Embed Size (px)
Citation preview

★ Introducing ARCOMEM
★ Harvesting the web
★ Analysing the content of the web
★ The ARCOMEM architecture
Tuesday, 12 March 13

INTRODUCING
Tuesday, 12 March 13

GOALS
• Intelligently harvest data from the web and social web around specific ETOEs.
• Provide a scalable and extensible platform for analysis taking into account all modalities of data.
• Expose the results of the analysis in the form of semantic knowledge.
• Export the data in standardised formats for preservation and exchange.
Tuesday, 12 March 13

USERS
Tuesday, 12 March 13

Tuesday, 12 March 13

INTELLIGENTLY HARVESTING
THE WEBTuesday, 12 March 13

WEB CRAWLING 101
Tuesday, 12 March 13

The WebTuesday, 12 March 13

Crawl SeedsTuesday, 12 March 13

OutlinksTuesday, 12 March 13

FrontierTuesday, 12 March 13

FrontierTuesday, 12 March 13

FrontierTuesday, 12 March 13

AVOIDING FRONTIER
EXPLOSION
Common Techniques: Domain-specific crawlingHop limiting
Tuesday, 12 March 13

CRAWLING IN ARCOMEM
• A standard crawler relies on having good seeds
• Only very crude constraints to keep crawl on target.
• Crawl engineers manually manipulate the frontier!
• ARCOMEM has developed techniques to help create a crawl that remains on-topic automatically.
Tuesday, 12 March 13

API-DIRECTED CRAWLING• Crawl domain is specified as keywords, not seeds.
• Keywords are fed an API-Crawler, which performs continuous searches for user generated posts and/or standard web-search results.
• twitter, facebook, google-plus, youtube, google search, etc
• Outlinks in the posts are sent to the web-crawler as seeds.
• The posts are archived as part of the crawl.
• Standard constraints are used to control how far the web-crawler navigates from the seeds.
Tuesday, 12 March 13

INTELLIGENT CRAWLING• User defines the crawl domain in terms of an Intelligent
Crawl Specification (ICS)• Keywords, seed URLs, and ETOEs.
• The web-crawler is modified so that its frontier is held as a priority queue rather than a list.
• Standard and/or API crawls are started using the seeds and keywords.
• Every crawled resource is scored against the ICS.• The score is combined with contextual information to
score each outlink which is then added to the queue.Tuesday, 12 March 13

ANALYSING THE WEB
Tuesday, 12 March 13

POST-CRAWL ANALYSISTuesday, 12 March 13

THE ARCOMEM ONTOLOGYTuesday, 12 March 13

MULTIMEDIA ANALYSIS
Tuesday, 12 March 13

MULTIMEDIA ANALYSIS• Numerous multimedia algorithms integrated into the
ARCOMEM framework
• Robust to web imagery – there is a lot of non-standard content out there!
• Specific algorithms include: Locality Sensitive Hashing for scalable detect near-duplicates, audio transcription, audio classification, video labelling, etc.
• Specific focus on scalability
Hare, Jonathon., Samangooei, Sina and Lewis, Paul. (2012) Practical scalable image analysis and indexing using Hadoop. Multimedia Tools and Applications, 1-34.
Tuesday, 12 March 13

MULTIMEDIA ETOES• Detection & recognition of people
• face recognition pipeline
• detection, alignment, feature-extraction, recognition
• Implementation of a 2.5D CLM Face Model for expression analysis & alignment for recognition.
• Improved detection of locations from images
• Working at reasonable speed on really big datasets:
• Two forms of content-based image search tested with 46M image dataset (~5.4TB); one technique is able to hold entire image feature index in ~800M memory!
Hare, Jonathon., Samangooei, Sina., Dupplaw, David, and Lewis, Paul H. (2012) ImageTerrier : an extensible platform for scalable high-performance image retrieval. At ACM ICMR'12, Hong Kong, HK.
Tuesday, 12 March 13

NEAR-DUPLICATE IMAGE DETECTION
Tuesday, 12 March 13

DUPLICATE DETECTION•Detection of near-duplicate multimedia artifacts provides a
means to investigate and explore many facets about the documents the media is embedded within.
• Some examples include:
•Aggregating documents about the same subject/event/opinion
•Finding cases where media is used in differing contexts is also interesting.
•Exploring how different social groups talk about the same media
Tuesday, 12 March 13

