Embed Size (px)
Citation preview

Detecting Multiple Aliases in Social Media
Amendra Shrestha, Lisa Kaati, Fredrik Johansson
26th August

Overview
• Introduction • Reasons for multiple aliases
• Techniques for detecting aliases • Dataset • Experiment and Results
• Conclusion and Future work

Motivation
1. A. Y. Zelin and R. B. Fellow, “The state of global jihad online,” New America Foundation, 2013. 2. J. Brynielsson, A. Horndahl, F. Johansson, L. Kaati, C. Mårtenson, and P. Svenson, “Harvesting and analysis of weak signals for detecting lone wolf terrorists,” Security Informatics, 2013, 2:11. 3. http://www.businessinsider.com/facebook-‐fake-‐likes-‐and-‐accounts-‐2012-‐12
[1]
[3]
[2]
terrorists make extensive use of social media / discussion

Problems
• changing IP address and URLs frequently • use of anonymization techniques like Onion Routing and Crowds

Our Objective
• Develop methods for detecting users with multiple aliases

Use of multiple aliases

Bizhant Pokheral
Use of multiple aliases

Bizhant Pokheral
Use of multiple aliases

Cases for multiple aliases
• Case I : Alter Ego Aliases • concealed case
• Case II : Multiple Aliases
• non-‐concealed case

• Case – I : Alter ego aliases • banned by administrator
• lost trust of the group
• developed bad personal relationships
• to support his arguments
• privacy reasons
• Case – II : Multiple aliases • banned by administrator
• banned for inactivity
• forgotten password
• alias name is already used
Possible reasons for multiple aliases

Assumptions • Case I : Alter ego aliases
• doesn’t have same friend network
• write in at least one common thread
• no name equality
• similar time profile
• similarity in writing style
• Case II: Multiple aliases • has similar friend network
• doesn’t write in same thread
• equality in name
• similar time profile
• similarity in writing style

Techniques for detecting aliases
• String-‐based matching
• Time profile-‐based matching
• Stylometric matching
• Social network-‐based matching

String based matching • Based on aliases name
• For multiple aliases case
• Edit distance measures • implemented Jaro-‐Winkler distance [1]
1. W. E. Winkler, “String comparator metrics and enhanced decision rules in the Fellegi-‐Sunter model of record linkage,” in Proceedings of the Section on Survey Research Methods, 1990, pp. 354–359.
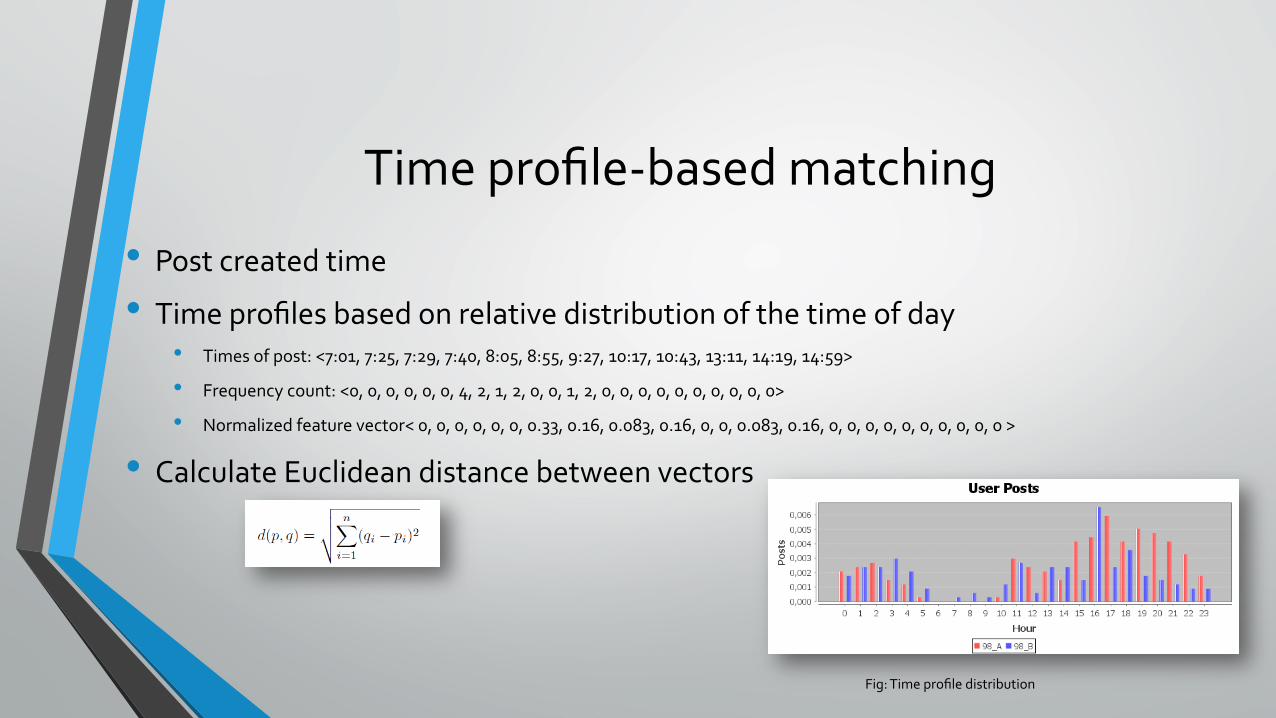
Time profile-‐based matching
• Post created time
• Time profiles based on relative distribution of the time of day • Times of post: <7:01, 7:25, 7:29, 7:40, 8:05, 8:55, 9:27, 10:17, 10:43, 13:11, 14:19, 14:59>
• Frequency count: <0, 0, 0, 0, 0, 0, 4, 2, 1, 2, 0, 0, 1, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0>
• Normalized feature vector< 0, 0, 0, 0, 0, 0, 0.33, 0.16, 0.083, 0.16, 0, 0, 0.083, 0.16, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 >
• Calculate Euclidean distance between vectors
Fig: Time profile distribution

