Embed Size (px)
Citation preview

Zahid Mian Part of the Brown-bag Series
Core Technologies
HDFS
MapReduce
YARN
Spark
Data Processing
Pig
Mahout
Hadoop Streaming
MLLib
Security
Sentry
Kerberos
Knox
ETL
Sqoop
Flume
DistCp
Storm
Monitoring Ambari
HCatalog
Nagios
Puppet
Chef
ZooKeeper
Oozie
Ganglia
Databases Cassandra
HBase
Accumulo
Memcached
Blur
Solr
MongoDB
Hive
SparkSQL
Giraph

Hadoop Distributed File System (HDFS) Runs on clusters of inexpensive disks Write-once data Stores data in blocks across multiple disks NameNode responsible for managing
metadata about the actual data Linux-like CLI for management of files Since it’s Open Source, customization is
possible

Solving computations by breaking everything into Map or Reduce jobs
Input and output of jobs is always in Key/Value pairs Map Input might be a line from a file <LineNumber, LineText>:
<224, “Hello World. Hello World”> Map Output might be instance of each word:
<“Hello”, 1>, <“World”, 1>, <“Hello”, 1>, <“World”, 1> Reduce input would be the output from the Mapper Reduce output might be the count of occurrence of each word:
<“Hello”, 2>, <“World”, 2> Generally MapReduce jobs are written in Java Internally Hadoop does a lot of processing to make this seemless All data stored in HDFS (except log files)

Yet Another Resource Negotiator By itself not much Allows a variety of tools to conveniently run
within the Hadoop cluster (MapReduce, Hbase, Spark, Storm, Solr, etc.)
Think of YARN as the operating system for Hadoop
Users generally interact with individual tools within YARN rather than directly with YARN

MapReduce doesn’t perform well with iterative algorithms (e.g., graph analysis)
Spark overcomes that flaw … Supports multipass/iterative algorithms by
reducing/eliminating reads/writes to disk A replacement for MapReduce Three principles of Spark operations:
Resilient Distributed Dataset (RDD): The Data Transformation: Modifies RDD or creates a new RDD Action: analyzes an RDD and returns a single result
Scala is the preferred language for Spark

Part of Apache Hadoop YARN Performance gains Optimal resource management Plan reconfiguration at runtime Dynamic physical data flow decisions

An abstraction build on top of Hadoop Essentially an ETL tool Use “simple” PigLatin script to create ETL jobs Pig will convert jobs to Hadoop M/R jobs Takes away the “pain” of writing Java M/R jobs Can perform joins, summaries, etc. Input/Output all within HDFS Can also write external functions (UDF) and call
them from PigLatin

Allows the use of stdin and stdout (linux) as input and outputs for your M/R jobs
What this means is that you can use C, Python, and other languages
All the internal work (e.g., shuffling) still happens within the Hadoop cluster
Only useful if Java skills are weak

Collection of machine-learning algorithms that run on Hadoop
Possible to write your own algorithms in traditional Java M/R jobs …
… why bother when they exist in Mahout? Algorithms include: k-means clustering,
latent dirichlet allocation, logistic-regression-based classifier, random forest decision tree classifer, etc.

Machine Learning Library (MLLib) for Spark Similar to Mahout, but specifically for Spark (Remember Spark is not MapReduce) Algorithms include: Linear SVM and logistic
regression, k-means clustering, multinomial naïve Bayes, Dimensionality reduction, etc.

Still not fully developed Provides basic authorization in Hadoop Provides role-based authorization Works at the application level (the application
needs to call the APIs) Works with Hive, Solr and Impala Drawback: possible to write M/R job to access
non-authorized data)
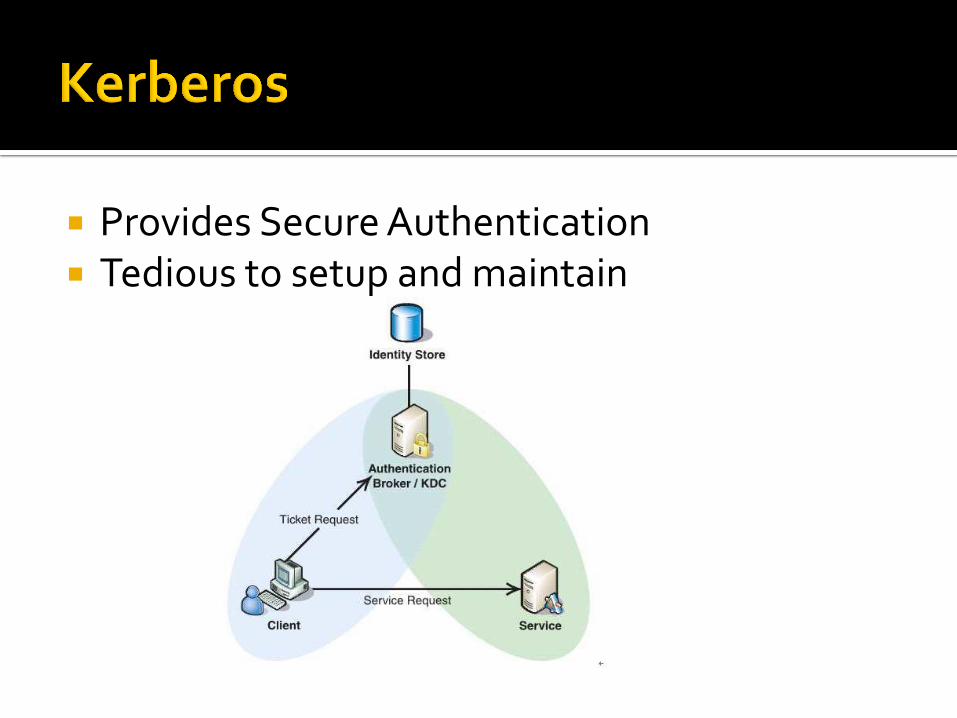
Provides Secure Authentication Tedious to setup and maintain