Tuesday, 12 March 13

US-ELECTIONS CRAWL EXAMPLES
Tuesday, 12 March 13

122 Detected Duplicates https://sphotos-a.xx.fbcdn.net/hphotos-ash3/63089_10151299959267177_1113898282_n.jpg http://p.twimg.com/A7Oq4JRCEAA05uG.jpg https://p.twimg.com/A7RMKgrCIAAvPdj.jpg http://24.media.tumblr.com/tumblr_md4ttulK8d1qa5ex8o1_500.jpg https://p.twimg.com/A7Oq4JRCEAA05uG.jpg https://p.twimg.com/A7JYdoDCEAAktAb.jpg https://p.twimg.com/A7JIdp7CcAAjsPF.jpg http://p.twimg.com/A7JSUYCCUAEzW5O.jpg http://p.twimg.com/A7NoTNOCIAEQ3ie.jpg https://p.twimg.com/A7LsnVrCQAAWYFA.jpg ...
112 Detected Duplicates http://25.media.tumblr.com/tumblr_mc0mmx2kTA1rxxq3ro1_500.png http://p.twimg.com/A7Ep0CjCMAAon-f.jpg http://p.twimg.com/A7N3lxrCAAE_gzP.jpg https://p.twimg.com/A5ctYtVCMAE8_8e.jpg http://p.twimg.com/A7NMvVACUAEL9aa.jpg http://p.twimg.com/A7EkZK8CEAE0pYu.jpg https://p.twimg.com/A7FOSwtCUAADws1.jpg http://p.twimg.com/A7EiFd4CcAAZdT1.jpg http://p.twimg.com/A7JwHHbCQAAvqNN.jpg ...
Tuesday, 12 March 13

103 Detected Duplicates https://p.twimg.com/A7K8WWiCAAE9Uap.png https://p.twimg.com/A7Iq1DSCQAAyRBG.jpg http://p.twimg.com/A7L7bQJCIAIaaqm.jpg http://p.twimg.com/A7KSC5gCcAAcLTj.jpg https://p.twimg.com/A7OqzarCYAA8L9N.jpg https://p.twimg.com/A7OlKn-CQAA-j7X.jpg https://p.twimg.com/A7J5CHPCUAEp-86.png https://p.twimg.com/A7JOd9kCcAIy3YM.jpg http://25.media.tumblr.com/tumblr_lyr1v4kp8J1qcjsjlo1_500.jpg ...
106 Detected Duplicates https://p.twimg.com/A7MQiKeCMAE1rmX.jpg https://p.twimg.com/A7IFNt_CUAAqYFV.jpg https://p.twimg.com/A7DrPLMCIAAoKb8.jpg http://p.twimg.com/A7Y5BW9CQAAqF3E.jpg https://p.twimg.com/A2YzbudCQAE77pr.jpg https://p.twimg.com/A7FQF7PCUAAgWWH.jpg https://p.twimg.com/A7EO5YFCMAAMTxB.jpg http://p.twimg.com/A7IWHTtCUAIAtH8.jpg http://p.twimg.com/A7FcyZdCUAAO_Vg.jpg http://25.media.tumblr.com/tumblr_m7c9nivzwF1qfep67o1_500.jpg ...
Tuesday, 12 March 13

Tuesday, 12 March 13

TWITTER’S VISUAL PULSEHare, Jonathon., Samangooei, Sina., Dupplaw, David and Lewis, Paul. (2013) Twitter’s Visual Pulse. Accepted to appear in ACM
International Conference on Multimedia Retrieval (ICMR’13), Dallas, Texas, USA.
Tuesday, 12 March 13

Tuesday, 12 March 13

Tuesday, 12 March 13

Tuesday, 12 March 13

MULTIMEDIA OPINION MINING
• Investigate the use of facial analysis to classify facial expressions in images and videos found on the web.
• Can be used to indicate emotion of subject.
• Investigate course-grained automatic classification using image features
• For abstract opinion-related concepts (sentiment/privacy/attractiveness)
• Investigate correlations between images and opinions mined from text
• Does the same image get reused in different documents to illustrate the same (or different) opinion?
Tuesday, 12 March 13

