOOP
http://sqoop.apache.org/docs/1.4.5/SqoopUserGuide.html#_connecting_to_a_database_server
22
Some demo ...

23
Thanks !











![SCID II es Young sema 20141003 [Kompatibilis mód]](https://img.dokumen.tips/doc/110x75/58679ecc1a28ab52568b884b/scid-ii-es-young-sema-20141003-kompatibilis-mod.jpg)

