Security Gateway to manage access History of Hadoop suggests that security was
an afterthought Each tool had own security implementation Knox overcomes that complexity
Provides gateway between external (to Hadoop) apps and internal apps
Authorization, authentication, and auditing
Works with AD and LDAP

Transfers data between HDFS and relation DBs
A very simple command line tool
export data from HDFS to RDBMS
Import data from RDBMS to HDFS
transfers executed as M/R jobs in Hadoop
Filtering possible
Additional options for file formats, delimiters, etc.

Data collection and aggregation Works well with log data Moves large data files from various servers
into Hadoop cluster Supports “complex” multihop flows Key implementation features: source,
channel, sink Job configuration done via a .config file

Data movement between Hadoop clusters Basically it can copy entire cluster Primary Usage:
Moving data from test to dev environments
“Dual Ingestion” using two clusters in case one fails
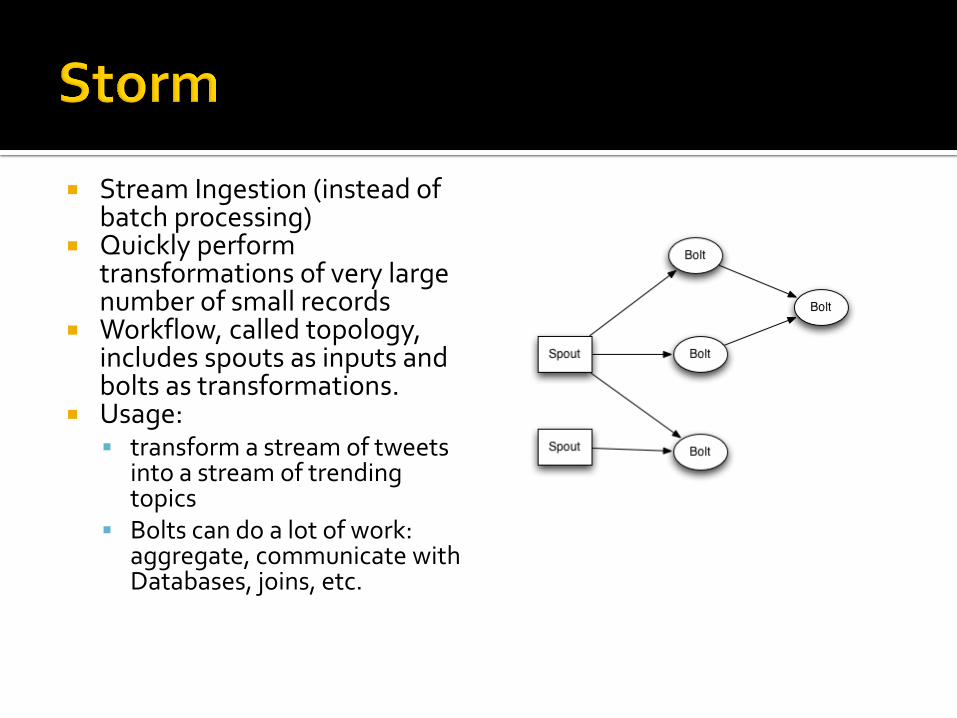
Stream Ingestion (instead of batch processing)
Quickly perform transformations of very large number of small records
Workflow, called topology, includes spouts as inputs and bolts as transformations.
Usage: transform a stream of tweets
into a stream of trending topics
Bolts can do a lot of work: aggregate, communicate with Databases, joins, etc.

A Distributed Messaging framework Fast, scalable, and durable Single cluster can serve as central data
backbone Messages are persisted on disk and replicated
across clusters Uses include: traditional messaging, website
activity tracking, centralized feeds of operational data

Provision, monitoring, and management of a Hadoop cluster
GUI based tool Features
Step by step wizard for installing services
Start, stop, configure services
Dashboard for monitoring health and status
Ganglia for metrics collection
Nagios for system alerts

Another data abstraction layer Use HDFS files as tables Almost SQL-like, but more Hive-like Add partitions Users don’t have to worry about location or
format of data

IT Infrastructure monitoring Web based interface Detection of outages and problems Send alerts via email or SMS Automatic restart provisioning