SENTIMENT/PRIVACY/ATTRACTIVENESS
S. Zerr, S. Siersdorfer and J. Hare. PicAlert!: a system for privacy-aware image classification and retrieval. In, 21st ACM Conference on Information and Knowledge Management (CIKM 2012), Maui, Hawaii, United States, 29 Oct - 02 Nov 2012.
S. Zerr, S. Siersdorfer and J. Hare and E. Demidova. I know what you did last summer! - privacy-aware image classification and search. SIGIR '12, Portland, US, 12 - 16 Aug 2012.
Siersdorfer, S., Hare, J., Minack, E. and Deng, F. (2010) Analyzing and Predicting Sentiment of Images on the Social Web. At ACM Multimedia 2010, Firenze, Italy, 25 - 29 Oct 2010. ACM, 715-718.
Figure 3: Private and public search results for the query “cristiano ronaldo” (June 06 2012).
2.4 SearchIn order to create a list of images ranked by privacy, we
estimated the likelihood of image privacy using the outputof the SVM classifier trained on a set of images labeled as“public” or “private” by the users. We use the Flickr APIas the underlying search provider for our PicAlert! searchservice. The user interface of the application simply consistsof a text box and a keyword search can be performed press-ing the “Search” button. The di↵erence to other engines ismainly in the search result representation. PicAlert! dividesthe results into two sets: “public” and “private”. Addition-ally, each set is divided into three subsets according to theclassifier confidence intervals and is denoted by color. Thegreen color corresponds to a strong classifier confidence, yel-low to moderate and red to a weak confidence. Figure ??shows an example for the results representation for the query“christiano ronaldo”. In the left (“public”) part we observethat the majority of pictures are related to sporting events,whilst the right (“private”) part is mostly dominated by pho-tos about Ronaldo’s private life.
2.5 Classification GUIThe HTML based graphical user interface of the PicAlert!
web service enables the user to submit images to the webservice, and to obtain an estimate of the degree of privacyalong with a visual explanation. The GUI consists of twomain components - the image input page and the user settingpage. The setting page allows users to obtain and to manageauthorization keys for the web service client. The input pageprovides the following image input options:
• Direct Image URL: The service downloads the imageavailable under the given URL. This image can be ad-ditionally supplied with title and tags.
• Flickr Image URL: The service downloads the imagefrom the given Flickr URL. The service will also ex-tract image title and tags if available.
• Image Upload: The user can upload an image directlyfrom her desktop. Adding title and tags are optional.
The result page shown in Figure ?? appears after submit-ting the required data. The page contains the estimation ofthe image privacy value as the textual recommendation forthe user to share the image or not. Additionally the featuresused for classification can be analyzed in more detail. Tablescontaining the most influential visual features are providedat the bottom of the page. If the user moves the mousepointer over a particular feature name in the table, the cor-responding feature is visualized within the image. The mostdiscriminative image tags are also selected and presented tothe user as a possible explanation for the classifier decision.Whilst the GUI currently only allows for the processing asingle image at a time, batch image handling is possiblethrough our XML web service interface.
3. SYSTEM EVALUATION
3.1 Classification QualityIn order to evaluate our classification approach, from the
initial dataset we randomly sampled 60% as training datafor building our classifiers, and 40% as test data, with eachdata set containing an equal proportion of public and privateinstances. Our quality measures for the classification are theprecision-recall curves as well as the precision-recall break-even points for these curves. The break-even point (BEP) isequal to the F1 measure and the harmonic mean of precisionand recall. The results of the classification experiments for
PicAlert!: A System for Privacy-Aware Image Classification
and Retrieval
Sergej Zerr*, Stefan Siersdorfer*, Jonathon Hare**
*L3S Research Center, Hannover, Germany{zerr,siersdorfer}@L3S.de
**Electronics and Computer Science, University of Southampton, Southampton, [email protected]
ABSTRACTPhoto publishing in Social Networks and other Web2.0 ap-plications has become very popular due to the pervasiveavailability of cheap digital cameras, powerful batch uploadtools and a huge amount of storage space. A portion ofuploaded images are of a highly sensitive nature, disclosingmany details of the users’ private life. We have developed aweb service which can detect private images within a user’sphoto stream and provide support in making privacy de-cisions in the sharing context. In addition, we present aprivacy-oriented image search application which automati-cally identifies potentially sensitive images in the result setand separates them from the remaining pictures.
1. INTRODUCTIONWith increasing availability of content sharing environ-