Stylometric matching • Everyone has unique writing style
• Statistical analysis of writing style
• “writeprint”
• Calculate cosine of angle between feature vectors
where 𝑝↓𝑖 and 𝑞↓𝑖 are feature vector of aliases p and q respectively
1. A. Narayanan, H. Paskov, N. Gong, J. Bethencourt, E. Stefanov, E. Shin, and D. Song, “On the feasibility of internet-‐scale author identification,” in 2012 IEEE Symposium on Security and Privacy (SP), may 2012, pp. 300 –314.
1

Social network-‐based matching • Friend Equality
• friend network
• number of common friends
• Thread Equality (Discussion Boards) • thread network
• communication patterns
• Jaccard similarity coefficient
Fig. 1. Example of time profiles for two individuals.
TABLE ITHE FEATURES USED FOR STYLOMETRIC MATCHING (THE LIST OF
FUNCTION WORDS USED CAN BE FOUND IN [12]).
Category Description Count
Word length Frequency of words with 1-20 characters 20Sentence length Frequency of sentences with various lengths 6
Letters Frequency of a to z (ignoring case) 26Digits Frequency of 0 to 9 10
Punctuation Frequency of characters . ? ! , ; : ( ) ” - ´ 11Function words Frequency of various function words 293
and decision trees. Such algorithms can be used for learningclassifiers to generalize from training data in order to makegood classifications on (previously unseen) test data, but arein general not appropriate for determining how similar thewriteprints of two aliases are. We are therefore using themore basic approach to compare how similar the (normalized)stylometric feature vectors are for two aliases by simplycalculating the cosine of the angle between them:
cos(p, q) =p · q
kpkkqk =
Pni=1 pi ⇥ qipPn
i=1 (pi)2 ⇥
pPni=1 (qi)
2(2)
There are many other ways that also could be used to com-pare the similiarity between two stylometric feature vectors,but the use of cosine similarity is straightforward to implementand seems to work out well, as shown in our experiments.
4) Social-network based matching: The last type of match-ing technique we have implemented is what we have chosento refer to as social-network based matching. The underlyingidea of this is that a mapping and comparison of the socialnetwork of two aliases can reveal if those aliases are similar inthe sense of whom they are connected to. The social networkcan be based on various information, depending on what thediscussion forum look like. On some forums (such as theforums we have used in our experiments), there are friendor ”buddy” lists available, in which the user can mark otherusers as friends. On many forums such friend lists are lacking,but also other kinds of information can be used to create
social networks, such as thread networks (connecting userswho have made postings in the same thread) or topic networks(connecting users who have written about the same topic). Inorder to create topic networks, it is necessary to first extractthe topics from the posts. This can be done with varioustopic detection and topic extraction methods such as the onespresented in [24], but is outside the scope of this paper.
To illustrate how social-network based matching can beused, consider the alter ego case discussed in Section III. Forthis case, it makes sense to measure how similar the threadnetworks are for two aliases when trying to determine if thealiases belong to the same user or not. In general, it is likelythat both aliases will make postings in the same thread if theyare alter egos, since the reason for creating an alter ego orsockpuppet often is to support one’s own arguments.
No matter if the constructed social network is based onfriend-, thread- or topic information, we use vertex similarityto calculate how similar two aliases are in terms of their socialnetwork. The vertex similarity can be calculated as a functionof the number of neighbors in common for two aliases. If thetotal number of neighbors should not impact the results toomuch, a normalization process in which the node degrees aretaken into account is needed. Let �p be the neighborhood ofvertex (alias) p in the network and �q be the neighborhoodof vertex (alias) q. Now, the number of common neighborsis calculated as |�p \ �q|. The normalization can be donein various ways (such as with dice or cosine similarity), butin our implementation we make use of the Jaccard similaritycoefficient J(p, q), where:
J(p, q) =|�p \ �q||�p [ �q|.
(3)
In Figure 2 we illustrate the ego networks of aliases A andC, where they have two neighbors in common (E and F).
B. Matching of aliasesIn the previous section we have described a number of
matching techniques, where each classifier outputs a similaritybetween two aliases. Which classifiers to include depends onthe task at hand, e.g., if we are dealing with a concealed or
Fig: Friend Network