PUPPET
Node management tool Puppet uses declarative
syntax Configuration file identifies
programs; Puppet determines their availability
Broken down as: Resources, manifests, and modules
CHEF
Node management tool Chef uses imperative
syntax Resource might specify a
certain requirement (a specific directory is needed)
Broken down as: Resources, recipes and cookbooks

Allows coordination between nodes Sharing “small” amounts of state and config
data For example, share connection string Highly scalable and reliable Some built-in protection from using it as a
datastore Use API to extend use to other areas like
implementing security
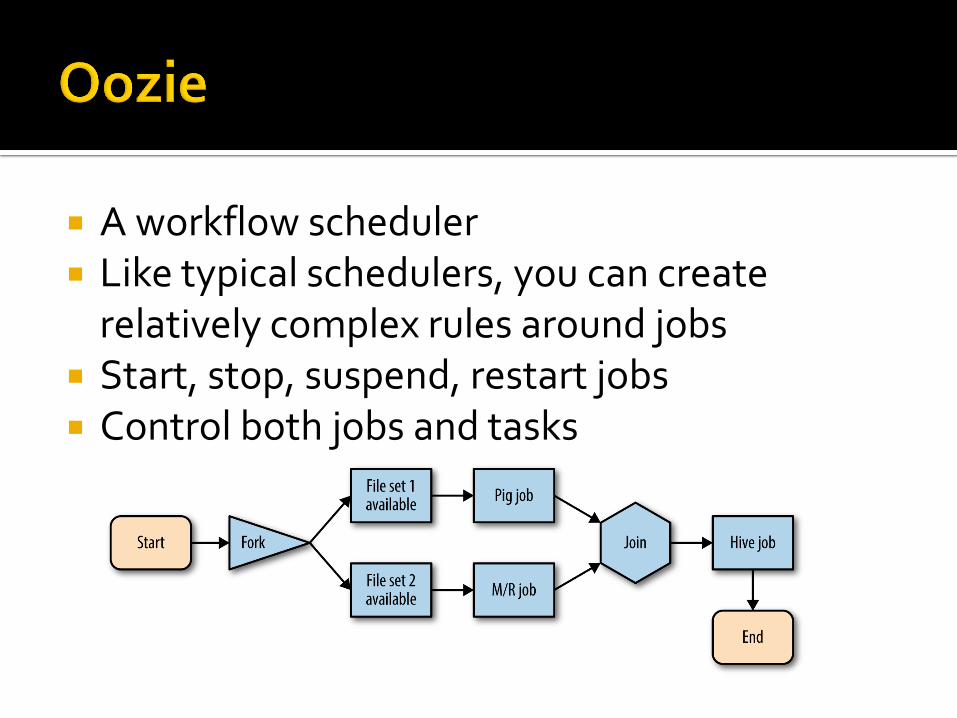
A workflow scheduler Like typical schedulers, you can create
relatively complex rules around jobs Start, stop, suspend, restart jobs Control both jobs and tasks

Another monitoring tool Provides a high-level overview of cluster Computing capability, data transfers, storage
usage Has support for add-ins for additional
features Used within Ambari

Feed management and data processing platform
Feed retention, replications, archival Supports workflows Integration with Hive/Hcatalog Feeds can be any type of data (e.g., Emails)

Key-value store Scales well and efficient storage Distributed database Peer-to-peer system

NoSQL database with random access Excellent for sparse data Behaves like a key-value store
Key + number of bins/columns
Only one datatype: byte string
Concept of column families for similar data Has CLI, but can be access from Java and Pig Not meant for transactional system Limited built-in functionality
Key functions must be added at application level

Name-value db with cell-level security Developed by NSA, but now with Apache Excellent for multitenant storage Set column visibility rules for user “labels” Scales well, at petabytes of data Retrieval operations in seconds

In-memory cache Fast access of large data for short time Traditional approach to sharing data in HDFS
is to use replicated join (send data to each node)
Memcached provides a “pool” of memory across the nodes and stores data in that pool
Effectively a distributed memory pool Much more efficient than replicating data

Document Warehouse Allows searching of text documents Blur uses HDFS stack; Solr doesn’t Uses can query data based on indexing

JSON document-oriented database Most popular NoSQL db Supports secondary indexes Does not run on Hadoop Stack Concept of documents (rows) and collections
(tables) Very scalable … extends simple key-value
storage

Interact directly with HDFS data using HQL HQL similar to SQL (syntax and commands) HQL queries converted to M/R jobs HQL does not support:
Updates/Deletes
Transactions
Non-equality joins

SQL Access to Hadoop Data In-memory model for execution (like Spark) No MapReduce functionality Much faster than traditional HDFS access Supports HQL; also support for Java, Scala
APIs Can also run MLLib algorithms

A Graph database (think extended relationships) Facebook, LinkedIn, Twitter, etc. use graphs to
determine your friends and likely friends The science of graph theory is a bit complicated If John is a friend of Mary; Mary is a friend of
Tom; Tom is a friend of Alice … Find friends who are two paths (degrees) from
John; nightmare to do with SQL Finding relationships from email exchanges

Relational database layer over HBASE Provides JDBC driver to access data SQL query converted into HBase scans Produces regular JDBC resultsets Versioning support to ensure correct schema
is used Good performance






