ments such as Flickr, and YouTube, the volume of privatemultimedia resources publicly available on the Web has dras-tically increased. In particular young users often share pri-vate images about themselves, their friends and classmateswithout being aware of the consequences such footage mayhave for their future lives [?, ?]. Users of photo sharing sitesoften lack awareness of privacy issues. Our recent study [?]revealed that up to 20% of publicly shared photos on Flickrare of sensitive nature. Existing sharing platforms often em-ploy rather lax default privacy configurations, and requireusers to manually decide on privacy settings for each singleresource. Given the amount of shared information, this pro-cess can be tedious and error-prone. This is especially truefor large batch photos uploads. Furthermore, image searchengines do not provide the possibility to directly search forprivate images which might already be available on the web.
In this work we demonstrate the PicAlert! privacy-orientedimage search application. PicAlert! is able to identify andisolate images in a Flickr result set that are potentially sen-sitive with respect to user privacy. The application is basedon a web service that automatically identifies a privacy de-gree of an image through classification of the content and
Permission to make digital or hard copies of all or part of this work forpersonal or classroom use is granted without fee provided that copies arenot made or distributed for profit or commercial advantage and that copiesbear this notice and the full citation on the first page. To copy otherwise, torepublish, to post on servers or to redistribute to lists, requires prior specificpermission and/or a fee.CIKM ’12 Maui, Hawaii USACopyright 20XX ACM X-XXXXX-XX-X/XX/XX ...$15.00.
Figure 1: System architecture overview.
context of the image. It could be directly integrated intosocial photo sharing applications like Flickr or Facebook, orinto browser plugins in order to support users in makingadequate privacy decisions in image sharing. Thus, the ap-plication illustrated in the demo is two-fold: warning theuser about uploading potentially sensitive content on theone hand (cf. Figure ??) and privacy-oriented search on theother hand (cf. Figure ??).We are aware that building alarm systems for private con-
tent and enabling privacy-oriented search can be seen ascontradicting goals; privacy-oriented search is not negativeper-se, as it can be used for retrieving private content usersare comfortable to share, and, more importantly, can helpwith the early discovery of privacy breaches. However, aswith almost every technology, it requires sensible handlingand constructive usage.
2. SYSTEM ARCHITECTUREThis section describes the main components of the Pi-
cAlert! system. The system architecture is illustrated inFigure ??. Firstly, through crowd-sourcing, we build a train-ing set of private and public images. In the next step we ex-tract visual, and, if available, textual features which providehints for the privacy degree of an image. We then train aSVM classifier which is used by our Search and Alert systemfor identifying potentially sensitive visual content. Finally,the user can access the application from arbitrary clientsincluding desktops and mobile devices. In the following weprovide a brief overview of the system components and showhow results are presented to the user. A fully detailed de-scription of the underlying scientific approach can be foundin our recent work [?].
Pos
itiv
e
GC
H
Neg
ativ
ePos
itiv
e
LC
H
Neg
ativ
ePos
itiv
e
SIF
T
Neg
ativ
e
Figure 4: Images classified as positive and negative based on the three features: GCH, LCH, and SIFT
discover image features that are most correlated with sen-timents. For each feature, we computed the MI value withrespect to the both positive and negative sentiment cate-gory. Figure 3 illustrates the 16 most discriminative visualfeatures based on their MI value for the positive and nega-tive categories (in rank order; top-to-bottom). Overall, theselected features mirror the features we inferred for the sam-ple of classified images described in the previous section.
The GCH features for positive sentiment are dominatedby earthy colors and skin tones. Conversely, the features fornegative sentiment are dominated by blue and green tones.Interestingly, this association can intuitively be hypothe-sized because it mirrors human perception of warm (posi-tive) and cold (negative) colors. The LCH features showthe same trend as the GCH features — blue tones associ-ated with negative sentiment, and skin tones associated withpositive sentiment. In addition, the LCH features indicatethat there is no bias to the spatial location in which pixels ofthe respective colors occur for positive sentiment. Negative
features appear to be biased away from the far right of theimage plane.
As mentioned in the previous section, results based onSIFT visual terms are di⇥cult to interpret directly, but wecan make some general observations. Looking at the mostdiscriminative SIFT visual term features, the first obser-vation is that the features within the two classes are re-markably similar, but there is a clear di�erence between theclasses. The negative features seem dominated by a verylight central blob surrounded by a much darker background.The positive features are dominated by a dark blob on theside of the patch (the patches have been normalized for ro-tation, so the dark blob could occur in any orientation inthe image).
In order to explore the SIFT visual terms from a di�erentperspective, Figure 5 illustrates the top positive and nega-tive visual terms (from the MI analysis) in the context of twoimages (one classified as“positive”and the other“negative”).The first observation is that the positive image has more
ImageTags
Image Features
SVM
Sentiment Valueextract training
extract training
Tuesday, 12 March 13