Matching of aliases • Multiple aliases
• all above techniques
• Alter ego • all except string-‐based technique
• Combination of techniques
• depending upon size of dataset
• all at once • one at a time
• Average of the results of the matching techniques

Dataset • Irish discussion forum boards.ie data
• SIOC format
• Available data • 10 years data
• 50 gigabytes of disk space
• 9 million documents
• Used data • 2008 year data
• 995 megabytes in size
• forums, threads, posts, users and FOAF documents
• more than 1200 users (posted more than 60 messages)
• 220K posts

Experiment
Experiment Result
User 1 User 2 Stylo (Rank) Time (Rank) Fusion
1_A 1_B 1 1 1
3_B 2 2 2
2_B 3 3 3
. . . .
. . . .
4_B . . .
N_B N N N
1
1_A 1_B
2 3 4 N
1_A 1_B 2_B 3_B 4_B N_B
2_A 2_B

Result
0%
20%
40%
60%
80%
100%
50
100
150
200
250
300
350
400
450
500
550
600
650
700
750
800
850
900
950
1000
ACC
URA
CY
NUMBER OF USERS
TOP-‐3
Time+Stylometry Time Stylometry
0%
20%
40%
60%
80%
100%
50
100
150
200
250
300
350
400
450
500
550
600
650
700
750
800
850
900
950
1000
ACC
URA
CY
NUMBER OF USERS
TOP-‐1
Time+Stylometry Time Stylometry

Conclusion
• Presented 4 different types of techniques • Implemented matching techniques
• Experiments using time and stylometric
• Time gives better results than stylometric
• Combining the results of each matching technique gives better results

Future Work
• This is just the beginning • Maximize test result percentage
• Fusion of techniques • Test on big dataset

Questions



![Detecting Carbon Monoxide Poisoning Detecting Carbon ...2].pdf · Detecting Carbon Monoxide Poisoning Detecting Carbon Monoxide Poisoning. Detecting Carbon Monoxide Poisoning C arbon](https://img.dokumen.tips/doc/110x75/5f551747b859172cd56bb119/detecting-carbon-monoxide-poisoning-detecting-carbon-2pdf-detecting-carbon.jpg)

























![et al. Deep Learning for Detecting Multiple Space-Time ...arXiv:1608.01529v1 [cs.CV] 4 Aug 2016 SAHAet al.: DEEP LEARNING FOR DETECTING SPACE-TIME ACTION TUBES 1 Deep Learning for](https://img.dokumen.tips/doc/110x75/60bd9f25b41f7b02951d88cc/et-al-deep-learning-for-detecting-multiple-space-time-arxiv160801529v1-cscv.jpg)