IMAGE-OPINION CORRELATIONImage-opinion correlation is almost at the stage where we can explore ARCOMEM crawls by posing SPARQL queries to find
opinions from documents with duplicate images.
+ve -ve
Tuesday, 12 March 13

TOWARDS FACIAL ANALYSIS IN THE WILD
•Detection and analysis of faces in multimedia content can help us guide and contextualise a crawl:
• Recognition and expression analysis can help us determine if an image is relevant or interesting.
• Post-crawl the information can be used for visualisation.
•Current research very much based on images taken in lab-conditions; how far can we take it?
Tuesday, 12 March 13

FACIAL EXPRESSION MODELS
•Facial expression pipeline using a “Constrained Local Model”.
•These are parametric models of pose and facial shape (i.e. expression).
•The parameters for the model form an excellent way of describing expression.
Tuesday, 12 March 13

Tuesday, 12 March 13

Tuesday, 12 March 13

Tuesday, 12 March 13

APPLYING THE MODEL TO CRAWLED IMAGES
Tuesday, 12 March 13

ARCHITECTURE
Tuesday, 12 March 13

SCALABLE FROM THE GROUND UP
• ARCOMEM is dealing with small to medium scale crawls
• 10s of GB to multi-terabyte data
• Both the crawlers and analysis platform need to be distributed and scalable.
• Hadoop and HBase for scalable, distributed storage and Map-Reduce style analysis.
• H2RDF triple storeTuesday, 12 March 13

EXAMPLE CRAWLSFinancial Crisis crawl
Web-Crawl82K DNS Requests1.5M HTML Pages
700K Images80 Videos30K Flash
US Elections crawl
55GB Compressed Data6.8M unique resources
585GB Compressed Data7.5M unique resources
Standard and API-Directed Crawl (web-search)
API-Directed Crawl (social)
API-Crawl3.7M Tweets
64K YouTube posts34K FaceBook Posts
Web-Crawl43K DNS Requests1.5M HTML Pages
2.3M Images3.7K Videos 60K Flash
API-Crawl1372 Tweets
5.5M search hits
Tuesday, 12 March 13

Tuesday, 12 March 13

Web Crawler
API Crawler
Queue
Online Analysis
HBase
H2RDF
Crawler CockpitICS
Offline Analysis
MODULAR
Tuesday, 12 March 13

Web Crawler
API Crawler
Online Analysis
HBaseOffline Analysis
LOOSELY-COUPLED FOR INTEROPERABILITY &
REUSABILITY
WARC
Tuesday, 12 March 13

INTEROPERABILITY, PRESERVATION & PROVENANCE
• ARCOMEM is designed to interoperate with other systems.
• i.e. wayback-machine
• Data can exported for interchange and long-term preservation
• WARC & triples
• Provenance of the crawl is captured in the triples
Tuesday, 12 March 13

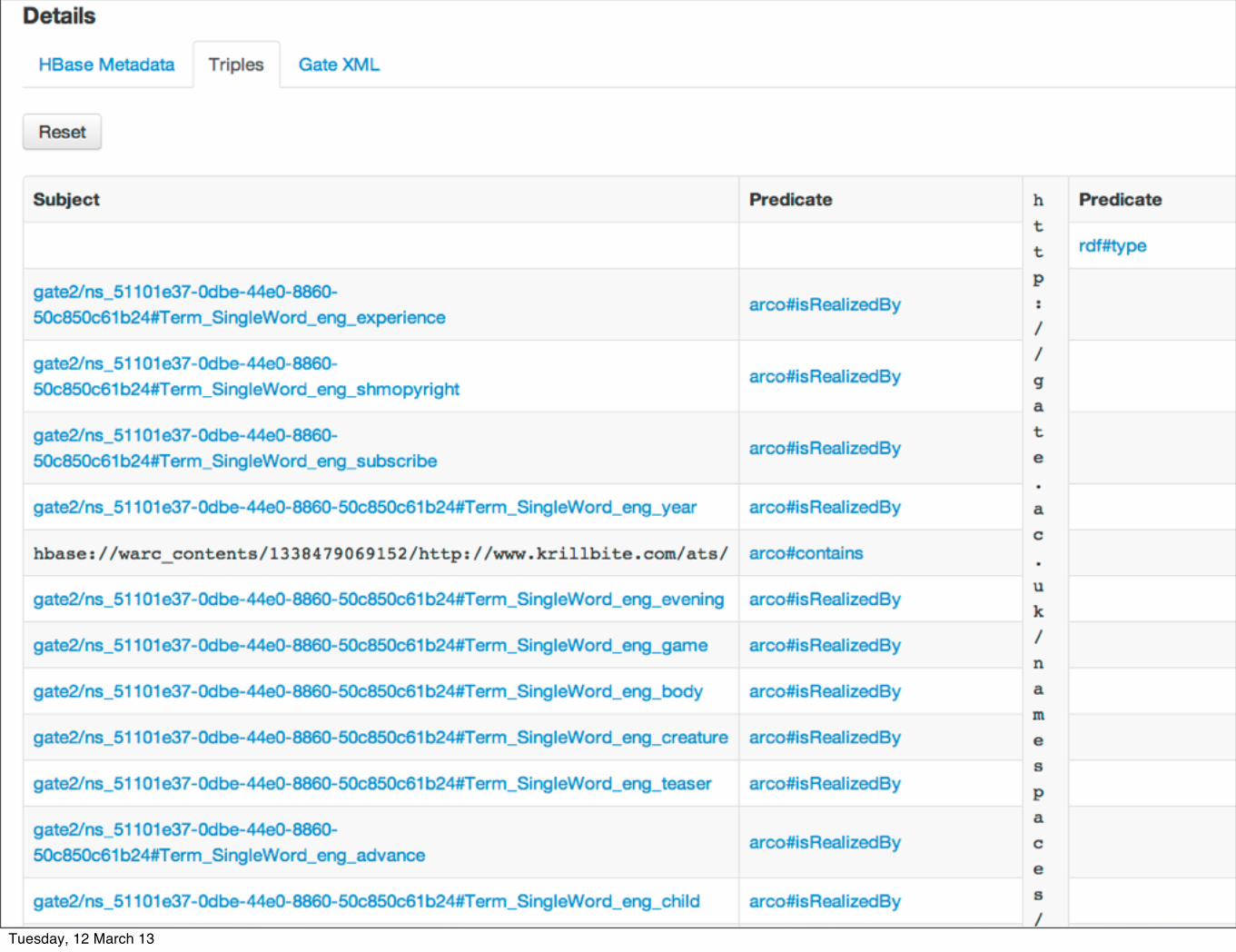
THE INSPECTOR
• Sometimes you just want to look at the raw data and the results of the analysis.
• The ARCOMEM inspector is a tool for developers to observe and inspect what has been crawled and analysed.
Tuesday, 12 March 13

URI of the crawled resource
Versions of the resource
Metadata and analysis Content Preview
Tuesday, 12 March 13

Tuesday, 12 March 13
Tuesday, 12 March 13

SUMMARY
• In ARCOMEM we are developing tools for harvesting and analysing the web in all its forms.
• Functionally what we have built goes a large way towards being a true multimedia web observatory that can help fulfill the diverse requirements of many types of user.
• The analysis of multimedia content facilitates enhanced interlinking and understanding of the content of the web that text-analysis alone cannot provide.
Tuesday, 12 March 13